title: ‘In-depth understanding of Kubernetes and other components ETCD’ ShowRssButtonInSectionTermList: true cover.image: date : 2023-09-26T12:03:38+08:00 draft : false showtoc: true tocopen: false type: posts author: [“Xinwei Xiong”, “Me”] keywords: [“kubernetes”, “etcd”, “raft”, “go”] tags:
- blog
- kubernetes
- etcd -raft -go categories:
- Development
- Blog
- Kubernetes description: > This article will explain ETCD and Raft in depth and throughout. And analyze ETCD in depth from the perspective of Kubernetes.
Before starting
ETCD is the hardest of all components in Kubernetes because ETCD is stateful, not stateless.
When I was doing k3s runtime design before, I learned some concepts about ETCD and Raft algorithms. As a prelude to knowledge, please go to [ETCD](https://docker.nsddd.top/Cloud-Native-k8s/24 .html) and Raft algorithm for prelude learning.
**This article will explain ETCD and Raft in depth and throughout. And analyze ETCD in depth from the perspective of Kubernetes. **
##ETCD
introduce
Etcd is a distributed key-value storage developed by CoreOS based on Raft. It can be used for service discovery, shared configuration and consistency guarantee (such as database master selection, distributed locks, etc.).
The included functions and features have all been learned in the Prelude. Let’s take a look at the storage that Kubernetes is most concerned about:
The main function
- Basic key-value storage
- Monitoring mechanism
- Key expiration and renewal mechanism for monitoring and service discovery
- Atomic Compare And Swap and Compare And Delete, used for distributed locks and leader election
scenes to be used
- Can be used for key-value storage, applications can read and write data in etcd
- The most common application scenarios of etcd are for service registration and discovery.
- Distributed asynchronous system based on listening mechanism
etcd is a key-value storage component, and other applications are based on its key-value storage function.
- Uses kv type data storage, which is generally faster than relational databases.
- Supports dynamic storage (memory) and static storage (disk).
- Distributed storage, which can be integrated into a multi-node cluster.
- Storage method, using a similar directory structure. (B+tree)
- Only leaf nodes can actually store data, which is equivalent to files.
- The parent node of the leaf node must be a directory, and the directory cannot store data.
Service registration and discovery:
- Strong consistency and high availability service storage directory.
- etcd based on the Raft algorithm is inherently a service storage directory with strong consistency and high availability.
- A mechanism for registering services and service health.
- Users can register services in etcd, configure key TTL for the registered service, and regularly maintain the heartbeat of the service to monitor the health status.
Message publishing and subscription:
- In a distributed system, the most suitable communication method between components is message publishing and subscription.
- That is to build a configuration sharing center. Data providers publish messages in this configuration center, and message consumers subscribe to the topics they care about. Once a message is published on the topic, subscribers will be notified in real time.
- In this way, centralized management and dynamic updating of distributed system configurations can be achieved.
- Some configuration information used in the application is placed on etcd for centralized management.
- The application actively obtains the configuration information from etcd when it starts. At the same time, it registers a Watcher on the etcd node and waits. Every time the configuration is updated in the future, etcd will notify the subscribers in real time, so as to obtain the latest configuration information. Purpose.
install
ETCD_VER=v3.4.17
DOWNLOAD_URL=https://github.com/etcd-io/etcd/releases/download
rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
rm -rf /tmp/etcd-download-test && mkdir -p /tmp/etcd-download-test
curl -L ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -o /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
tar xzvf /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz -C /tmp/etcd-download-test --strip-components=1
rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
rm -rf /tmp/etcd-download-test
start up
It should be noted that ETCD has been installed locally when I installed Kubernetes. There are two solutions to this problem:
- Use the flag to specify the port and change the port
- Uninstall, reinstall
ONE:
etcd --listen-client-urls 'http://localhost:12379' \
--advertise-client-urls 'http://localhost:12379' \
--listen-peer-urls 'http://localhost:12380' \
--initial-advertise-peer-urls 'http://localhost:12380' \
--initial-cluster 'default=http://localhost:12380'
Demo
View cluster members:

Some simple operations:
There are many cases in the preface, please move on~
# data input
etcdctl --endpoints=localhost:12379 put /key1 val1
# Query data
etcdctl --endpoints=localhost:12379 get /key1
# Query data-display detailed information
etcdctl --endpoints=localhost:12379 get /key1 -w json
# Query data by key prefix
etcdctl --endpoints=localhost:12379 get --prefix /
# Show only key values
etcdctl --endpoints=localhost:12379 get --prefix / --keys-only
# watch data
etcdctl --endpoints=localhost:12379 watch --prefix /
Please be aware of:
watch provides a long connection to monitor changes in events, and will receive subscriptions if changes occur.
