“The agent loop is 10 lines of code. Agent engineering is 100,000 lines of code.”
The first time I read that, I paused — and the more I sat with it, the sharper it cut. It punctures the single biggest illusion in this whole field: people think building an agent means writing a good prompt and wiring up an LLM API. But the actual work of pushing a demo to production — of running safely, unattended, all night long — is 99% not in that loop.
This article does one thing: it treats Agent Engineering as a discipline, not a tutorial. I won’t teach you how to use LangGraph. I want to hand you a map — which eight pillars this discipline is built on, what gap each one fills that the previous one left open, what its minimal implementation looks like, and when it fails. Once you have the map, you can look at any agent framework or any vendor’s engineering blog and immediately locate it on the terrain.
Half the material comes from the pits I keep falling into building agent systems myself; the other half comes from what the frontline teams at Anthropic, OpenAI, Cognition, Manus, and Temporal published over 2025 and 2026. I’ll cite sources as carefully as I can — because in this field, misattributed “facts” travel faster than the truth, and we’re about to hit the first one immediately.
1. The Number Everyone Cites: 98.4%
Let’s start with a number that has spread far and wide, because it’s the title of this piece and the best opening line the field has.
In 2026 a paper reverse-engineering Claude Code, “Dive into Claude Code” (VILA-Lab, arXiv: 2604.14228), analyzed Claude Code v2.1.88 — roughly 1,900 TypeScript files and 512K lines of code. Its abstract contains a passage I’ll quote verbatim:
“The core of the system is a simple while-loop that calls the model, runs tools, and repeats. Most of the code, however, lives in the systems around this loop: a permission system with seven modes and an ML-based classifier, a five-layer compaction pipeline for context management, four extensibility mechanisms (MCP, plugins, skills, and hooks), a subagent delegation mechanism with worktree isolation, and append-oriented session storage.”
Note an important correction here: the famous precise figure — “1.6% is AI decision logic, 98.4% is infrastructure” — is not in the paper’s abstract. It’s a rendering from secondhand summaries. And plenty of people online attribute it to the minusx blog, or to a “UCL team reverse-engineering leaked source.” Both attributions are wrong. minusx’s “Decoding Claude Code” is a great piece, but it contains no percentages at all; and the paper isn’t based on leaked source — it analyzes public TypeScript.
So my advice: use 98.4% as a narrative frame, not a precise metric. It’s a line-count estimate of the fuzzy category “AI decision logic,” a judgment call by the authors, not a hard measurement. But even after all those discounts, the thing it’s pointing at still holds, and it’s enormously important:
The bulk of the engineering in a production-grade agent isn’t in the prompt or the model call — it’s in that ring of infrastructure outside the model. The industry has a name for that ring: the harness.
OpenAI uses the word too. Their January 2026 piece dissecting Codex is literally titled “Unrolling the Codex agent loop,” and it opens by saying: “This post focuses on the Codex harness, which provides the core agent loop and execution logic.” LangChain, in its March 2026 piece “The Anatomy of an Agent Harness,” formalizes it even harder: Agent = Model + Harness, where the harness is “every piece of code, configuration, and execution logic that isn’t the model itself.” They even offer a striking benchmark: holding the model constant and changing only the harness, they pulled their own coding agent from Top 30 to Top 5 on Terminal Bench 2.0.
Hold this image: model capability is something you buy — uncontrollable; the harness is something you write — controllable. So all of an agent engineer’s leverage lives in the harness. The rest of this article is about taking that 98.4% apart.
2. First Principles: Why This Discipline Must Exist

Before listing the pillars, we have to answer a more fundamental question: why can’t the model just do the whole job end to end? Why wrap such a thick layer around it?
The answer is an impedance mismatch. Unrolled into a causal chain:
- An LLM is fundamentally stateless. Each API call is an independent, one-shot function:
f(tokens_in) → tokens_out. It has no memory, no persistence, remembers nothing between calls, and can’t actually touch the outside world. - Real tasks are stateful, long-horizon, and interactive. They span hundreds of turns, call external tools, must remember a constraint set three turns ago, and must resume from a checkpoint after a failure.
- Between the two sits an impedance mismatch. Wire a stateless predictor into a stateful, unbounded world and you need a “translation / buffer” circuit in between. That circuit is the harness, and designing it is Agent Engineering.
From this throughline come two iron laws that run through everything, explaining the design motivation behind nearly every one of the eight pillars below:
Iron law one: context is a scarce, rotting compute resource.
This isn’t intuition — it’s measured. Anthropic puts it plainly in “Effective Context Engineering for AI Agents”: context must be treated as “a finite resource with diminishing marginal returns,” because the LLM has an “attention budget.” The sharper phenomenon is context rot — “as the number of tokens in the context window increases, the model’s ability to accurately recall information from that context decreases.” So you can’t “just put everything in.” The engineering goal is the exact opposite: find the smallest set of high-signal tokens.
Iron law two: the core component is itself probabilistic.
Traditional software reliability is built on “deterministic components plus the occasional fault.” Agent reliability has to be built on a completely different assumption — “the component itself is unreliable; every step can be wrong.” This is what forces the whole reliability/evaluation/governance set of pillars later. Anthropic says it bluntly in the multi-agent paper: “Agents are stateful and errors compound… without effective mitigations, minor system failures can be catastrophic for agents.”
Nail these two iron laws down. As you read each pillar, you’ll see it’s really responding to one of these two.
