The main film begins~
Kubernetes is an open source project initiated by the Google team. Its goal is to manage containers across multiple hosts and is used to automatically deploy, expand and manage containerized applications. The main implementation language is the Go language. The components and architecture of Kubernetes are still relatively complex. Learn slowly~
We urgently need to organize a container~
Why kubernetes deprecated docker
::: tip Very unexpected It may seem a bit shocking to hear that Kubernetes is deprecating support for Docker as a container runtime starting with Kubernetes version 1.20.
Kubernetes is removing support for Docker as a container runtime. Kubernetes doesn’t actually handle the process of running containers on machines. Instead, it relies on another piece of software called the Container Runtime. .
:::
docker was released earlier than kubernetes
Docker itself is not compatible with the CRI interface. Kubernetes works with all container runtimes that implement a standard called the Container Runtime Interface (CRI). This is essentially a standard way of communicating between Kubernetes and container runtimes, and any runtime that supports this standard will automatically work with Kubernetes.
Docker does not implement the Container Runtime Interface (CRI). In the past, when there weren’t that many good options for container runtimes, Kubernetes implemented the Docker shim, which was an extra layer that served as an interface between Kubernetes and Docker. However, now that there are so many runtimes that implement CRI, it no longer makes sense for Kubernetes to maintain special support for Docker.
::: warning deprecated meaning Although docker has been removed, the previous dockershim is still retained. If you want, you can still use the docker containerization engine to provide containerization support.
In addition to docker, there are also containerd and CRI-O
I’ll let you in on a secret: Docker is not actually a container runtime! It’s actually a collection of tools that sit on top of a container runtime called containerd. .
That’s right! Docker does not run containers directly. It simply creates a more accessible and feature-rich interface on top of a separate underlying container runtime. When it is used as a container runtime for Kubernetes, Docker is just the middleman between Kubernetes and containers.
