“Most Agent projects die in the unmapped wilderness between PoC and production.”
I wrote that line while reading through the Relay project documentation. Relay is an open-source AI Agent system for job searching — not a demo built on three lines of LangChain plus GPT-4, but a project with complete architectural documentation, 172 engineering tasks, a hybrid tech stack, and explicit counterexamples for every major design decision.
It is not fully running yet. The Agent layer code is still being written. That is exactly why I think this article is worth writing: this is a system that has thought very deeply at the design level, and those deep thoughts — regardless of where this project ultimately lands — are valuable references for everyone doing Agent engineering.
This article is not a product overview. It is an architectural breakdown.
1. Why Job Search Is Uniquely Suited to an Agent System
Before discussing architecture, I want to answer a more fundamental question: why is job searching a domain for Agents rather than just AI tools?
Job searching is a multi-stage, multi-tool, cognitively intensive workflow:
Resume prep → Job search → Resume tailoring → Form fill → Application tracking
↑ ↓
└─────────── Interview prep ← Interview invite ←───────────┘
Every node involves enormous amounts of low-value mechanical work — searching, copying, pasting, formatting, filling forms. At the same time, every node’s high-value judgments — is this role right for me? how should I frame this experience? how should I practice this interview question? — are highly personal and deeply context-dependent.
That is exactly where an Agent system should intervene: automate mechanical labor, assist high-value judgment, and make irreversible actions transparent.
Relay’s north star is: “quality over quantity — one precise shot beats a hundred blind sprays.”
This positioning alone determines that the architecture cannot be “one-click mass apply.” It must be “every application goes through user review.”
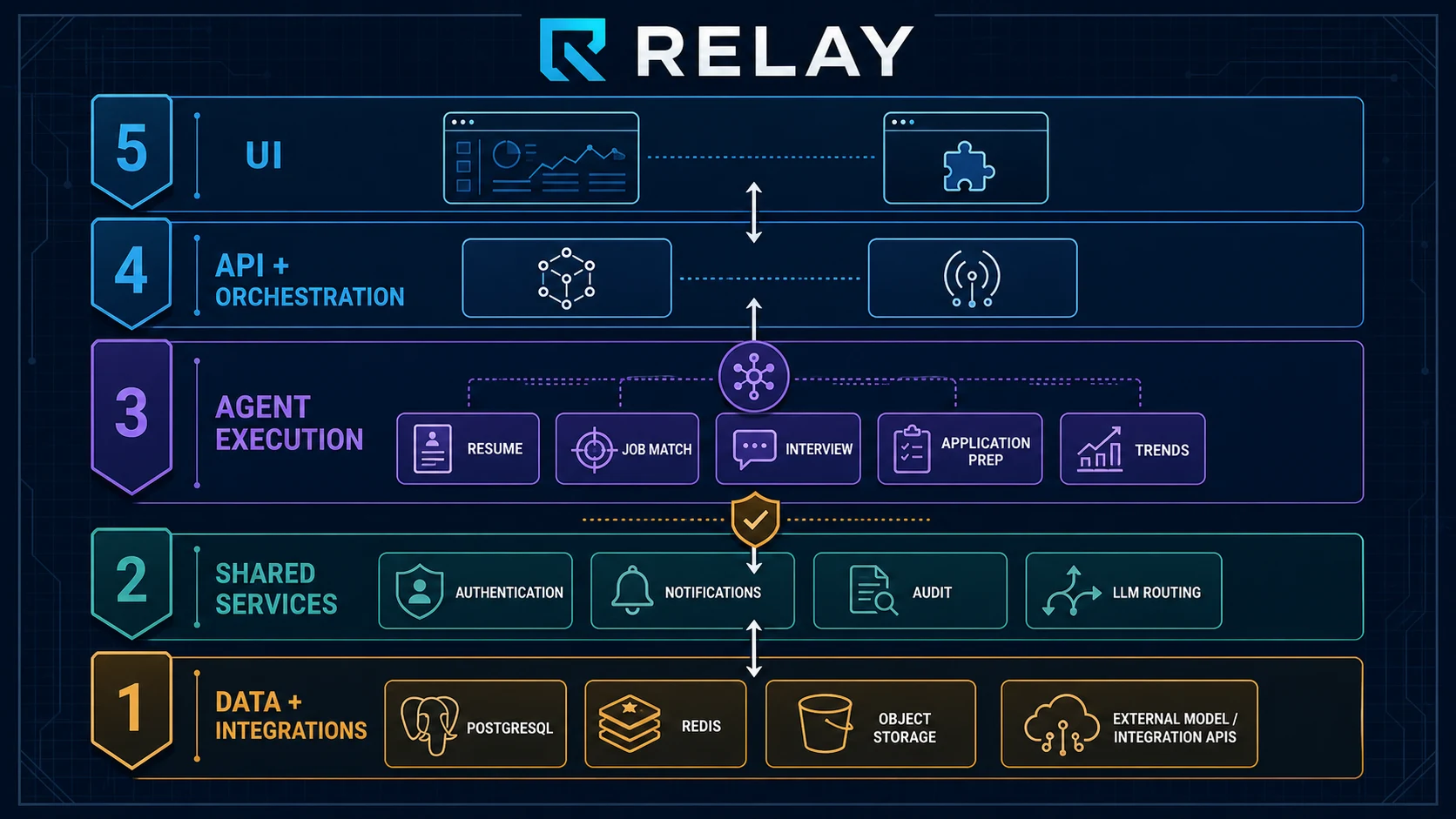
2. Overall Architecture: Five Layers
Relay’s architecture has five layers, from the bottom up:
+----------------------------------------------------------+
| Layer 5: UI |