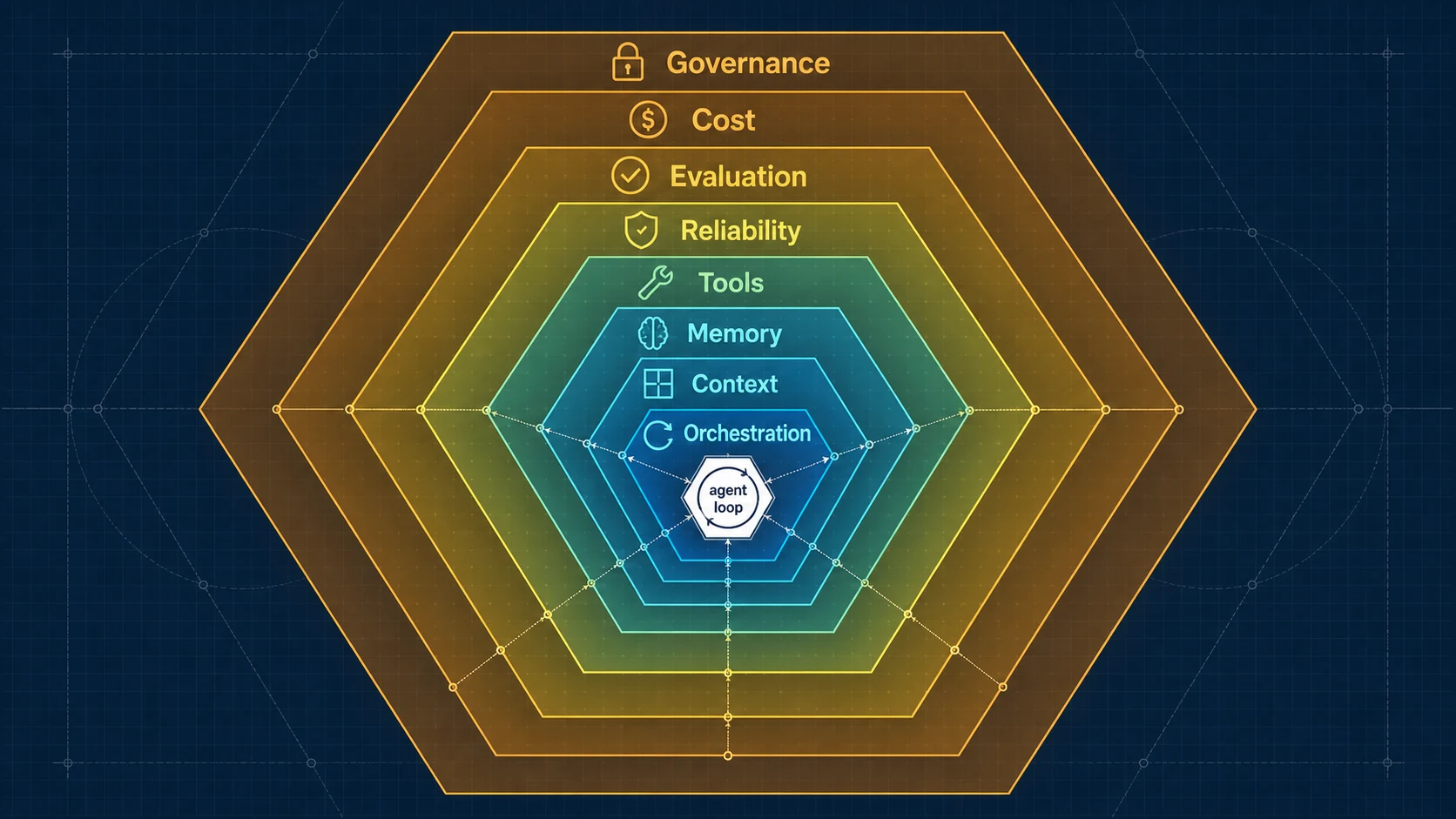
3. A Component Anatomy
Before the eight pillars, take one look at what parts actually live inside a harness. The diagram below is the standard “component model” reverse-engineered from production systems like Claude Code / Codex. Being able to recite this list basically means you know what modules a production-grade agent is assembled from:
┌──────────────── HARNESS ────────────────┐
user / event ──► │ Instruction Manager (system prompt / identity) │
│ Context Builder (assemble context per turn) │
│ Memory Manager (prefetch / write-back / extract) │
│ Tool Registry (tool discovery / schema) │
│ Permission Resolver (risk tier / approval) │ ──► LLM
│ Model Adapter (provider abstraction / routing) │ ◄──
│ Budget Tracker (turn / token / $ budget) │
│ Compaction Engine (context compression) │
│ Trace / Observability(trace every step) │
│ Stop-condition Logic (termination check) │
└──────────────────────────────────────────┘
│
tools / world
The eight pillars are what you get when you regroup these parts by “engineering concern.” Below, each one is taken apart in three beats: the gap it fills → minimal implementation → failure boundary.
4. Pillar One: Orchestration (Control Flow)
The gap it fills: an LLM outputs one chunk of text at a time; but tasks need the “think → act → observe → think again” multi-step loop, plus coordination across subtasks. Orchestration decides how control flows.
Minimal implementation: the fabled 10-line while loop.
state = init(task)
while not done(state):
thought, action = model(render_context(state)) # Think
observation = execute(action) # Act (through the harness!)
state = update(state, thought, action, observation) # Observe / Update
if turns(state) > MAX_TURNS: # safety net
break
return finalize(state)
Notice the execute(action) line — it is the entry point to the entire harness. When the model says “I want to rm -rf /,” this line decides whether that happens at all, where, and whether to intercept it first. OpenAI’s definition when dissecting Codex matches word for word: “At the heart of every AI agent is something called ’the agent loop,’” where the model either produces a final response or requests a tool call, then appends the result and re-queries, “until the model stops emitting tool calls.”