However, Kubernetes can directly use containerd as the container runtime, which means that Docker is no longer needed in this middleman role. Docker still has a lot to offer, even within the Kubernetes ecosystem. It just doesn’t need to be used specifically as a container runtime.
:::
Podman is born:
podman is also positioned to be compatible with docker, so it is as close to docker as possible in use. In terms of use, it can be divided into two aspects, one is the perspective of the system builder, and the other is the perspective of the system user.
kubernetes(k8s)
Kubernetes is Google’s open source container orchestration and scheduling engine based on Borg. It is one of the most important components of CNCF (Cloud Native Computing Foundation) , its goal is not just an orchestration system, but to provide a specification that allows you to describe the cluster architecture and define the final state of the service. Kubernetes can help you automatically achieve and maintain the system in this state. As the cornerstone of cloud native applications, Kubernetes is equivalent to a cloud operating system, and its importance is self-evident.
**In one sentence: k8s provides us with a framework for elastically running distributed systems. k8s meets my expansion requirements, failover, deployment modes, etc. For example: k8s can easily manage the Canary deployment of the system. **
::: What are tip sealos? sealos is a cloud operating system distribution with kubernetes as the core
Early stand-alone operating systems also had a layered architecture, and later evolved into kernel architectures such as Linux and Windows. The layered architecture of cloud operating systems has been broken down since the birth of containers, and in the future it will also move towards a highly cohesive “cloud kernel” architecture. migrate
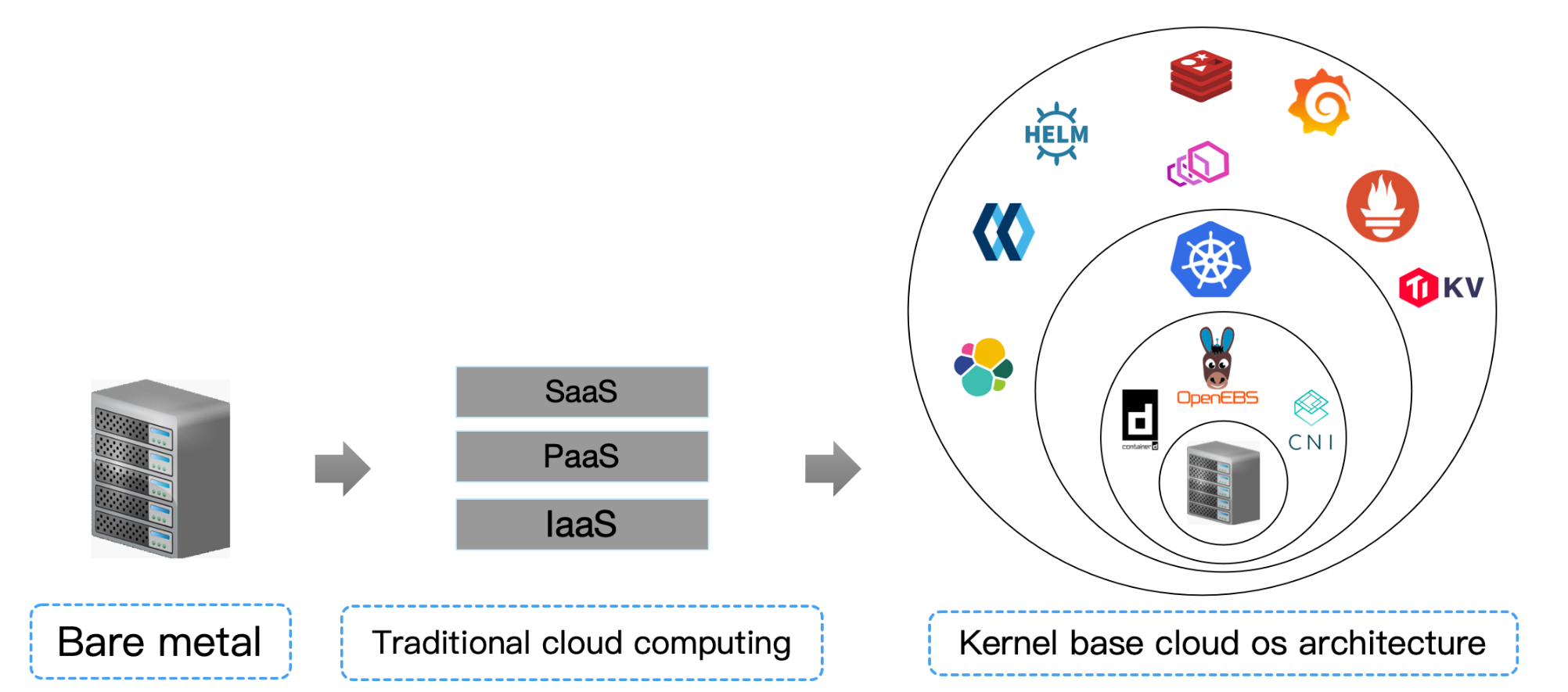
- From now on, imagine all the machines in your data center as an “abstract” supercomputer, sealos is the operating system used to manage this supercomputer, and kubernetes is
- .The kernel of this operating system!
- From now on, cloud computing is no longer divided into IaaS, PaaS, and SaaS. It is only composed of cloud operating system driver (CSI CNI CRI implementation), cloud operating system kernel (kubernetes) and distributed applications.