❯ etcdctl --endpoints=localhost:12379 watch --prefix / --rev 0
PUT
/key
val3
route plan
**Yes, when we talked about the source code directory structure of Kubernetes earlier, we explained: the API in the Kubernetes directory, and said that the API complies with the RESTful API standard, and the version identifier is usually placed in the URL, such as /v1/users, the advantage of this is that it is very intuitive. **
GKV design is like this~
ETCD supports path matching:
❯ etcdctl --endpoints=localhost:12379 get a
❯ etcdctl --endpoints=localhost:12379 put a
^C
❯ etcdctl --endpoints=localhost:12379 put a 1
OK
❯ etcdctl --endpoints=localhost:12379 put b 2
OK
❯ etcdctl --endpoints=localhost:12379 put /a 11
OK
❯ etcdctl --endpoints=localhost:12379 put /b 22
OK
❯ etcdctl --endpoints=localhost:12379 put /a/b 1122
OK
❯ etcdctl --endpoints=localhost:12379 get --prefix /
/a
11
/a/b
1122
/b
twenty two
/key
val3
/sd
as
❯ etcdctl --endpoints=localhost:12379 get --prefix /a
/a
11
/a/b
1122
❯ etcdctl --endpoints=localhost:12379 get --prefix /b
/b
twenty two
**All of the above have values, but we also know that the data value of Kubernetes’s Api is very large, and it is a yaml file one by one, so we can filter out the key: **
❯ etcdctl --endpoints=localhost:12379 get --prefix / --keys-only
/a
/a/b
/b
/key
/sd
**We can add the debug parameter to see the command details and debugging information: **
❯ etcdctl --endpoints=localhost:12379 get --prefix / --keys-only --debug
Core: TTL & CAS
TTL (time to live) refers to setting a validity period for a key. After expiration, the key will be automatically deleted. This is used in many distributed lock implementations to ensure the real-time effectiveness of the lock.
But from the perspective of Kubernetes, not many people use TTL, so ~
Atomic Compare-and-Swap (CAS) means that when assigning a key, the client needs to provide some conditions. When these conditions are met, the assignment can be successful. These conditions include:
prevExist: whether key exists before current assignmentprevValue: the value of key before the current assignmentprevIndex: Index before key is currently assigned
In this case, the setting of the key is prerequisite, and you need to know the current specific situation of the key before you can set it.
Kubernetes interacts with ETCD
kubectl get pod -A
kubectl exec -it etcd-cadmin sh # etcd has sh but no bash
Raft protocol
The Raft protocol is based on the quorum mechanism, which is the principle of majority consent. Any change needs to be confirmed by more than half of the members.
Recommended viewing: Raft protocol animation
Learner
New roles introduced in Raft 4.2.1
When an etcd cluster appears and needs to add nodesAt this time, the data difference between the new node and the leader is large, and more data synchronization is required to keep up with the latest data of the leader.
At this time, the leader’s network bandwidth is likely to be exhausted, which makes the leader unable to maintain the heartbeat normally. This in turn causes the follower to reinitiate voting. This may cause the etcd cluster to become unavailable.
That is: adding members to the etcd cluster will have a great impact on the stability of the cluster.
Therefore, the learner role was added. The nodes that join the cluster in this role do not participate in voting and receive the replication message from the leader until they are synchronized with the leader.
**The Learner role only receives data but does not participate in voting, nor does it provide read and write services. Therefore, when adding learner nodes, the quorum of the cluster remains unchanged. **
Cluster administrators should minimize unnecessary operations when adding new nodes to the cluster. You can add a learner node to the etcd cluster through the member add --learner command. It does not participate in voting and only receives replication messages.
After the Learner node is synchronized with the leader, the status of the node can be promoted to a follower through member promote, and then it will be included in the size of the quorum.
etcd’s consistency based on Raft
Election method:
- During initial startup, the node is in the
followerstate and is set with an election timeout. If no heartbeat is received from the leader within this time period, the node will initiate an election: after switching itself to candidate, Send a request to other follower nodes in the cluster to ask them whether to elect themselves as the leader. - After receiving the acceptance vote from more than half of the nodes in the cluster, the node becomes the leader and begins to receive and save client data and synchronize logs to other follower nodes. If no consensus is reached, the candidate randomly selects a waiting interval (150ms ~ 300ms) to initiate voting again. The candidate that is accepted by more than half of the followers in the cluster will become the leader.
- The leader node relies on regularly sending heartbeats to followers to maintain its status.
- If at any time other followers do not receive a heartbeat from the leader during the election timeout, they will also switch their status to candidate and initiate an election. For each successful election, the term of the new leader will be one greater than the term of the previous leader. **
Log replication
When the Leader receives the client’s log (transaction request), it first appends the log to the local Log, and then synchronizes the Entry to other Followers through heartbeat. The Follower records the log after receiving the log. Then send ACK to the Leader. When the Leader receives the ACK information from most (n/2+1) Followers, it sets the log as submitted and appends it to the local disk, notifies the client and sends it to the Leader in the next heartbeat All Followers` will be notified to store the log in their local disks.
safety
Security is a security mechanism used to ensure that each node executes the same sequence. For example, when a follower becomes unavailable during the current leader commit log, the follower may be elected as leader again later, and then the new leader A new Log may be used to overwrite the previously committed Log, which causes the node to execute different sequences; Safety is a mechanism used to ensure that the elected Leader must contain the previously committed Log; Election Safety: Each term ( Term) can only elect one Leader. Leader Completeness (Leader Completeness): refers to the integrity of the Leader log. When the Log is Commited in Term 1, then the Leader in subsequent terms Term 2, Term 3, etc. must contain the Log; Raft is in the election phase. The judgment of using Term is used to ensure integrity: when the Term of the Candidate requested to vote is larger or the Term has the same Index and is larger, vote, otherwise the request is rejected.
Failure handling
Leader failure: Other nodes that have not received heartbeat will initiate a new election, and when the leader recovers, it will automatically become a follower due to the small number of steps (the log will also be overwritten by the new leader’s log)
The follower node is unavailable: The situation where the follower node is unavailable is relatively easy to solve. Because the log content in the cluster is always synchronized from the leader node, as long as this node joins the cluster again, it can copy the log from the leader node again.
Multiple candidates: After the conflict, the candidate will randomly select a waiting interval (150ms ~ 300ms) to initiate voting again. The candidate accepted by more than half of the followers in the cluster will become the leader.
wal log
The wal log is binary, and after parsing it is the above data structure LogEntry. The first field, type, has only two types,
- One is 0 representing
Normal, 1 representing ConfChange (ConfChange represents the synchronization of configuration changes of Etcd itself, such as new nodes joining, etc.). - The second field is
term. Each term represents the term of a master node. The term will change every time the master node changes. - The third field is
index. This serial number is strictly sequentially increasing and represents the change serial number. - The fourth field is binary data, which saves the entire pb structure of the raft request object.