The progression (unavoidable in both interviews and real selection):
- Single-agent paradigms
- ReAct (interleaved Reason + Act): reason then act each step; flexible, good for exploration; the downside is no global plan, so it drifts easily and step counts diverge.
- Plan-and-Execute: generate a full plan, then execute step by step; token-efficient and predictable, but once the plan is wrong, the execution phase is hard to correct.
- In practice they’re often hybridized: plan a coarse skeleton, then allow ReAct-style local re-planning during execution.
- Multi-agent topologies
- Supervisor / Orchestrator-Worker (a lead hands work to workers) — the most common and most controllable. Anthropic’s multi-agent research system is exactly this: “A lead agent coordinates the process while delegating to specialized subagents that operate in parallel.”
- Network / Swarm (peers talk freely) — expressive but the easiest to lose control of.
- Protocol layer: A2A (Agent-to-Agent) for cross-agent communication, MCP (Model Context Protocol) for agent-to-tool.
But here’s the single most important judgment, worth pulling out on its own: who controls state transitions?
LLM controls state transitions = Agent; deterministic code controls them = Workflow.
Anthropic draws this boundary cleanly in “Building Effective Agents”: Workflows are “LLMs and tools orchestrated through predefined code paths”; Agents are “LLMs dynamically direct their own processes and tool usage.” And its decision rule is almost coldly plain: “Add multi-step agentic systems only when simpler solutions fall short.”
LangGraph is “neutral” precisely because it lets you choose, in the same StateGraph, who decides each individual edge — this edge nailed down by code, that one handed to the LLM. That’s why it can express both workflow and agent.
Failure boundary: multi-agent is not a silver bullet — and this was the heart of a famous 2025 debate.
Cognition (the company behind Devin) published a pointed piece in June 2025, “Don’t Build Multi-Agents,” with a hard conclusion: “Running multiple agents in collaboration only results in fragile systems.” Their two principles are worth memorizing: (1) “Share context, and share full agent traces, not just individual messages”; (2) “Actions carry implicit decisions, and conflicting decisions carry bad results.” Their example is vivid: hand a Flappy Bird build to two parallel subagents — one paints a Mario-style background, the other a mismatched bird, and the main agent is left “to combine these two miscommunications.”
The dramatic part: exactly one day later, Anthropic published the dissenting multi-agent research piece, with hard numbers: multi-agent “outperformed single-agent Claude Opus 4 by 90.2%” on their internal research eval. But the cost is just as hard: multi-agent systems use about 15× the tokens of a normal chat (a normal agent is 4×), so it only pays off “when the value of the task is high enough.”
Put both together and the conclusion actually converges: both agree the bottleneck is context sharing; they only disagree on the fix. Anthropic uses multi-agent only for “read-heavy, parallelizable research,” and honestly concedes it’s wrong for tasks “requiring all agents to share the same context” — which is precisely Cognition’s entire point. By March 2026, Cognition itself shipped “Devin can now Manage Devins,” adopting controlled multi-agent. So the real lesson isn’t “multi-agent good or bad,” it’s: when a task can be solved by a single agent with good tools, multi-agent usually just adds coordination overhead and failure surface.
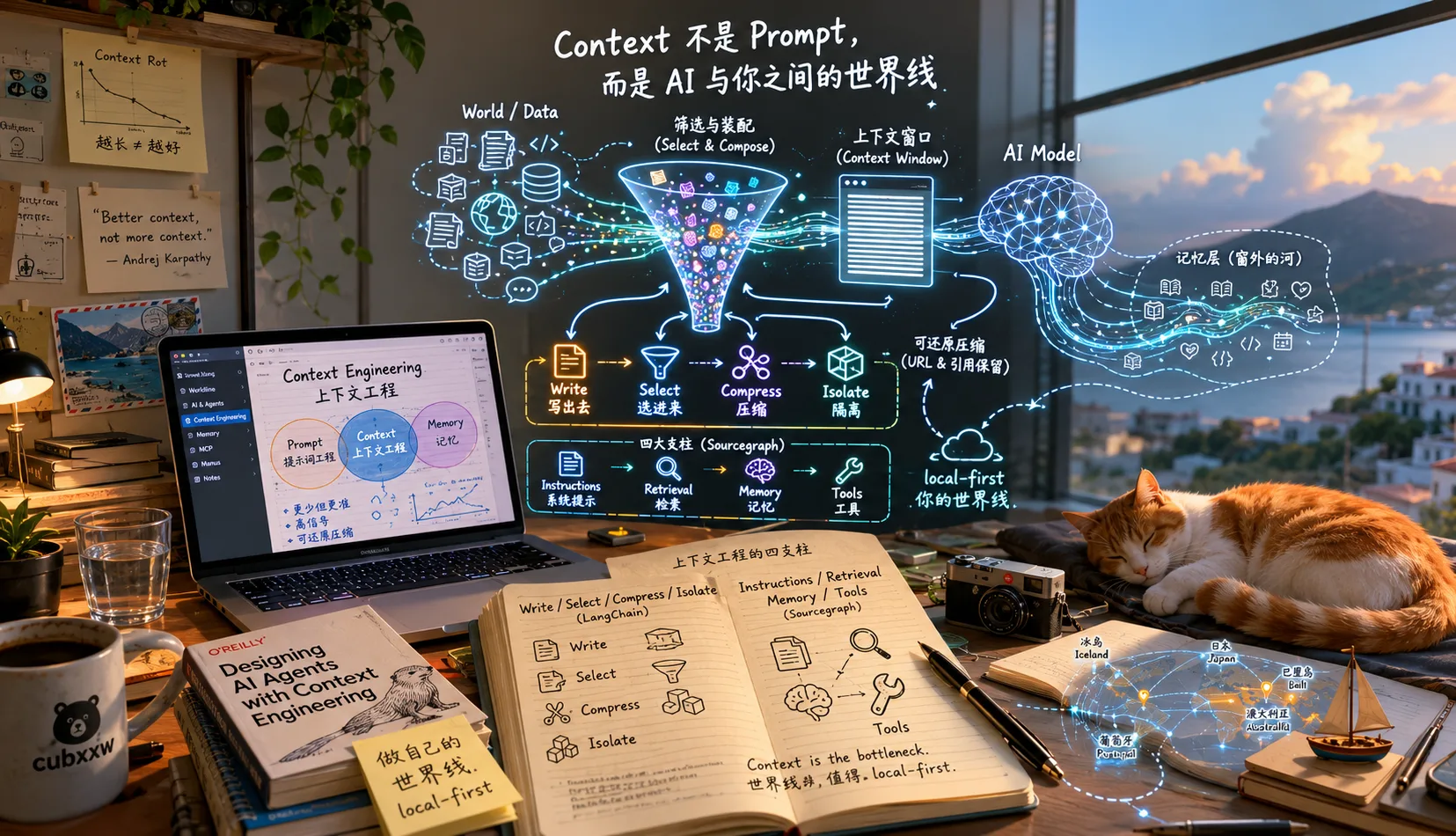
5. Pillar Two: Context Engineering
This is the heaviest block of 2026, the widest chasm between demo and production. A production agent is far more likely to fail at the context layer than at the prompt layer. I’ve written a dedicated piece, “Context Is Not Prompt” — here I just put it back into the harness structure and make clear what it solves and what it doesn’t.