:::
Here, I will go through everything from docker to k8s
- Some common methods of
Docker, of course our focus will be on Kubernetes- Will use
kubeadmto build aKubernetescluster- Understand how
Kubernetescluster operates- Some commonly used methods of using controllers
- There are also some scheduling strategies for
Kubernetes- Operation and maintenance of
Kubernetes- Use of package management tool
Helm- Finally we will implement CI/CD based on Kubernetes
k8s architecture
Conditions that a container orchestration system needs to meet:
- Service registration, service discovery
- load balancing
- Configuration, storage management
- health check
- Automatic expansion and contraction
- zero downtime
Way of working
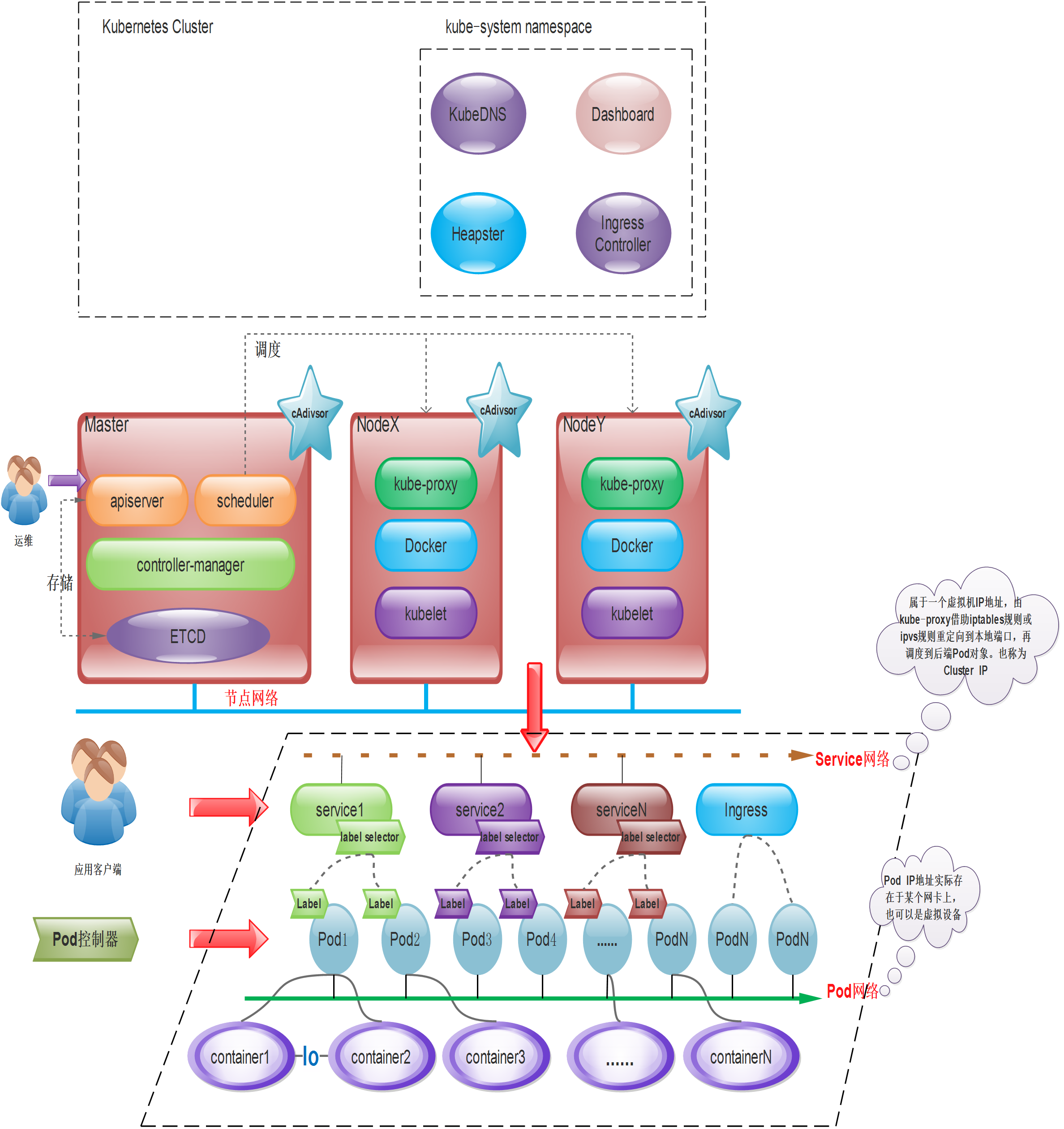
Kubernetes adopts a master-slave distributed architecture, including Master (master node), Worker (slave node or worker node), as well as the client command line tool kubectl and other add-ons.