| Next.js 16 web console + Manifest V3 browser extension |
+----------------------------------------------------------+
| Layer 4: API + Orchestration |
| Hono/Bun TypeScript API + Redis Event Bus |
+----------------------------------------------------------+
| Layer 3: Agent Execution |
| Python FastAPI + LangGraph (5 domain agents) |
+----------------------------------------------------------+
| Layer 2: Shared Services |
| Auth, Notification, Audit, LLM Router |
+----------------------------------------------------------+
| Layer 1: Data + External Integrations |
| PostgreSQL + pgvector, Redis, MinIO, OpenRouter |
+----------------------------------------------------------+
The most central design decision is the hybrid backend: TypeScript (Hono + Bun) for the API layer, Python (FastAPI + LangGraph) for the Agent layer, connected via HTTP + Redis + a shared PostgreSQL instance.
This is not a compromise. It is an intentional division of labor:
- TypeScript/Hono: rapid iteration, type safety, small bundle, ideal for CRUD + middleware + routing
- Python/LangGraph: mature AI ecosystem, complex reasoning, state management, multi-turn dialogue, deep community support
The two layers do not share a process, only data. The TypeScript API calls the Python FastAPI via HTTP; the Python Agent writes to PG, and the TypeScript API reads from it. No RPC framework, no gRPC. The simplest decoupling approach is often the most reliable.
3. Agent Layer: Why 5 Agents Instead of 1
This is the most worthwhile design decision to dig into.
3.1 Failure Modes of a Single Agent
Many teams’ first instinct when building an Agent system is “one Agent does everything.” The reasoning is straightforward: fewer services means fewer failure modes; context stays complete inside one Agent; no inter-agent communication needed.
But this intuition runs into fundamental problems as the system grows:
Coordination cost scales as O(N squared). When one Agent must simultaneously handle “parse a PDF resume,” “match jobs,” “generate interview questions,” and “scrape market trends,” the prompt grows unboundedly, the model must switch between radically different tasks, errors cannot be isolated, and debugging becomes nearly impossible.