There is tools/etcddump-logs under the etcd source code, which can dump the wal log into text for viewing, and can assist in analyzing the Raft protocol.
The Raft protocol itself does not care about the application data, that is, the part in the data. Consistency is achieved by synchronizing the wal log. Each node applies the data received from the master node to local storage. Raft only cares about the synchronization status of the log. If there is a bug in the local storage implementation, for example, data is not correctly applied locally, it may also lead to data inconsistency.
Storage mechanism
The etcd v3 store is divided into two parts. One part is the in-memory index, kvindex, which is implemented based on a Golang btree open sourced by Google, and the other part is the back-end storage. According to its design, backend can connect to a variety of storages, currently using boltdb. Boltdb is a stand-alone kv storage that supports transactions. etcd transactions are implemented based on boltdb transactions. The key stored by etcd in boltdb is reversion, and the value is etcd’s own key-value combination. That is to say, etcd will save each version in boltdb, thereby realizing a multi-version mechanism.
Reversion mainly consists of two parts. The first part is main rev, which is incremented by one for each transaction. The second part is sub rev, which is incremented by one for each operation in the same transaction.
etcd provides commands and setting options to control compact, and supports put operation parameters to precisely control the number of historical versions of a certain key.
The memory kvindex saves the mapping relationship between key and revision, which is used to speed up queries.
Watch mechanism
watcherGroup is the grouping mechanism of Watchers in ETCD, which can be used to manage Watchers more effectively and prevent Watchers from consuming too many resources.
When using watcherGroup, you can create multiple Watchers and assign them to different watcherGroups. There is an Event loop inside each watcherGroup, which is responsible for processing event notifications of Watchers in the group. Through the grouping mechanism, Watcher can respond to data changes in storage more efficiently, thereby reducing the consumption of ETCD cluster resources.
watcherGroup can be created in the following ways:
goCopy code
wg := clientv3.NewWatcher(watchCli).Watchers()
The above code creates a WatcherGroup wg that is associated with the ETCD client watchCli. A Watcher can be added to a WatcherGroup using the following code:
goCopy code
watcher := wg.NewWatcher()
This will create a new Watcher and add it to the WatcherGroup. When you create a Watcher, you can specify the keys or prefixes that the Watcher wants to monitor, as well as the Watcher’s response behavior (such as direct triggering or batch triggering).
When using watcherGroup, Watchers can also be managed in groups. A Watcher can be added to a specified watcherGroup using the following code:
goCopy codewg.Group("group1").Add(watcher1)
wg.Group("group2").Add(watcher2)
This will add watcher1 to a WatcherGroup named “group1” and watcher2 to a WatcherGroup named “group2”.
By using watcherGroup, you can better manage Watchers and improve the performance and scalability of your ETCD cluster.
ETCD request flow chart
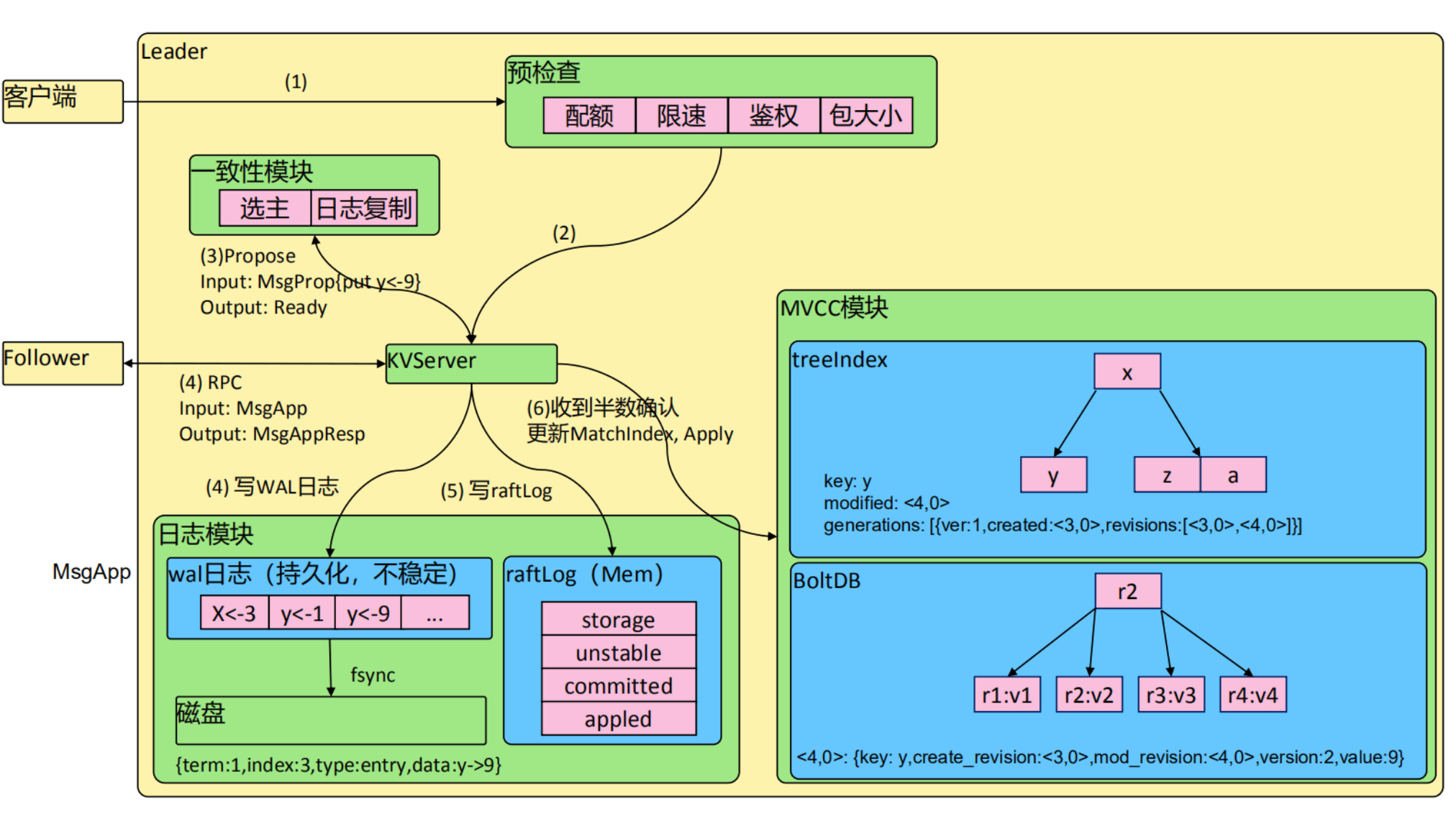
MVCC module
Kubernetes API Server does not provide a caching mechanism by default. It always reads the latest data from etcd and returns it to the client. This is because etcd, as the storage backend of Kubernetes, already has high availability and reliability guarantees, so the API Server can directly read data from etcd to ensure data consistency and reliability.