Organization
I think the example of Silicon Valley can give us a good understanding:
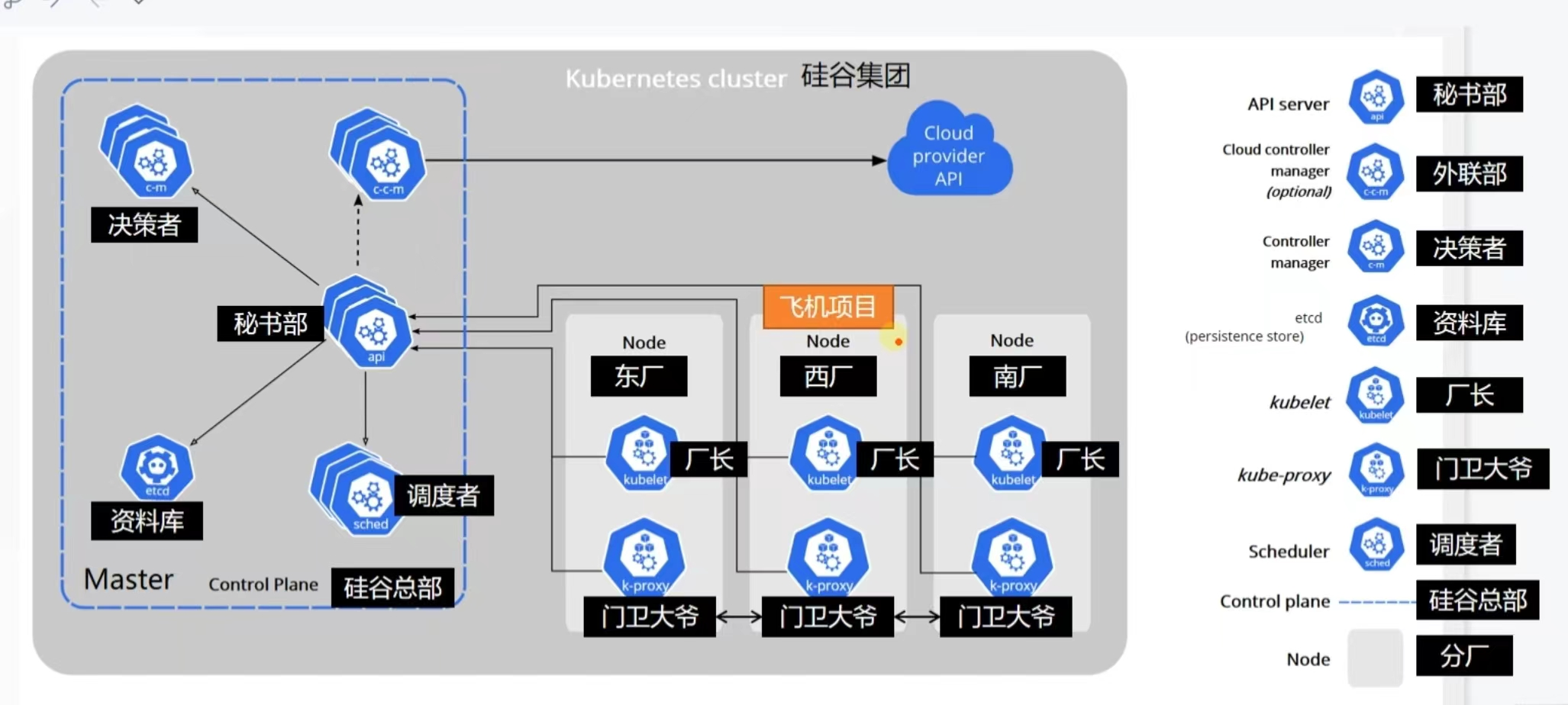
::: warning Kubernetes Control Plane
The Kubernetes control plane is responsible for maintaining the Desire State of any object in the cluster. It also manages worker nodes and Pods. It consists of five components including Kube-api-server, namely Kube-scheduler, Kube-controller-manager and cloud-controller-manager. The node running these components is called the “master node”. These components can run on a single node or multiple nodes, but it is recommended to run on multiple nodes in production to provide high availability and fault tolerance. Each control plane component has its own responsibilities, but together they make global decisions about the cluster and detect and respond to cluster events generated by users or any integrated third-party applications.