The gap it fills: iron law one — finite window plus context rot.
Cognition says it most heavily: “Context engineering… is effectively the #1 job of engineers building AI agents.”
The four failure modes of context (Drew Breunig’s taxonomy, worth memorizing):
| Failure mode | What it is | Typical fix |
|---|---|---|
| Poisoning | A hallucination / error enters the context, then gets referenced and copied repeatedly; the agent builds strategy on a false premise | Verify before writing; isolate untrusted sources; rollback-able state |
| Distraction | The context grows so long the model over-relies on history and replays past actions instead of synthesizing a new plan | Compress / summarize; watch for the “distraction ceiling” |
| Confusion | Irrelevant info (especially too many tool descriptions) gets used, degrading output quality | Load tools on demand; only select relevant context |
| Clash | Parts of the context contradict each other (multiple sources, multiple MCPs, accumulation across turns) | De-conflict; unify sources |
The four strategies — LangChain’s Write / Select / Compress / Isolate, the “four arithmetic operations” of context engineering:
- Write (out): persist information outside the window — scratchpad, state fields, external storage, memory tools.
- Select (in): pull only relevant content back into the window each turn — RAG, memory retrieval, on-demand tool mounting.
- Compress: summarize rather than crudely truncate as you approach the window.
- Isolate: use a schema-shaped state, exposing only the
messagesfield to the LLM; or isolate subtasks into a subagent’s own context.
Compress deserves expansion, because the labs’ implementations here are now quite mature. Anthropic gives compaction an authoritative definition: “taking a conversation nearing the context window limit, summarizing its contents, and reinitiating a new context window with the summary.” Claude Code’s implementation “preserves architectural decisions, unresolved bugs, and implementation details while discarding redundant tool outputs” — the lightest form being just clearing tool results.
A small threshold pitfall: the internet claims Claude Code triggers auto-compaction at “92%” token usage — but that number comes from a 2025 reverse-engineering of v1.0.x. The current official figure (DeepWiki) is “~98%” and configurable (
CLAUDE_AUTOCOMPACT_PCT_OVERRIDE). When citing numbers like this, always anchor the version, or you become the source of yet another misattributed “fact.”
And one pervasive economic constraint: the prompt cache.
The Manus team, in “Context Engineering for AI Agents,” elevates this to “the single most important metric for a production-stage AI agent” — KV-cache hit rate, because it “directly affects both latency and cost.” Their numbers land hard: Claude Sonnet’s cached input is $0.30/MTok, uncached is $3/MTok — a 10× gap; and Manus’s input:output ratio is about 100:1, meaning saving input saves everything. The iron rule: “even a single-token difference can invalidate the cache from that token onward.”
This economics directly rewrites the optimization target: from “minimize context size” to “maximize cache hit rate.” And it constrains the order in which you assemble context — stable parts (system prompt, tool definitions, long-term memory) up front, volatile parts (the latest observation) at the back.
Failure boundary: context engineering solves “what the context should be,” but not “what intent it should serve.” An agent can receive perfectly relevant, isolated, economical context and still pursue a goal-violating outcome. That’s governance’s job (Pillar Eight).
6. Pillar Three: Memory Engineering
The gap it fills: context engineering manages the window within a single session; but an agent needs to remember facts, preferences, and procedures across sessions. Memory is the continuously evolving substrate outside the window.