Model tier requirements conflict. Parsing a PDF needs a fast, cheap model. Deeply evaluating an interview performance needs a model with strong reasoning. Batch ETL needs the lowest possible cost. A single Agent either uses the most expensive model for everything, or introduces extremely complex model-switching logic.
Prompt evolution cadences differ. The “resume optimization” prompt might update weekly. The “trend report” prompt might update quarterly. The “interview question generation” prompt needs continuous iteration based on crowdsourced data. Mixed together, any update to one can affect the others.
Data flywheels cannot grow independently. The value of the interview question database needs to aggregate from all users’ interview records — that is independent business logic that should not be mixed with resume parsing.
3.2 Relay’s 5-Agent Design
Relay splits responsibility into 5 single-purpose agents:
| Agent | Core Responsibility | Trigger | Primary Model |
|---|---|---|---|
| ResumeAgent | Parse / optimize / tailor resume | User upload / click | GLM-4.7 (optimize) + V4Flash (parse) |
| JobMatchAgent | Scrape / parse / match jobs | Cron + events | V4Flash + Embeddings |
| InterviewAgent | Generate questions / evaluate answers | User-initiated conversation | V4Pro (evaluate) + GLM-4.7 (generate) |
| AppPrepAgent | Prepare application package | Coordinator call | GLM-4.7 + V4Flash |
| TrendAgent | ETL / skill extraction / reports | Daily cron | V4Flash + DuckDB |
Every split maps to at least one of the four dimensions above: different triggers, different model tiers, different data flywheels, different prompt evolution cadences. Not splitting for its own sake.
3.3 The Coordinator: The Agent That Orchestrates All Agents
Above the five domain agents sits a Coordinator — “Ask Vantage” — the entry point for user conversations.
The Coordinator’s core job is intent recognition + tool routing, implemented as a LangGraph create_react_agent with 12 registered tools:
tools = [
# Propose plan (HITL)
propose_plan,
# Call domain agents
tailor_resume, find_jobs, start_mock_interview, draft_cover_letter,
# Memory recall
recall_user_memory, recall_past_applications, recall_weak_points,
# Admin operations
list_my_applications, build_resume_from_scratch, trends_today,
# Narrate
narrate,
]
One detail worth highlighting: fast-path and slow-path separation.
For simple intents (“show my applications,” “what are today’s trends”), a regex + V4Flash classifier runs first. If confidence is 95% or higher, the full ReAct reasoning loop is bypassed and the request is routed directly. This drops latency for the vast majority of simple requests by an order of magnitude while reserving expensive reasoning capacity for genuinely complex problems.
4. HITL: Human-in-the-Loop Is Not Optional
Relay repeats one design principle throughout its documentation: the user must personally click Submit before any application is created.
This is not a product UI choice. It is an architectural commitment.
4.1 Why Irreversible Actions Require HITL
Submitting an application is irreversible. Sending an email is irreversible. Deleting data is irreversible.
An Agent system without HITL for these actions is “a proxy with no undo key.” Users not trusting it — no matter how intelligent it is — is completely rational.
Relay splits tool permission into four tiers:
class Permission(Enum):
AUTO = "auto" # Execute silently, no notification
NOTIFY = "notify" # Execute then send WebSocket notification
APPROVE = "approve" # Pause and wait for user confirmation
BLOCK = "block" # Not registered, never executed
APPROVE is the critical tier. submit_form, send_email, delete_*, and similar operations all live here.
4.2 LangGraph’s interrupt() Implementation
LangGraph provides the interrupt() primitive to implement HITL checkpoints:
from langgraph.types import interrupt, Command
@tool
def submit_form(job_url: str, fields: dict) -> str:
# Pause before executing, wait for user confirmation
decision = interrupt({
"action": "submit_form",
"job_url": job_url,
"fields": fields,
"message": "Agent wants to submit to this position. Review the form and approve.",
})
if decision.get("type") == "approve":
# User may modify fields before approving
return do_submit(job_url, decision.get("fields", fields))
return "User cancelled this application."