However, since the performance of etcd is relatively poor and can easily become a bottleneck in high concurrency situations, caching needs to be used in some scenarios to optimize the performance of the API Server. To this end, Kubernetes provides a component called kube-aggregator, which can build a layer of cache in front of the API Server to improve the performance and scalability of the API Server.
kube-aggregator is actually an API aggregator, which can aggregate requests from multiple API Servers and provide functions such as caching and load balancing. kube-aggregator can cache the data returned by the API Server locally and update the data regularly as needed. In this way, under high concurrency conditions, the API Server can read data directly from the local cache, avoiding frequent access to etcd, thus improving the performance and stability of the system.
The client sends a request to etcd.
The client can send a request to ETCD through the API provided by ETCD. The request can be a read operation or a write operation.
The request is first received by ETCD’s network layer.
When a request reaches the ETCD server, it is first received and processed by the network layer. The network layer of ETCD uses the gRPC protocol for communication, which can ensure the reliability and efficiency of requests.
Then, ETCD will send the request to its internal Raft layer.
ETCD uses the Raft algorithm internally to achieve distributed consistency, and all data is stored in the Raft layer. When the request reaches the Raft layer, the Raft layer will process it according to the current cluster status and forward the request to the appropriate node for processing.
The Raft layer will process the request. If it is a read operation, the data will be returned. If it is a write operation, the data will be written to the storage engine.
When the request reaches the target node, the Raft layer will process it according to the type of request. If it is a read operation, the Raft layer will read the data from the storage engine and return it to the client; if it is a write operation, the Raft layer will write the data to the storage engine and wait for the storage engine to return a successful response.
The storage engine writes the data to disk and returns a successful response.
The storage engine is the underlying data storage layer of ETCD, which uses the LSM tree storage engine. When the storage engine receives the write request, it writes the data into the memory.In the MemTable, when the MemTable is full, the SSTable file will be generated and written to the disk. After writing to the disk, the storage engine will return a successful response to the Raft layer.
The Raft layer returns the response to ETCD’s network layer.
When the Raft layer receives a successful response from the storage engine, it will return the response to the ETCD network layer for processing. The network layer will encapsulate the response and return it to the client through the gRPC protocol.
Finally, etcd’s network layer sends the response back to the client. When the network layer receives the response returned by the Raft layer, it will unpack it and return it to the client to complete the entire request processing process.
Related parameters
Important parameters of etcd members
Member related parameters
--name 'default'- Human-readable name for this member.
--data-dir '${name}.etcd'- Path to the data directory.
--listen-peer-urls 'http://localhost:2380'- List of URLs to listen on for peer traffic.
--listen-client-urls 'http://localhost:2379'- List of URLs to listen on for client traffic.
Important parameters of etcd cluster
Cluster related parameters
--initial-advertise-peer-urls 'http://localhost:2380'- List of this member’s peer URLs to advertise to the rest of the cluster.
--initial-cluster 'default=http://localhost:2380'- Initial cluster configuration for bootstrapping.
--initial-cluster-state 'new'- Initial cluster state (‘new’ or ‘existing’).
--initial-cluster-token 'etcd-cluster'- Initial cluster token for the etcd cluster during bootstrap.
--advertise-client-urls 'http://localhost:2379'- List of this member’s client URLs to advertise to the public.
etcd security related parameters
--cert-file ''- Path to the client server TLS cert file.
--key-file ''- Path to the client server TLS key file.
--client-crl-file ''- Path to the client certificate revocation list file.
--trusted-ca-file ''- Path to the client server TLS trusted CA cert file.
--peer-cert-file ''- Path to the peer server TLS cert file.
--peer-key-file ''- Path to the peer server TLS key file.
--peer-trusted-ca-file ''- Path to the peer server TLS trusted CA file.