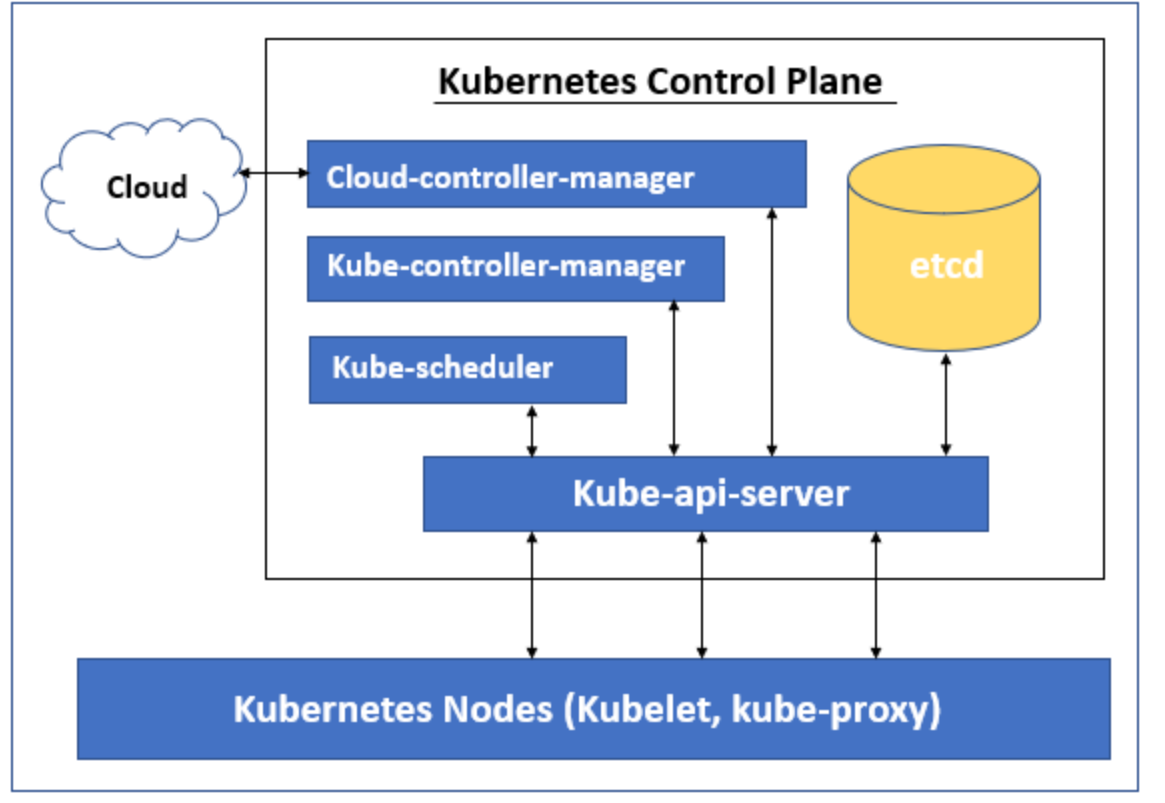
Let’s understand the different components of Kubernetes Control Plane. The Kubernetes Control Plane has the following five components:
- Kube-api-server
- Kube-scheduler
- Kube-controller-manager
- etcd
- cloud-controller-manager
Kube-API-server:
Kube-api-server is the main component of the control plane because all traffic goes through api-server, if other components of the control plane have to communicate with the ‘etcd’ data store, they are also connected to the api-server because there is only Kube-api -server can communicate with “etcd”. It provides services for REST operations and provides a front end for the Kubernetes Control Plane, which exposes the Kubernetes API through which other components can communicate with the cluster. There are multiple api-servers that can be deployed horizontally to balance traffic using a load balancer.