When interrupt() is called, LangGraph persists the current graph state to PostgreSQL via PostgresSaver checkpointer and then pauses execution. After the user confirms in the frontend, the API layer sends Command(resume={"type": "approve", ...}) back to the graph, and execution resumes precisely from the pause point:
# After user approves
graph.invoke(
Command(resume={"type": "approve", "fields": modified_fields}),
config={"configurable": {"thread_id": session_id}},
)
The most important technical detail here is the checkpointer. Without a checkpointer, interrupt cannot pause across process boundaries because state only exists in memory. A PostgreSQL checkpointer lets the pause-resume cycle span any amount of time. A user coming back tomorrow to confirm an application is no problem.
4.3 HITL as a Trust Interface
From a higher vantage point, HITL is not just a safety mechanism — it is the trust interface between the user and the Agent.
When a user sees “Agent wants to do X, details below, approve?”, several things happen:
- The user understands what the Agent intends to do
- The user can modify parameters such as adjusting form fields
- The user has a chance to refuse
- The user’s approval act itself becomes a training signal
This is a fundamentally different trust relationship than “Agent did X in the background and told you afterward.”
Relay’s design position is: for irreversible actions, transparency and a sense of control matter more than efficiency.
5. Three-Tier LLM Routing: Cost Is an Engineering Problem
“Use the best model for everything” is common PoC thinking. In production, it shows up directly on the bill.
Relay’s approach is a three-tier LLM router with precise cost tracking.
5.1 Three-Tier Model Breakdown
Heavy (reasoning tier)
Model: DeepSeek V4 Pro
Cost: $0.435 / 1M input, $0.87 / 1M output
Uses: Deep interview evaluation, complex reasoning, scenes needing reasoning traces
General (general-purpose tier)
Model: GLM-4.7
Cost: $0.40 / 1M input, $1.75 / 1M output
Uses: Resume optimization/tailoring, Coordinator main loop, medium-complexity tasks
Fast (batch tier)
Model: DeepSeek V4 Flash
Cost: $0.098 / 1M input, $0.196 / 1M output
Uses: JD parsing, intent classification, batch ETL, simple extraction
Each tier corresponds to specific scenarios, chosen based on reasoning complexity and call frequency — not assigned randomly.
5.2 Precise Cost Calculation
// Cost calculation in api/llm.ts
const PRICE_TABLE: Record<string, { in: number; out: number }> = {
"deepseek/deepseek-chat-v4-pro": { in: 0.435, out: 0.87 },
"zhipu/glm-4.7": { in: 0.40, out: 1.75 },
"deepseek/deepseek-chat-v4-flash": { in: 0.098, out: 0.196 },
}
function computeCostCents(
model: string,
promptTokens: number,
completionTokens: number,
): number {
const p = PRICE_TABLE[model]
if (!p) return 0
const usd =
(promptTokens / 1_000_000) * p.in +
(completionTokens / 1_000_000) * p.out
// Convert to cents, four decimal places
return Math.round(usd * 100 * 10_000) / 10_000
}
Why track down to four decimal places in cents? A single call may cost less than $0.0001, but dozens of calls within a session accumulate quickly. Precise tracking is a prerequisite for cost observability.
5.3 Dynamic Downgrade
The Agent layer has a post_model_hook that accumulates token usage after each model call. When session cost approaches the $0.50 cap, a downgrade is automatically triggered:
def post_model_hook(state: CoordinatorState, model_output) -> CoordinatorState:
usage = model_output.usage_metadata
cost = compute_cost(current_model, usage.input_tokens, usage.output_tokens)
new_total = state["total_cost_cents"] + cost
if new_total > 40.0: # Approaching the 50 cents cap
trigger_model_downgrade(state) # V4 Pro -> GLM-4.7 -> V4 Flash
return {**state, "total_cost_cents": new_total}
This mechanism gives each session a cost ceiling while delivering the highest quality service for as long as possible on the more expensive models.