Disaster Recovery
Create Snapshot:
etcdctl --endpoints https://127.0.0.1:3379 --cert /tmp/etcd-certs/certs/127.0.0.1.pem --key /tmp/etcd-certs/certs/127.0.0.1-key.pem - -cacert /tmp/etcd-certs/certs/ca.pem snapshot save snapshot.db
Data recovery:
etcdctl snapshot restore snapshot.db \
--name infra2 \
--data-dir=/tmp/etcd/infra2 \
--initial-cluster infra0=http://127.0.0.1:3380,infra1=http://127.0.0.1:4380,infra2=http://127.0.0.1:5380 \
--initial-cluster-token etcd-cluster-1 \
--initial-advertise-peer-urls http://127.0.0.1:5380
Capacity Management
Storage Recommendations:
It is not recommended that a single object exceed 1.5M
Default capacity 2G
It is not recommended to exceed 8G
Alarm & Disarm Alarm
When the etcd capacity is full, an alarm will appear. When the alarm exists, etcd cannot process the write request.
Set etcd storage threshold
etcd --quota-backend-bytes=$((16*1024*1024))
Infinite loop, simulating disk overwrite
while [ 1 ]; do dd if=/dev/urandom bs=1024 count=1024 | ETCDCTL_API=3 etcdctl put key || break; done
View endpoint status
ETCDCTL_API=3 etcdctl --write-out=table endpoint status
View alarm
ETCDCTL_API=3 etcdctl alarm list
Clean up debris
ETCDCTL_API=3 etcdctl defrag
clear alarm
ETCDCTL_API=3 etcdctl alarm disarm
Defragmentation
Set compression every hour
etcd --auto-compaction-retention=1
compact up to revision 3
etcdctl compact 3
Defragmentation
etcdctl defrag
Highly available etcd solution
The previous ETCD disaster preparedness is all manual, and any accident requires manual intervention. So, it’s very troublesome.
So is there an automatic way to achieve it?
etcd-operator: coreos
etcd-operator: coreos is open source and completes etcd cluster configuration based on kubernetes CRD. Archived
kubeadm is used as an initialization and needs to be installed manually.
https://github.com/coreos/etcd-operator
Etcd statefulset Helm chart: Bitnami(powered by vmware)
https://bitnami.com/stack/etcd/helm
https://github.com/bitnami/charts/blob/master/bitnami/etcd
Etcd Operator
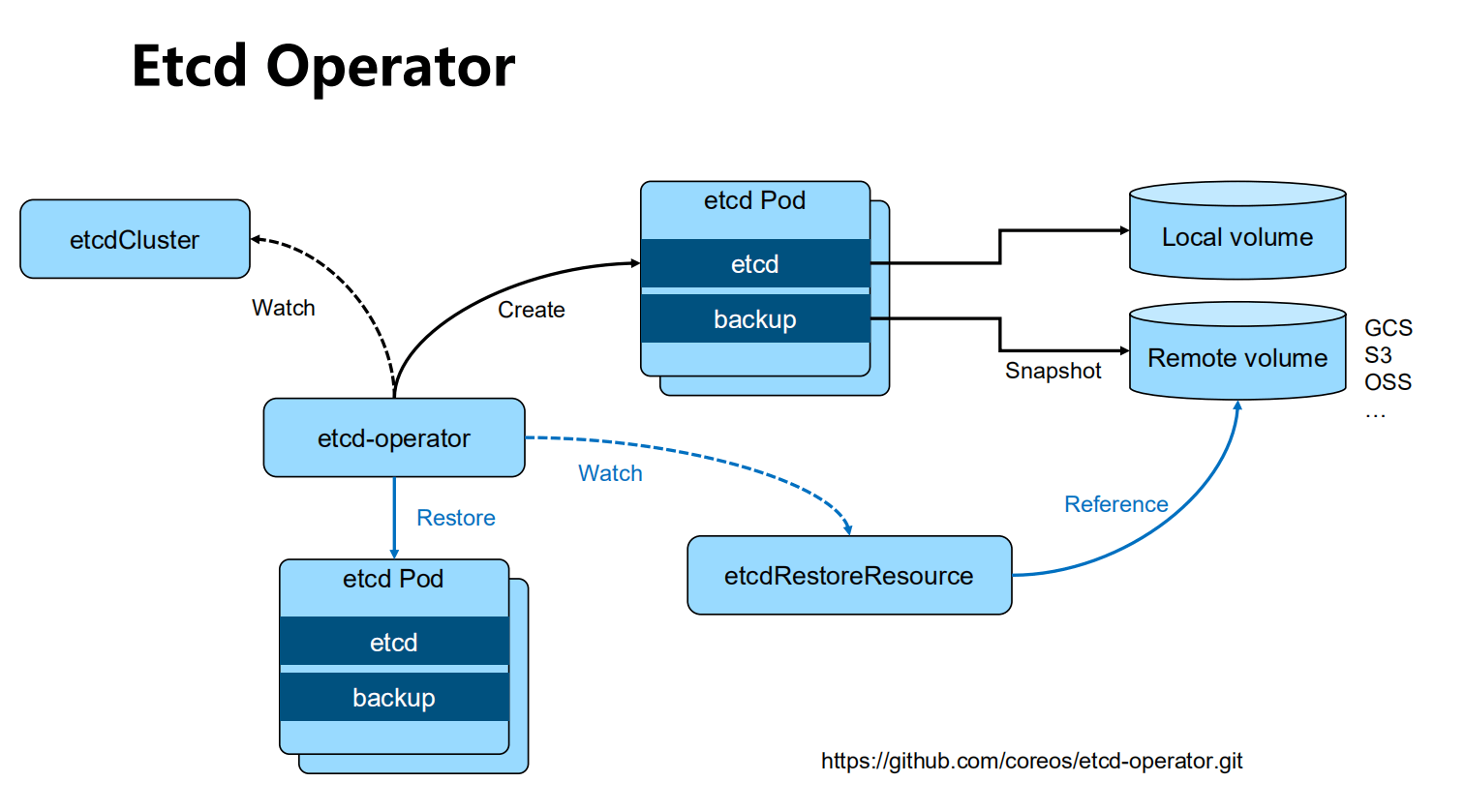
Install etcd high availability cluster based on Bitnami
Install helm
https://github.com/helm/helm/releases
Install etcd via helm
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install my-release bitnami/etcd
Interacting with the serve through the client
kubectl run my-release-etcd-client --restart='Never' --image docker.io/bitnami/etcd:3.5.0-debian-10-r94 --env ROOT_PASSWORD=$(kubectl get secret --namespace default my-release-etcd -o jsonpath="{.data.etcd-root-password}"|base64 --decode) --env ETCDCTL_ENDPOINTS="my-release etcd.default.svc.cluster.local:2379" -- namespace default --command --sleep infinity
How to use etcd in Kubernetes
etcd is the back-end storage of kubernetes. For each kubernetes Object, there is a corresponding storage.go responsible for the storage operation of the object.