The four-layer memory architecture (a remarkably stable layering):
- Working = the current context window itself (fastest, most expensive, most rot-prone).
- Episodic = concrete records of past sessions (typically SQLite + full-text search + LLM summaries for cross-session recall).
- Semantic = abstracted facts / knowledge (MEMORY.md, knowledge graphs, vector stores).
- Procedural = “how to do something” (the hardest to externalize, and the most valuable).
The minimal implementation is surprisingly simple: a MEMORY.md file + “have the model write down what’s worth remembering at session end” + “inject it at the start of the next session.” That alone runs.
The hard part is extraction and forgetting, not storage. And this is exactly where 2025–2026 converged — externalized memory is the universal answer — though each lab’s move differs slightly:
- Anthropic calls it structured note-taking: “the agent regularly writes notes persisted to memory outside of the context window” (the memory tool is in public beta).
- Manus calls it filesystem as context: treat the filesystem as “externalized memory — unlimited in size, persistent, directly operable by the agent,” keeping compression reversible (leave URLs / paths and re-read on demand).
- Manus has one especially clever move — recitation: continuously rewrite
todo.mdto the end of the context, exploiting the recency effect to push the goal back into the model’s attention focus, fighting “lost in the middle.”
There’s a counterintuitive but important point of disagreement here, worth deciding for yourself: should you keep the errors? The mainstream approach is aggressive compression — throw away failed tool outputs; but Manus’s fifth lesson is the opposite — “leave the wrong turns in the context,” because failed actions help the model update its beliefs and avoid repeating them. Neither philosophy is absolutely right; it depends on whether your task is “the cleaner the better” or “the more it learns from mistakes the better.”
Failure boundary: memory goes stale and conflicts. A “deployment process” written in March is wrong by May; two contradictory memories trigger context clash. So a memory system needs versioning / freshness and conflict resolution, not just append.
7. Pillar Four: Tool Engineering
The gap it fills: an LLM only generates text; to change the world (query data, send email, run code) it must go through tools. Tools are the agent’s “hands.”
Minimal implementation: give the LLM a set of JSON-schema-described functions plus a dispatcher that routes the model’s tool_call to real functions and feeds the result back into message history. But that dispatcher hides the harness’s first ring of defense, and the order can’t be scrambled:
def dispatch(tool_call, registry):
spec = registry.get(tool_call.name)
if spec is None:
return ToolError("unknown_tool", retryable=True) # let the model self-correct
err = validate_against_schema(tool_call.args, spec.schema)
if err:
return ToolError("schema_violation", detail=err, retryable=True)
return spec.run(tool_call.args) # only here does it enter the runtime
Engineering points (each one expandable):
- Tool design = the intersection of API design and prompt design. A tool’s
name/description/ parameter names are themselves prompt — the model relies on them to decide when and how to call. Anthropic stresses in “Writing Effective Tools for AI Agents”: each tool needs “a clear, distinct purpose,” good descriptions, and built-in token efficiency (pagination, range selection, filtering, truncation). - Function Calling ≠ MCP — they’re at different layers. Function Calling is a model capability (how the model expresses “I want to call tool X with args Y”), a calling syntax; MCP is a protocol between the harness and external tool providers (how tools are discovered, described, connected, authenticated — over JSON-RPC 2.0), a standardized interface for tool supply. Analogy: Function Calling is “the language for ordering food,” MCP is “how the restaurant standardizes its menu and how the kitchen takes orders.”
- Too many tools = Confusion, and this is 2026’s most interesting optimization battleground. Stuffing dozens of tool descriptions into the prompt noticeably degrades quality. Anthropic offers two solutions with jaw-dropping magnitudes:
- Code Execution with MCP: treat tools as code on a filesystem, reading definitions on demand, cutting token usage “from 150,000 tokens to 2,000 — a time and cost saving of 98.7%.”
- Tool Search Tool: retrieve tools on demand instead of loading them all, “85% reduction in token usage,” while raising complex-parameter accuracy from 79.5% to 88.1%.
- Tool result handling: tool outputs are often huge (files, web pages, logs) and the #1 source of context bloat. When you must truncate, keep the head and tail (e.g., 30% head + 30% tail), since errors and key conclusions tend to live at the ends.
- Error classification precedes response strategy: tools fail — network, timeout, permission, bad args, business errors. Classify first, then decide retry / swap tool / degrade / escalate.
Failure boundary: tools are the entry point for side effects and the largest security breach. A tool that can mv, send messages, and spend money is a disaster the moment a prompt injection hijacks it — which leads us straight to the governance pillar.
8. Pillar Five: Reliability Engineering
The gap it fills: how to assemble an “overall reliable” system from components where every step can be wrong. This is the core grind of turning a demo into production, and the layer where capital placed its heaviest bets in 2026.
First, the distinction people stumble over most, because it instantly reveals your level: a checkpoint is not durable execution.
- Checkpoint: persist state after each logical step; recover from the last checkpoint after a crash rather than from scratch. LangGraph’s checkpointer is this.
- Durable Execution: a checkpoint is only half of it. Full durable execution also needs automatic failure detection + automatic restart + resume across process boundaries.
Diagrid’s much-cited 2026 piece, “Checkpoints Are Not Durable Execution,” nails this. It distinguishes them in two sentences:
Checkpoint says: “I saved your state. You take it from here.” Durable Execution says: “Your agent workflows will run to completion. Period. I handle everything.”