6. Fabrication Guard: Runtime Validation, Not Prompt Constraint
This is the single design in Relay that I believe has the most engineering value, and the one least often implemented in other systems.
6.1 The Root Problem
Letting AI optimize a resume has one fundamental risk: AI may invent things you never did.
“Improved team efficiency by 30%” — that 30% was made up by the AI. “Led a team of 5 engineers” — that 5 was added because the AI thought it “sounded good.”
A pure prompt constraint (“do not fabricate content”) is insufficient. The model will obey, until it does not.
6.2 Runtime Validation Mechanism
Relay’s solution is to extract all verifiable entities from the AI output after resume optimization, then compare against the original resume:
FABRICATION_PATTERNS = [
r'\b\d{4}\b', # Years
r'\b\d+%\b', # Percentages
r'\$[\d,]+', # Dollar amounts
r'\b\d+\s+people\b', # Headcounts
r'\b\d+\s+engineers\b', # Engineer counts
]
async def fabrication_guard(
original: ResumeContent,
optimized: str,
max_retries: int = 2,
) -> str:
for attempt in range(max_retries + 1):
entities = extract_entities(optimized, FABRICATION_PATTERNS)
violations = find_violations(entities, original)
if not violations:
return optimized # Passed validation
if attempt == max_retries:
# Exceeded retries — fail loudly
await audit_log("fabrication_guard_failed", violations)
raise FabricationDetected(
f"Could not eliminate fabricated content in {max_retries} attempts: {violations}"
)
# Regenerate with specific violations attached
optimized = await regenerate_with_violations(original, optimized, violations)
return optimized
Key design: on failure, do not silently degrade by returning the original content. Instead raise an explicit exception and write to the audit log. This lets the engineering team track the fabrication guard’s trigger rate and continuously improve prompts.
6.3 Why This Matters
From a product perspective, this is the fundamental difference from “AI polishing” tools: Relay’s promise to users is that AI only restates your own experiences and will never add things you never did.
Whether that promise can be trusted does not depend on how well the prompt is written. It depends on whether there is runtime validation as a backstop.
7. API Layer: Middleware-First Design
Relay’s API layer is built on Hono + Bun, but the more important story is not the framework choice — it is how the middleware is composed.
7.1 Core Middleware Stack
app.use(
security(), // CORS allowlist + CSP + 1MB body limit
requestId(), // Auto-inject UUID trace ID
rateLimiter(), // Redis sliding window rate limit (per IP)
auth(), // JWT validation + X-User-Id header
idempotency(), // 24h duplicate request dedup (Redis)
validation(), // Zod unified validation (body + query)
)
The idempotency middleware is the most interesting design here. The frontend attaches an Idempotency-Key header on retries (typically a request UUID). The server caches the first response in Redis for 24 hours. Subsequent requests with the same key return the cached result without triggering business logic.
This is especially important for Agent systems: if a user approves a HITL checkpoint and a network hiccup causes the frontend to retry, without idempotency the same application could be submitted twice.
7.2 IDOR Protection Matrix
Relay has a dedicated routes/idor.test.ts file with 15 IDOR (Insecure Direct Object Reference) test scenarios:
// User A attempts to access User B's resume
test("GET /resumes/:id — cannot access another user's resume", async () => {
const { id } = await createResumeForUserB()
const res = await request(app)
.get(`/api/resumes/${id}`)
.set("Authorization", `Bearer ${tokenA}`)
expect(res.status).toBe(403)
})
For a system handling resumes, cover letters, and interview records, IDOR protection is not optional. The 15-case matrix covers combinations of different resource types and different roles, providing a continuous regression baseline.
8. Data Model: Schema Designed for Agent Systems
Relay’s database has 17 tables. Here are three designs with specific Agent-oriented characteristics.