- pkg/registry/core/pod/storage/storage.go
Specify etcd servers cluster in API server startup script
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=192.168.34.2
- --enable-bootstrap-token-auth=true
- --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt
- --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt
- --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key
- --etcd-servers=https://127.0.0.1:2379
In the early days, the API server performed a simple ping check on etcd to check whether the port was open, but now it has been changed to a real etcd api call.
A port connection does not necessarily mean that the service is normal.
The storage path of Kubernets objects in etcd
Enter etcd pod
kubectl -n kube-system exec -it etcd-cadmin sh
Use etcdctl in the container to make requests
ETCDCTL_API=3
alias ectl='etcdctl --endpoints https://127.0.0.1:2379 \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--cert /etc/kubernetes/pki/etcd/server.crt \
--key /etc/kubernetes/pki/etcd/server.key'
ectl get --prefix --keys-only /
etcd-servers-overrides
Certain objects in the k8s cluster will be created and deleted in large quantities, such as events. Creating a pod may have dozens of events, which will put great pressure on etcd. Therefore, apiserver provides the etcd-servers-overrides parameter. Run and then master etcd. In addition to the server, an etcd is provided to store objects that are not so important.
/usr/local/bin/kube-apiserver --etcd_servers=https://localhost:4001 --etcd-cafile=/etc/ssl/kubernetes/ca.crt--storage-backend=etcd3 --etcd-servers- overrides=/events#https://localhost:4002
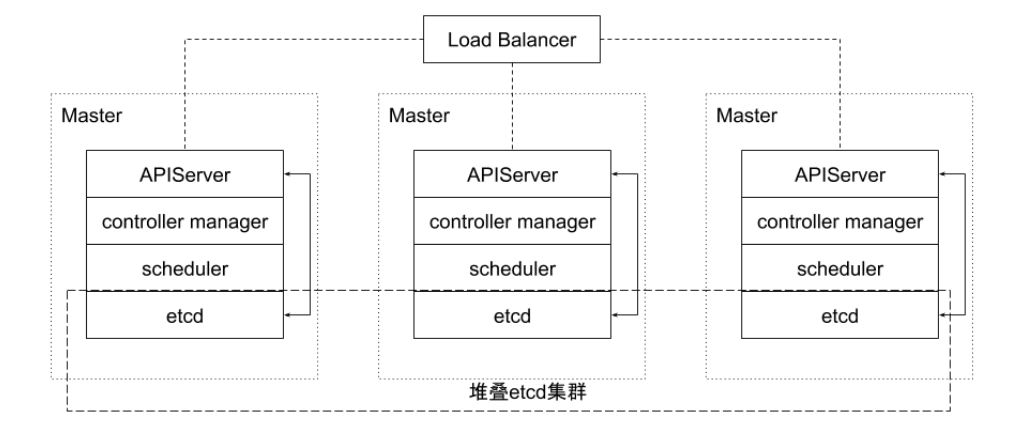
High availability topology of stacked etcd cluster
This topology couples control plane and etcd members on the same node.
The advantage is that it’s very easy to set up, and managing copies is easier. However, stacking carries the risk of coupling failure. If a node fails, both etcd members and control plane instances are lost, and cluster redundancy is compromised. This risk can be mitigated by adding more control plane nodes. Therefore, in order to achieve high availability of the cluster, at least three stacked Master nodes should be run.
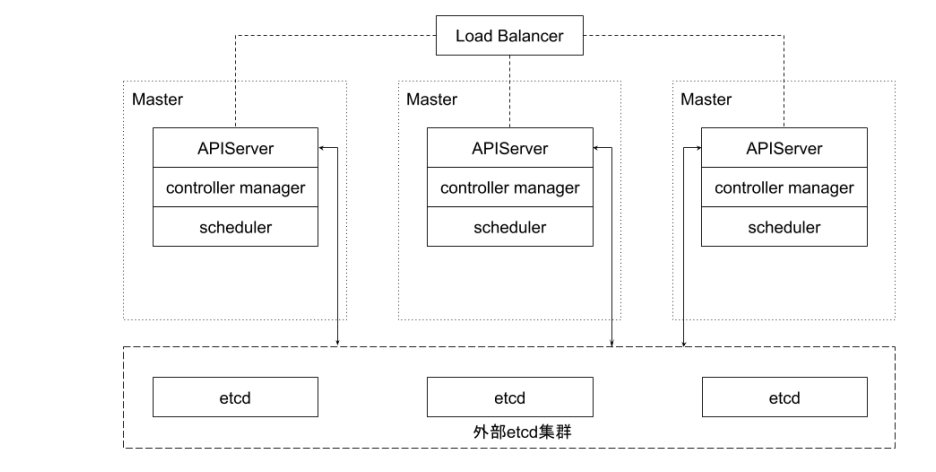
Highly available topology for external etcd cluster
This topology decouples the control plane and etcd members. If a Master node is lost, the impact on etcd members will be small, and it will not have as much impact on cluster redundancy as a stacked topology. However, this topology requires twice as many hosts as a stacked topology. A cluster with this topology requires at least three hosts for the control plane nodes and three hosts for the etcd cluster.