Kube-scheduler:
Kube-scheduler is responsible for scheduling newly created Pods to the best available node to run in the cluster. However, you can schedule a Pod or a set of Pods on a specific node, in a specific region, or based on node labels, etc., by specifying affinity, counterspecification, or constraints in a YAML file before or before the Pod is deployed. deploy. If there are no available nodes that meet the specified requirements, the Pod is not deployed and remains unscheduled until Kube-scheduler cannot find a viable node. Feasible nodes are nodes that meet all requirements for Pod scheduling.
Kube-scheduler uses a 2-step process to select nodes, filter, and score for pods in the cluster. During the filtering process, Kube-scheduler finds a viable node by running checks such as whether the node has enough available resources to mention for this pod. After filtering out all viable nodes, it assigns each viable node a score based on activity score rules and runs the Pod on the node with the highest score. If multiple nodes have the same score, it randomly selects one.
Kube-controller-manager:
Kube-controller-manager is responsible for running the controller process. It actually consists of four processes and runs as one to reduce complexity. It ensures that the current state matches the desired state, and if the current state does not match the desired state, appropriate changes are made to the cluster to reach the desired state.
It includes Node Controller, Replication Controller, Endpoint Controller, and Service Account and Token Controller.
- Node Controller: – It manages the nodes and keeps an eye on the available nodes in the cluster and responds if any node fails.
- Replication Controller: – It ensures that the correct number of Pods are running for each replication controller object in the cluster.
- Endpoints Controller: – It creates Endpoints objects, for example, in order to expose a pod to the outside, we need to join it to a service.
- Service Account and Token Controller: – Responsible for creating default accounts and API access tokens. For example, whenever we create a new namespace, we need a service account and access token to access it, so these controllers are responsible for creating the default account and API access token for the new namespace.
etcd
etcd is the default data store for Kubernetes and is used to store all cluster data. It is a consistent, distributed, highly available key-value store. etcd can only be accessed through Kube-api-server. If other control plane components must access etcd, they must go through kube-api-server. etcd is not part of Kubernetes. It is a completely different open source product supported by the Cloud Native Computing Foundation. We need to set up a proper backup plan for etcd so that if something goes wrong with the cluster, we can restore the backup and get back to business quickly.
cloud-controller-manager
cloud-controller-manager allows us to connect a local Kubernetes cluster to a cloud-hosted Kubernetes cluster. It is a separate component that only interacts with the cloud platform. Cloud Controller Manager’s controller depends on the cloud provider we are running our workload on. It is not available if we have a local Kubernetes cluster or if we have Kubernetes installed on our own PC for learning purposes. cloud-controller-manager also contains three controllers in a single process, which are node controller, route controller and service controller.
- Node Controller: – It constantly checks the status of the nodes hosted in the cloud provider. For example, if any node is unresponsive, it checks if the node has been deleted in the cloud.
- Route Controller: – It controls and sets up routing in the underlying cloud infrastructure.
- Service Controller: – Create, update and delete cloud provider load balancers.