8.1 Dual-Track Resume Model
-- resumes table has a track axis
ALTER TABLE resumes ADD COLUMN track text NOT NULL DEFAULT 'original'
CHECK (track IN ('original', 'optimized', 'tailored'));
-- Original resumes are immutable (trigger protection)
CREATE TRIGGER prevent_original_mutation
BEFORE UPDATE ON resumes
FOR EACH ROW
WHEN (OLD.track = 'original')
EXECUTE FUNCTION raise_mutation_error();
Three-track logic:
original: what the user uploaded, never modifiable (trust contract)optimized: AI’s general optimization of the originaltailored: a version customized for a specific JD (per-job)
Each bullet point has a stable bullet_index, enabling line-by-line diff editing. This is the gap between “AI edited your resume” and “you know exactly what AI changed.”
8.2 Agent Task Audit Table
CREATE TABLE agent_tasks (
id uuid DEFAULT gen_random_uuid() PRIMARY KEY,
user_id uuid NOT NULL REFERENCES users(id),
agent_name text NOT NULL,
action text NOT NULL,
payload jsonb,
-- HITL fields
hitl_action text,
hitl_payload jsonb,
hitl_decision text, -- 'approve' | 'reject' | 'modify'
decided_at timestamptz,
-- Cost tracking
cost_cents numeric(10,4),
tokens_in int,
tokens_out int,
-- Status
status text DEFAULT 'pending',
error text,
started_at timestamptz DEFAULT now(),
ended_at timestamptz
);
This table does two things:
- Audit log: every Agent action is recorded and traceable
- HITL state:
hitl_decision+decided_atrecords the user’s approval result for each action
This gives a reliable answer to “why did the Agent take this action.”
8.3 pgvector Semantic Matching
-- jobs table has an embedding column
ALTER TABLE jobs ADD COLUMN embedding vector(1536);
CREATE INDEX jobs_embedding_idx ON jobs USING ivfflat (embedding vector_cosine_ops);
-- Match query
SELECT j.*, 1 - (j.embedding <=> $1) as score
FROM jobs j
WHERE 1 - (j.embedding <=> $1) > 0.7
ORDER BY score DESC
LIMIT 20;
JobMatchAgent generates embeddings after scraping new positions and uses cosine similarity for semantic matching. Match model weights: skills (45%) + level (25%) + location (20%) + salary (10%).
Pure vector search plus weighted scoring outperforms keyword matching on both recall and precision.
9. The Harness Layer: Engineering Wrapper Around LangGraph
Relay wraps a layer called the “Harness” around LangGraph. This is the most production-minded design in the entire Python Agent layer.
+-------------------------------------------------+
| Relay Harness (business logic layer) |
| - Cost tracking + token budget |
| - Loop Guards (runaway prevention) |
| - Context Window management (auto-compress) |
| - Audit logging (async insert agent_tasks) |
| - Permission system (AUTO/NOTIFY/APPROVE/BLOCK) |
+-------------------------------------------------+
| LangGraph (underlying engine) |
| - create_react_agent ReAct loop |
| - StateGraph + interrupt HITL |
| - PostgresSaver checkpointer |
+-------------------------------------------------+
9.1 Loop Guards
One of the biggest engineering risks in Agent systems is runaway loops — an Agent spiraling into tool calls until tokens are exhausted or the bill explodes.
Relay’s Loop Guards:
GUARDS = {
"max_iterations": 20, # Over 20 rounds: force summarize and stop
"token_budget": 80_000, # Over 80k tokens: compress history
"cost_limit_cents": 50.0, # Over $0.50: pause and notify user
"timeout_seconds": 300, # Over 5 minutes: abort
"consecutive_errors": 3, # 3 consecutive errors: abort
}
max_iterations is enforced via LangGraph’s recursion_limit=40 (double the actual limit as a buffer). The Harness catches the resulting GraphRecursionError, generates a summary, and exits gracefully.