Practice-etcd cluster high availability
How many peers are most suitable?
*1? 3? 5?
Recommended 3 or 5 build environments
3 have higher performance, and the request only needs two nodes to confirm before it can be returned.
The problem with the 3rd problem is that operation and maintenance need to handle it immediately after a problem occurs. If it is not handled in time, if the second one also breaks down, the entire cluster will be useless.
If there are 5, two can be allowed to go bad, which can give operation and maintenance a little more buffer time.
It is recommended to use 5 in general production environments.
Ensuring high availability is the primary goal,
All write operations must go through the leader
Can having more peers improve the concurrency of cluster read operations?
- The apiserver configuration only connects to the local etcd peer
- The configuration of the apiserver specifies all etcd peers, but only if the currently connected etcd member is abnormal, the apiserver will change the target.
Do you need dynamic flex up?
- Under normal circumstances, etcd does not need to dynamically expand or shrink the capacity. If you plan it well, you will not have to move it.
Ensure efficient communication between apiserver and etcd
- apiserver and etcd are deployed on the same node
- The communication between apiserver and etcd is based on gRPC
- For each object, Connection -> stream sharing between apiserver and etcd
- Features of http2
*Stream quota
- Problems caused? For large-scale clusters, it will cause link congestion
- With 10,000 pods, the data returned by a list operation may exceed 100M
etcd storage planning
Local vs remote?
*Remote Storage
- The advantage is assumed to be always available. Is this really the case?
- The disadvantage is IO efficiency, what problems may it cause?
- Best Practices:
- Local SSD
- Use local volume to allocate space
How much space?
*Related to cluster size *Default 2G, generally no more than 8G.
Thinking: Why is the DB size of each member inconsistent?
safety
Communication encryption between peers
- Is there any demand?
*Additional overhead of TLS
- Increased operational complexity
data encryption
- Is there any demand?
- Kubernetes provides encryption for secrets
–etcd-servers-overrides
- For large-scale clusters, a large number of events will put pressure on etcd
- Specify the etcd servers cluster in the API server startup script
/usr/local/bin/kube-apiserver --etcd_servers=https://localhost:4001 --etcd-cafile=/etc/ssl/kubernetes/ca.crt--storage-backend=etcd3 --etcd-servers- overrides=/events#https://localhost:4002
Reduce network delay
The RTT within the data center is probably a few milliseconds, the typical RTT domestically is about 50ms, and the RTT between two continents may be as slow as 400ms. Therefore, it is recommended that etcd clusters be deployed in the same region as possible.
When there are too many concurrent connections from the client to the Leader, requests from other Follower nodes to the Leader may be delayed due to network congestion. On the Follower node, you may see errors like this:
dropped MsgProp to 247ae21ff9436b2d since streamMsg's sending buffer is full
This can be avoided by using the traffic control tool (Traffic Control) on the node to increase the priority of sending data between etcd members.
Reduce disk I/O latency
For disk latency, typical spinning disk write latency is about 10 milliseconds. For SSDs (Solid State Drives), latency is typically less than 1 millisecond. The latency of HDD (Hard Disk Drive) or network disk will be unstable when a large amount of data is read and written. Therefore it is strongly recommended to use SSD.
At the same time, in order to reduce the interference of I/O operations of other applications on etcd, it is recommended to store etcd data in a separate disk. Different types of objects can also be stored in several different etcd clusters. For example, frequently changing event objects can be separated from the main etcd cluster to ensure the high performance of the main cluster. This can be configured through parameters at the APIServer. It is best to have a separate storage disk for each of these etcd clusters.
If it is inevitable that etcd and other businesses share storage disks, then you need to set a higher disk I/O priority for the etcd service through the following ionice command to avoid the impact of other processes as much as possible.
ionice -c2 -n0 -p 'pgrep etcd'
Keep log file size reasonable
etcd saves data in the form of logs. Whether it is data creation or modification, it appends operations to the log file, so the log file size will grow linearly with the number of data modifications.
When the Kubernetes cluster is large in size, the data in the etcd cluster will be changed frequently, and the cluster log file will grow rapidly.
In order to effectively reduce the log file size, etcd will create snapshots at regular intervals to save the current state of the system and remove old log files. In addition, when the number of modifications accumulates to a certain number (the default is 10000, specified by the parameter “–snapshot-count”), etcd will also create snapshot files.
If the memory usage and disk usage of etcd are too high, you can first analyze whether the frequency of data writing is too high, causing the snapshot frequency to be too high. After confirmation, you can reduce its memory and disk usage by lowering the threshold for triggering snapshots.
Set reasonable storage quotas
Storage space quotas are used to control the size of etcd data space. Reasonable storage quotas ensure the reliability of cluster operations.
8G recommended.
If there is no storage quota, that is, etcd can use the entire disk space, etcd’s performance will seriously decline due to the continuous growth of storage space, and there is even a risk of running out of cluster disk space, leading to unpredictable cluster behavior. If the storage quota is set too small, once the storage space of the backend database of one of the nodes exceeds the storage quota, etcd will trigger a cluster-wide alarm and put the cluster into maintenance mode that only accepts read and delete requests. The cluster can resume normal operations only after sufficient space has been freed, the backend database has been de-fragmented, and storage quota alarms have been cleared.