:::
Cluster architecture and components
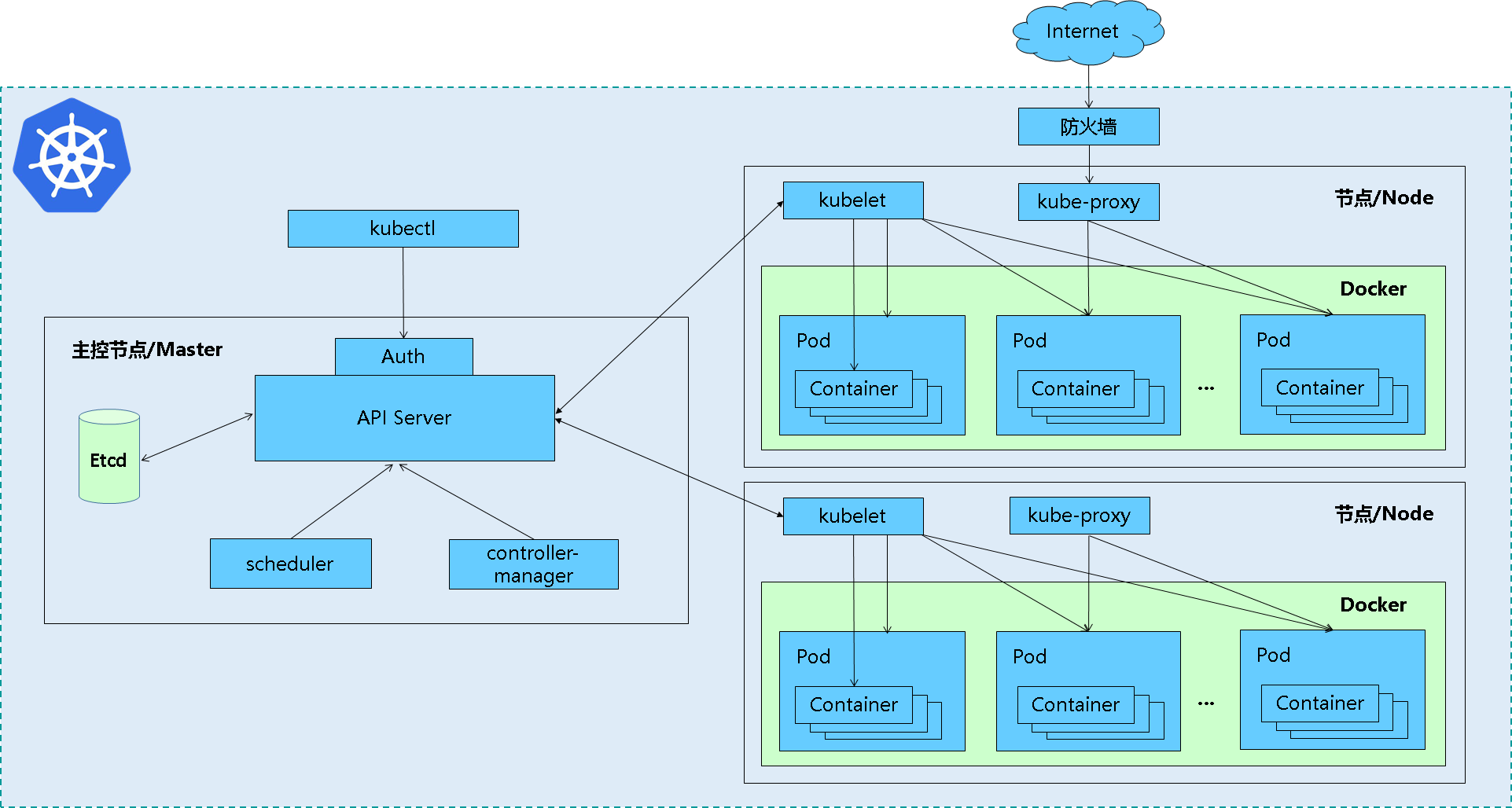
Master node
Master is the gateway and central hub of the cluster. Its main functions are to expose API interfaces, track the health status of other servers, schedule loads in an optimal way, and orchestrate communication between other components. A single Master node can complete all functions, but considering the pain point of single point of failure, multiple Master nodes are usually deployed in a production environment to form a Cluster.
| master | overview | | ————————— | ————————— ———————————- | | APIServer | Kubernetes API, the unified entrance of the cluster and the coordinator of each component, provides interface services with RESTful API. The addition, deletion, modification, checking and monitoring operations of all object resources are handed over to APIServer for processing and then submitted to Etcd storage. | | Scheduler | Select a Node node for the newly created Pod according to the scheduling algorithm. It can be deployed arbitrarily, on the same node, or on different nodes. | | Controller-Manager | Processes regular background tasks in the cluster. One resource corresponds to a controller, and ControllerManager is responsible for managing these controllers. |
Work Node
It is the working node of Kubernetes, responsible for receiving work instructions from the Master, creating and destroying Pod objects accordingly according to the instructions, and adjusting network rules for reasonable routing and traffic forwarding. In a production environment, there can be N nodes.