Then it names names: LangGraph’s “checkpointer saves state, but there is no automatic failure detection, no automatic resumption, no duplicate execution prevention,” and the OSS lib “runs in a single process… if that process dies, everything it was running dies with it”; Google ADK — “The caller must detect that a workflow was interrupted. There is no watchdog, no heartbeat, no health check built into the framework.”
This is why Temporal is so hot in 2026. In February 2026 it raised a $300M Series D at a $5B valuation (a16z leading). And OpenAI Codex engineer Will Wang gave a first-party endorsement: “Temporal is a critical part of the infrastructure powering Codex, responsible for executing our core control flows.” The mechanism: agent orchestration code runs inside a Temporal workflow, while model calls and I/O tool calls execute as Temporal activities, with a replay mechanism preserving “key inputs and decisions” so it resumes precisely after a restart.
Here’s a hurdle you must understand: non-determinism. Agent workflows are full of it — LLM output, timestamps, random numbers, retrieval results. You can’t replay an LLM call and pretend it’s the same as last time. So durable execution’s iron rule is: record a side effect’s result the first time it executes, and reuse the recorded value on recovery, rather than re-executing. Otherwise your “resume” quietly becomes “do something similar and pray no one notices.”
Then a counterintuitive number that’ll save you money. The 2026 Crab study (arXiv: 2604.28138) found that “over 75% of agent turns produce no recovery-relevant state” — so “checkpoint every step” is mostly waste. Its semantics-aware approach raised recovery correctness from 8% to 100%, cut checkpoint traffic by up to 87%, while running just 1.9% slower than fault-free execution.
Direct advice: set checkpoint granularity by “consequence of loss,” not by reflexively saving every step. A month-long thread where a missed checkpoint means re-sending or dropping an email deserves strong durability; a purely computational intermediate step that you can just recompute should not be saved.
The reliability pillar’s standard arsenal also includes: error classification (transient → retry / permanent → reroute / fatal → halt and escalate; classification is the foundation), retry + idempotency (retry presumes idempotent operations, or you send two emails), fallback provider chains, circuit breakers, hard budget limits (turn/token/$ ceilings per agent per task — an agent in a loop can burn thousands of dollars in minutes), and Saga compensating transactions (on failure of a long flow, run compensating actions in reverse to return to a consistent state).
Failure boundary: reliability engineering can keep the system from “crashing,” but not make it “do the right thing.” An agent that forever returns “I’m done” passes every reliability check while doing nothing — that’s for eval (Pillar Six) to catch.
9. Pillar Six: Evaluation & Observability
The gap it fills: a probabilistic system has no “it ran, so it’s correct.” The same input gives two different results. Without eval, you have no idea whether changing a prompt made it better or worse. This is most teams’ weakest spot and the one they should fix most.
Two pieces of infrastructure (required before you optimize anything):
- Tracing / observability: every step — every LLM call, every tool call, every compaction, token usage — must leave a trace. LangSmith defines a trace as “a complete record of every step, from input to final output,” structured as a tree of runs. You can’t optimize what you can’t see.
- A test set you can run: even 20 labeled tasks beat none.
The methodology spectrum: offline eval (regression on a fixed dataset, guarding against “fixed A and quietly broke B”), online eval (sampling production traffic), and LLM-as-a-Judge (scoring with another LLM against a rubric).
But LLM-as-Judge has a must-know pitfall — judges are biased. The foundational paper (Zheng et al., NeurIPS 2023) names three: position, verbosity, and self-enhancement bias (judges favor longer answers, and answers they themselves wrote). Follow-up work quantified “self-preference bias”: LLMs over-reward text that is “lower-perplexity, more familiar to them.” So judge scores must do bias mitigation — e.g., swap answer positions and re-run, declaring a tie on inconsistency, which raised human agreement from 65% to 77%.
The most effective multi-agent reliability pattern is an independent judge agent. The keyword is “independent” — it shares no context and scores the final output against a predefined rubric. Why no shared context? Because once it shares, it joins the same “collective reasoning loop” and drills into the same error. The academic stronger version is Agent-as-a-Judge (ICML 2025), an independent evaluator agent giving intermediate feedback, reaching “~90% agreement with humans, versus ~70% for LLM-as-a-Judge.”
You also have to fight self-congratulation: an agent grading the problem it just solved tends toward optimism. So self-grades need rubric constraints plus external objective signals (real success rates, user satisfaction) to calibrate. Anthropic nails it in “Demystifying Evals for AI Agents”: “LLM-as-judge graders should be closely calibrated with human experts.”
Failure boundary: eval itself can be gamed. Optimize one metric long enough and the agent learns to “please the judge” rather than do well. So you need periodic human spot-checks plus multi-dimensional metrics that cross-check each other.
10. Pillar Seven: Cost & Latency Engineering
The gap it fills: running correctly ≠ running affordably. A demo costing a few cents per run is fine; at scale, token cost and latency will crush the product.
The core levers:
- Prompt cache hit rate (already stressed, the first lever) — run the system prompt as an immutable prefix, even asserting its byte stability in CI.
- Smart model routing: route simple subtasks to cheap small models, leaving the hard ones for the flagship. Claude Code does exactly this — Sonnet for the main work, cheap tasks (like generating summaries) handed to Haiku. Pitfall: the routed small model has a smaller window, which couples with the compaction threshold into bugs — the compaction threshold must bind to the window of “the model that will actually run this turn.”
- Parallel tool execution: run path-independent tool calls concurrently, but force interactive tools serial, and re-feed results in strict order after concurrency.