9.2 Context Window Compression
When a session’s token usage exceeds 60k, older conversation history is automatically compressed:
async def compress_if_needed(state: CoordinatorState) -> CoordinatorState:
total_tokens = sum(count_tokens(m) for m in state["messages"])
if total_tokens < 60_000:
return state
messages = state["messages"]
recent = messages[-10:] # Keep most recent 5 turns (user + assistant each)
old = messages[:-10]
summary = await summarize(old) # V4Flash compresses old history
return {
**state,
"messages": [SystemMessage(summary)] + recent,
}
This design lets the Coordinator maintain very long sessions — helping you find a job might span weeks — without crashing from context window overflow.
9.3 Audit Context Manager
@asynccontextmanager
async def audit(user_id: UUID, agent: str, action: str):
task_id = uuid4()
try:
yield
# Write asynchronously — does not block the main flow
asyncio.create_task(
insert_agent_task(task_id, user_id, agent, action, "success")
)
except Exception as e:
asyncio.create_task(
insert_agent_task(task_id, user_id, agent, action, "error", error=str(e))
)
raise
# Usage
async with audit(user_id, "resume_agent", "parse"):
result = await parse_resume(raw_text)
asyncio.create_task() is the key: writing the audit log does not block the main flow but guarantees eventual consistent writes.
10. Client-Side Delivery: The Core Differentiating Architecture
Relay has what it calls its “core differentiator”: applications happen in the user’s own browser, not on Relay’s servers.
10.1 Why Not Build Server-Side Auto-Apply
Server-side auto-apply has three systemic risks:
- Account bans: unfamiliar IP + unfamiliar device fingerprint is easily detected by ATS platforms
- Credential security: storing users’ ATS account passwords is a security nightmare
- CAPTCHA arms race: an endless maintenance loop with no exit
Client-side execution fundamentally bypasses all three: the user’s own browser, own IP, own authenticated session — platforms cannot distinguish “manual application” from “AI-assisted application.”
10.2 Three-Layer Delivery Architecture
Layer 1 (~70% of fields): Local rules engine
Common fields (name / email / phone / company / title) -- direct mapping, $0 cost
Layer 2 (~25% of fields): Cloud LLM field mapping
POST /api/map-fields
in: { unknown_field: "current_compensation_type", user_profile }
out: { field -> value }
Cost ~$0.001 / job
Layer 3 (~5% of fields): Cloud LLM open-ended questions
POST /api/answer-q
in: { question, jd, resume }
out: personalized_answer
Cost ~$0.002 / job
Total LLM cost per application is approximately $0.003, implying a theoretical gross margin near 98% on a $15/month subscription.
10.3 Plan B+: Playwright MCP Chrome Extension
The longer-term design is to let the server-side Agent operate the user’s already-logged-in browser directly via MCP:
Server Agent (LangGraph) <-- MCP --> Playwright MCP Chrome Extension
- Connect to user's logged-in ATS tab
- accessibility snapshot (structured DOM)
- Fill fields (visible to user)
- User personally clicks Submit
Playwright’s accessibility snapshot converts any page into a tree representation an Agent can understand, letting the Agent handle ATS forms it has never seen before. This is the most elegant “AI form-filling” architecture currently known: the browser extension needs no DOM manipulation code, and the Agent side needs no ATS-specific adapters.
11. Data Flywheel: The Mechanism That Gets Better With Use
Relay’s product moat is not the single-session experience — it is the data flywheel, the mechanism by which the system improves as more users use it.
11.1 InterviewAgent Crowdsourced Question Bank
User A completes a Google L5 backend interview
-> records questions + answers + AI evaluation
User B also does a Google L5 backend interview
-> system surfaces "related real questions"
User C opts into crowdsourcing
-> aggregated insight: "top 10 questions at Google L5 backend"
With each new user, the interview question bank becomes richer. This is classic network effects — applied to knowledge accumulation rather than social graphs.