Automatically compress historical versions
etcd saves historical versions for each key. In order to avoid performance problems or inability to write due to exhaustion of storage space, these historical versions need to be compressed periodically. Compressing historical versions means discarding all information before a given version of the key, and the space saved can be used for subsequent write operations. etcd supports automatic compression of historical versions. Specify the parameter –auto-compaction in the startup parameters, whose value is in hours. That is to say, etcd will automatically compress the historical version before the time window set by this value.
Regularly eliminate fragmentation
Compressing historical versions is equivalent to discretely erasing certain data in etcd storage space, and fragments will appear in etcd storage space. These fragments cannot be used by backend storage, but still occupy the node’s storage space. Therefore, regularly eliminating storage fragmentation will free up fragmented storage space and re-adjust the entire storage space.
Backup plan
Backup plan
etcd backup: backup complete cluster information, disaster recovery
- etcdctl snapshot save
Back up Kubernetes events
Frequency?
The time interval is too long:
- Can user data lost be accepted?
- If there are external resource configurations, such as load balancing, can leaks caused by data loss be accepted?
The time interval is too short:
- Impact on etcd
- When taking a snapshot, etcd will lock the current data
- Concurrent write operations require new space to be opened for incremental writing, resulting in disk space growth.
- Impact on etcd
How to ensure the timeliness of backup and prevent disk explosion?
- Auto defrag
Optimize operating parameters
When network latency and disk latency are fixed, etcd operating parameters can be optimized to improve cluster efficiency. etcd conducts Leader election based on the Raft protocol. Data read and write operations can only begin after the Leader is selected. Therefore, frequent Leader elections will cause a significant reduction in data read and write performance. You can reduce the possibility of Leader election by adjusting the heartbeat interval (Heatbeat Interval) and election timeout (Election Timeout).
The heartbeat cycle controls how often the Leader sends heartbeat notifications to Followers. In addition to indicating the active status of the Leader, the heartbeat notification also contains data information to be written. Followers write data based on the heartbeat information. The default heartbeat period is 100ms. The election timeout defines how long it takes for the Follower to reinitiate the election if it does not receive the Leader heartbeat. The default setting of this parameter is 1000ms.
If different instances of the etcd cluster are deployed in the same data center with low latency, the default configuration is usually sufficient. If different instances are deployed in multiple data centers or in a cluster environment with high network latency, the heartbeat period and election timeout need to be adjusted. It is recommended that the heartbeat cycle parameter be set close to the maximum value of the average data round-trip cycle between multiple etcd members, which is generally 0.55-1.5 times the average RTT. If the heartbeat period is set too low, etcd will send a lot of unnecessary heartbeat information, thereby increasing the burden on the CPU and network. If set too high, it will cause frequent election timeouts. The election timeout also needs to be set based on the average RTT time between etcd members. The election timeout is set to at least 10 times the RTT time between etcd members to prevent network fluctuations.
The values of the heartbeat interval and election timeout must be effective for all nodes in the same etcd cluster. If the configurations of each node are different, the negotiation results among cluster members will be unpredictable and unstable.
etcd backup storage
The default working directory of etcd will generate two subdirectories: wal and snap. wal is used to store prewrittenThe biggest function of the log is to record the entire process of data changes. All data modifications must be written to wal before submission.
snap is used to store snapshot data. In order to prevent too many wal files, etcd will create snapshots periodically (when the data in wal exceeds 10,000 records, set by the parameter “–snapshot-count”). When the snapshot is generated, the data in WAL can be deleted.
If the data is damaged or incorrectly modified and needs to be rolled back to a previous state, there are two methods:
- First, the data subject is restored from the snapshot, but the data that is not taken into the snapshot will be lost;
- The second is to perform all modification operations recorded in the WAL and restore the original data to the state before the data was damaged, but the recovery time is longer.
Backup solution practice
The officially recommended backup method for etcd cluster is to create snapshots regularly. Different from the purpose of regularly creating snapshots within etcd, this backup method relies on external programs to regularly create snapshots and upload the snapshots to network storage devices to achieve redundant backup of etcd data. Data uploaded to network devices should be encrypted. This allows the etcd cluster to recover anywhere from a known good point in time, even when all etcd instances have lost data. According to the cluster’s requirements for etcd backup granularity, the backup cycle can be appropriately adjusted. According to actual measurements in a production environment, taking snapshots usually affects the performance of the cluster at that time, so it is not recommended to create snapshots frequently. But if the backup cycle is too long, it may lead to the loss of a large amount of data.
Here you can use the incremental backup method. The backup program triggers a snapshot every 30 minutes. Then it starts from the version (Revision) where the snapshot ends, listens to the events of the etcd cluster, saves the events to a file every 10 seconds, and uploads the snapshot and event files to the network storage device. A 30-minute snapshot cycle has little impact on cluster performance. When a catastrophe strikes, at most 10 seconds of data will be lost. As for data restoration, the data is first downloaded from the network storage device, then large chunks of data are restored from the snapshot, and all stored events are applied sequentially on this basis. In this way, the cluster data can be restored to the time before the disaster occurred.
ResourceVersion
resourceVersion of a single object
- The last modified resourceVersion of the object
resourceVersion of the List object
- ResourceVersion when generating list response
List behavior
When using the List object, if resourceVersion is not added, it means that Most Recent data is required, and the request will penetrate the APIServer cache and be sent directly to etcd.
When APIServer filters object queries through Label, the filtering action is on the APIServer side, and APIServer needs to initiate a full query request to etcd.