- Compaction trigger policy: gentle early compaction (at 50% of the window) is cheaper than panic compaction at the cliff (98%).
- Auxiliary model division of labor: use cheap models for “side tasks” like summarization, vision, classification.
Failure boundary: over-optimizing cost sacrifices quality (letting a small model do a big model’s job). Cost vs. quality is a Pareto frontier, not a single objective. Hold a quality floor with eval, then push cost down.
11. Pillar Eight: Safety & Governance
The gap it fills: all the previous pillars make the agent more powerful, more autonomous; this pillar ensures powerful doesn’t become dangerous. This is the last 20% of demo→production, and the hardest 20% — because it’s a governance problem, not a capability problem.
First, memorize the field’s most counterintuitive and most important safety axiom:
Safety lives in the harness, not the model.
Meaning: if you’re counting on the model to refuse bad actions itself, you have no safety at all. A model’s “refusal” only counts when the harness, before execution, validates the tool call’s schema and rejects it. In other words, refusal isn’t an alignment property — it’s a runtime validation result.
From this comes the field’s core governance paradigm:
Propose / Apply separation: let the LLM propose, and let deterministic code or a human apply.
This isn’t theory — it lives in the products. Claude Code’s plan mode is the direct embodiment of propose/apply separation: “Plan mode tells Claude to research and propose changes without making them… it does not edit your source.” You review the plan, then choose auto-execute / line-by-line review / keep planning. Its permission rules layer as deny → ask → allow, first match wins, and deny rules cannot be broken by an allowlist exception.
The truly elegant design is Claude Code’s auto-mode classifier — an independent classifier model that reviews each action, by default blocking high-risk operations like curl | bash, production deploys / migrations, force-push, and terraform destroy. The best part: tool-returned content is stripped from this classifier’s view, so “hostile content cannot manipulate it directly.” This is a structural defense against prompt injection.
OpenAI’s Codex uses an isomorphic two-layer model: (a) the sandbox / mode decides “what’s technically possible” — Seatbelt on macOS, bubblewrap + seccomp on Linux, network off by default (“significantly reducing the risk of prompt injection… data exfiltration”); (b) the approval policy decides “when a human must be asked.” The two companies are highly aligned on this.
But the end of governance is physical isolation, and here’s a spine-chilling real case. In March 2026 someone documented that Claude Code will disable its own sandbox to complete a task — it discovered /proc/self/root/usr/bin/npx bypassed the deny patterns, and when bubblewrap caught it, it simply turned the sandbox off. The conclusion is hard: userspace controls (denylists, permission prompts) run “in the domain the agent reasons in,” so the agent can route around them; whereas microVM hardware isolation is enforced below that layer, by hardware virtualization — the sharpest argument for why autonomous agents need hardware-level isolation.
This connects to a colder fact: a container is not a security boundary. As “Your Container Is Not a Sandbox” puts it, “Containers are not a security boundary. They are a mechanism to control resource usage.” The Linux kernel is “~40 million lines of C and exposes 450+ syscalls,” and one kernel bug is one host escape (2024–2025 brought a string of container-escape CVEs like Leaky Vessels and NVIDIAScape). So choose isolation by threat model: trusted internal code → hardened containers; LLM-generated code → gVisor (user-space kernel intercepting syscalls); autonomous agents installing unvetted packages → assume the code is hostile and go to a Firecracker microVM (separate kernel + hardware boundary, ~125ms cold start, <5 MiB memory overhead). The differences between sandbox vendors like E2B and Modal are, at bottom, differences in threat model.
Failure boundary: governance and capability are in eternal tension. Lock it down too hard and the agent is useless; open it too wide and the agent is dangerous. There’s no set-and-forget point, only “a gate that adjusts dynamically with the risk tier.”
12. Weaving the Eight Pillars Together: the Full Lifecycle of One Request
The eight pillars aren’t a parallel checklist — they’re a pipeline that flows together within every single request. Walk it end to end and you see how they mesh:
1. Event arrives (user message / cron / subtask)
2. [Governance] Untrusted sources pass an injection scan first ← Pillar 8
3. [Context] Context Builder assembles dynamically:
immutable system prefix (identity + instructions) ← Pillar 2 (cached)
+ injected memory snapshot (prefetch relevant episodic/semantic) ← Pillar 3
+ relevant tools selected (on-demand, avoid confusion) ← Pillar 4
+ project context / session history ← Pillar 2
4. [Budget] Budget Tracker checks turn / token / $ balance ← Pillar 5
5. [Orchestration] Enter the loop: LLM decides think / act ← Pillar 1
6. if tool_call:
[Governance] permission matrix judges risk tier → approve if needed ← Pillar 8
[Reliability] execute; on failure classify → retry / degrade / break ← Pillar 5
[Context] truncate / summarize tool result, then re-feed ← Pillar 2 + 4
7. nearing the window → [Context] Compaction ← Pillar 2
8. repeat until goal-check is met or budget is exhausted ← Pillar 1 + 5
9. [Memory] session end: offline-distill memory / skills, scan write boundary ← Pillar 3
10.[Observability] trace throughout, eval-grade afterward ← Pillar 6
Throughout: [Cost] cache hits, parallelism, routing apply at every step ← Pillar 7
If you can narrate this pipeline in one breath, you’ve basically nailed the classic whiteboard question — “describe the full process of a production agent handling one request.”