11.2 Event-Driven Cross-Agent Coordination
Resume updated -> 'resume:updated' event
|
v
JobMatchAgent subscribes -> recompute all open job matches
|
v
'job:matched' event -> real-time frontend notification
Job scraped -> 'job:created' event
|
v
JobMatchAgent -> find matching users
|
v
Notification Service -> push message
This event-driven architecture decouples the agents — no direct calls, only event subscriptions. Each Agent grows independently and subscribes independently to the events it cares about.
11.3 TrendAgent Personalized Skill Gaps
At 2:00 AM daily, TrendAgent extracts skill requirements from job data, compares against the user’s resume, and generates a personalized gap report:
"Top 5 backend job demands this week:
Rust +34% (your resume: none)
Ray/distributed training +28% (your resume: some related experience)
Graph RAG +22% (your resume: none)
Suggestion: add a Rust side project bullet -- could match 23 more roles."
This turns trend data into actionable personal recommendations rather than just a market report.
12. A Design Checklist for Agent Engineers
From Relay’s architecture I have distilled several design decision points you can apply to your own projects:
12.1 Four Dimensions for Splitting Agents
Before deciding how many agents to create, ask these four questions:
- Are trigger modes different? (user interaction vs cron vs event subscription)
- Do model tier requirements conflict? (reasoning vs general-purpose vs batch)
- Is there an independently growing data flywheel?
- Are prompt evolution cadences different?
If any one of these is “yes,” the split has a valid justification.
12.2 Three Requirements for HITL
HITL is not as simple as adding a “Confirm” button. You need:
- Persistent checkpointer: paused state must be recoverable across processes and across time
- Sufficient context: users see not just “approve/reject” but “what the Agent wants to do and with what parameters”
- Support for modification: users should be able to modify parameters before approving
12.3 Three Layers of Cost Engineering
- Precise tracking: down to session level and individual API call level
- Tiering: different complexity tasks use different model tiers
- Ceiling: set a per-session cost cap with dynamic downgrade
12.4 Runtime Validation Over Prompt Constraints
For any “AI should not do X” requirement, first ask: “Is there runtime validation as a backstop?”
Prompt constraints are probabilistic. Runtime validation is deterministic. Use both, but runtime validation is the last line of defense.
12.5 Audit Logs Are Infrastructure, Not Debugging Tools
Not optional:
- Every Agent action: log when, what, how many tokens, how much cost
- Every HITL decision: log what the user approved, rejected, or modified
- Every error: log which Guard triggered and why
Without audit logs, an Agent system is a black box. When something goes wrong, there is no trail to follow.
13. Current Status and Open-Source Value
Relay’s current completion:
- Infrastructure (database, Redis, MinIO): complete
- TypeScript API layer: ~30% (endpoint stubs + middleware complete)
- Next.js web layer: ~35% (core page prototypes + design system complete)
- Python Agent layer: 0% (architecture design complete, code not started)
- Browser extension: 0%
The Agent layer code has not been started — but the design documentation is extremely complete. For anyone who wants to deeply understand multi-agent system architecture, this is a rare opportunity: design intent is clear and unspoiled by historical implementation details.
Project: github.com/cubxxw/apply-agent
The docs/architecture/ directory contains five systematic architecture documents covering the system overview, Agent architecture, Harness design, client-side delivery approach, and data model. If you are designing a similar Agent system, these are worth reading carefully.
Conclusion
The scarcest resource in Agent engineering right now is not intelligence — it is accumulated production engineering: how to prevent runaway loops, how to control costs, how to backstop AI mistakes, how to maintain user trust in the system.
Every architectural choice in Relay — the HITL interrupt design, the fabrication guard’s runtime validation, the three-tier LLM router, the Dual-Track resume model — answers a specific production problem. None of them are chasing the latest framework feature.
That “production-problem-driven architecture” mindset is what I believe is the most valuable thing to learn from this project.
This article was written based on Relay’s public code and architecture documentation. If you are building an Agent system, feel free to explore the project repo and consider contributing. The architecture design is open, and the code is waiting to be written.
Responses