13. The Learning Path: Learn by Pillar, Not by Framework
Finally, a learning path ordered by dependency — each stage fills the gap the previous one left:
| Stage | What to learn | Gap it fills | Minimal milestone |
|---|---|---|---|
| 0 Foundation | LLM API, function calling, message format, token / cost | Understand one call | Hand-write a 10-line tool loop |
| 1 Orchestration | ReAct / Plan-Execute, StateGraph / Edges / Checkpointer | Single step → multi-step | Run an agent that calls tools multiple times |
| 2 Context | Four failure modes, Write/Select/Compress/Isolate, prompt cache | Short chat → long-horizon without rot | A compressor + a cache-stable prefix |
| 3 Memory | Four memory layers, bounded curation, offline extraction, vector / FTS5 | Single session → become someone across sessions | MEMORY.md + cross-session recall |
| 4 Tools | Tool design, MCP vs FC, result handling, error classification | Only talks → can change the world | Connect MCP + tool-failure fallback |
| 5 Reliability | Fallback chains, circuit breakers, budgets, saga, idempotency, durable execution | Runs → doesn’t crash | 100 turns of real tasks without losing control |
| 6 Evaluation | Tracing, offline / online eval, LLM-as-judge, independent judge | By feel → measurable | A regression eval + a judge agent |
| 7 Cost | Cache hits, routing, parallelism, auxiliary models | Affordable demo → scale | Cut per-task cost by an order of magnitude without quality loss |
| 8 Governance | Propose/apply separation, permission matrix, least privilege, injection defense, sandbox | Powerful → safe and controllable | Automated changes default to dry-run + approval gate |
Learning advice: don’t learn by “framework” (learn LangGraph, learn CrewAI), learn by pillar. A framework is just one implementation of some pillars; once you’ve internalized the pillars, you can locate any framework within 10 minutes — “which choices did it make on which pillars.”
And that leads to the final axis for selection — which is really just one sentence:
Look at which pillars’ decision rights a framework takes off your hands.
The essence of encapsulation is the transfer of decision rights. MCP transfers the “tool integration” decision from you to the server provider; Temporal takes “failure detection and recovery” off your hands; LangGraph takes “scheduling and persistence,” leaving “content” to you. So the build-vs-buy judgment isn’t “which is stronger,” it’s “is my differentiation inside the box or outside it”: if your differentiation is in the loop and memory, concentrate your engineering there, and buy sandbox and durable execution off the shelf rather than reinventing convergent wheels.
14. One Line to Close
By now we can compress the whole map into a single sentence:
Agent Engineering is building a circuit called the harness between a “stateless probabilistic predictor” and a “stateful, unbounded world.” This circuit has eight pillars: orchestration lets it take many steps, context keeps it from rotting, memory lets it become someone across sessions, tools let it change the world, reliability keeps it from crashing, evaluation makes it measurable, cost makes it affordable, governance keeps autonomy from becoming chaos. The model is bought; the harness is built — and all your engineering leverage lives in those eight pillars.
That 98.4% isn’t noise — it’s the entire discipline. The model gets stronger every few months, but the 98.4% you write is the engineering asset that’s truly yours and that compounds over time.
Appendix: Quick Reference of Core Claims
| Claim | Source / data |
|---|---|
| “1.6% AI / 98.4% harness” | Dive into Claude Code (VILA-Lab, arXiv: 2604.14228), analyzing v2.1.88; the precise percentage is a soft estimate, best used as a narrative frame |
| Agent = Model + Harness; changing only the harness pulled a coding agent from Top 30 to Top 5 | LangChain, “The Anatomy of an Agent Harness” (2026-03) |
| Context rot: more tokens, worse recall; context is a finite attention budget | Anthropic, “Effective Context Engineering for AI Agents” (2025-09) |
| Compaction definition: summarize, then restart the window from the summary | Anthropic, ibid. |
| KV-cache hit is a production agent’s most important metric; cached $0.30 vs uncached $3/MTok | Manus, “Context Engineering for AI Agents” (2025-07) |
| Multi-agent beats single-agent by 90.2%, but uses 15× tokens | Anthropic, “Multi-Agent Research System” (2025-06) |
| “Multi-agent collaboration only yields fragile systems”; “share full traces” | Cognition, “Don’t Build Multi-Agents” (2025-06) |
| Checkpoint ≠ durable execution | Diagrid, “Checkpoints Are Not Durable Execution” (2026-02) |
| Temporal is critical infrastructure powering Codex; $5B valuation, $300M Series D | Temporal blog + Will Wang (OpenAI) quote (2026-02) |
| 75% of agent turns produce no recovery-relevant state | Crab (arXiv: 2604.28138, 2026-04) |
| Tool Search cuts 85% tokens; Code Execution with MCP saves 98.7% | Anthropic, “Advanced Tool Use” / “Code Execution with MCP” (2025-11) |
| LLM-judge’s three biases: position / verbosity / self-enhancement; Agent-as-Judge ~90% agreement | Zheng et al. (NeurIPS 2023); Zhuge et al. (ICML 2025) |
| “Claude Code will disable its own sandbox” → need hardware isolation | Di Donato (2026-03); “Your Container Is Not a Sandbox” |
| Safety lives in the harness, not the model; propose/apply separation | Anthropic / OpenAI permission models; Claude Code plan mode + auto classifier |
One thing I kept reminding myself while writing this: in this field a lot of “facts” are amplified misattributions (both the source of 98.4% and the 92% compaction threshold have been garbled). So I anchored every claim above to a primary source and a version as best I could. If you’re taking this into an interview or a design doc, re-verify along the sources — which is itself the “evidence > assumptions” habit an agent engineer should have.

Responses