| Node | Overview | | ————————– | ————————– ————————————— | | kubelet | Kubelet is the Master’s Agent on the Node node. It manages the life cycle of the locally running container, such as creating containers, Pod mounting data volumes, downloading secrets, obtaining container and node status, etc. The kubelet converts each Pod into a set of containers. | | Pod (Docker or rocket) | Container engine, running containers. | | kube-proxy | Implement the Pod network proxy on the Node node to maintain network rules and four-layer load balancing. |
etcd data storage
Distributed key-value storage system. Used to save cluster status data, such as Pod, Service, network and other object information.
Core accessories
K8S clusters also rely on a set of add-on components, typically application-specific ones provided by third parties
| Core Plugins | Overview | | —————— | ———————————- ———————————- | | KubeDNS | Schedule and run Pods that provide DNS services in the K8S cluster. Other Pods in the same cluster can use this DNS service to resolve host names. K8S uses the CoreDNS project by default since version 1.11 to provide dynamic name resolution services for service registration and service discovery for the cluster. | | Dashboard | All functions of the K8S cluster must be based on the Web UI to manage the applications in the cluster and the cluster itself. | | Heapster | A performance monitoring and analysis system for containers and nodes. It collects and parses a variety of indicator data, such as resource utilization and life cycle time. In the latest version, its main functions are gradually replaced by Prometheus combined with other components. Starting from v1.8, resource usage monitoring can be obtained through the Metrics API. The specific component is Metrics Server, which is used to replace the previous heapster. This component began to be gradually abandoned in 1.11. | | Metric-Server | Metrics-Server is an aggregator of cluster core monitoring data. Starting from Kubernetes 1.8, it is deployed by default as a Deployment object in the cluster created by the kube-up.sh script. If it is deployed in other ways, it needs to be deployed separately. Install. | | Ingress Controller | Ingress is HTTP(S) load balancing implemented at the application layer. However, the Ingress resource itself cannot penetrate traffic. It is just a set of routing rules. These rules need to work through the Ingress Controller. Currently, the functional projects include: Nginx-ingress, Traefik, Envoy and HAproxy, etc. |
Network plug-in
| Online file checking | Overview |
| ————————————————– ———- | ————————————- |
| Container Network Interface (CNI) | Container Network Interface |
| flunnal | Implement network configuration, overlay network overlay network |
| calico | Network configuration, network policy; BGp protocol, tunnel protocol |
| canal (calico + flunnal) | For network strategy, used with flannel. |
|  | |
| |
Kubernetes basic concepts
| Basic concepts | | | ————————– | ————————– ————————————— | | Label resource label | Label (key/value), attached to a resource, used to associate objects, query and filter; | | Labe Selector Label Selector | A mechanism to filter qualified resource objects based on Label | | Pod Resource Object | A Pod Resource Object is a logical component that combines one or more application containers, storage resources, dedicated IP, and other options to support operation | | Pod Controller | Resource abstraction that manages the Pod life cycle, and it is a type of object, not a single resource object. Common ones include: ReplicaSet, Deployment, StatefulSet, DaemonSet, Job&Cronjob, etc. | | Service service resource | Service is a resource object built on a set of Pod objects. It is usually used to prevent Pods from losing contact, define access policies for a set of Pods, and proxy Pods | | Ingress | If you need to provide certain Pod objects for external user access, you need to open a port for these Pod objects to introduce external traffic. In addition to Service, Ingress is also a way to provide external access. | | Volume Storage Volume | Ensures persistent storage of data | | Name&&Namespace | Name is the identifier of the resource object in the K8S cluster, and usually acts on Namespace (namespace), so namespace is an additional qualification mechanism for names. In the same namespace, the names of resource objects of the same type must be unique. | | Annotation | Another type of key-value data attached to an object; it is convenient for tools or users to read and find. |
Label resource label
The resource tag embodies a key/values data; the tag is used to identify a specified object, such as a Pod object. Tags can be attached when the object is created, or added or modified after creation. It is worth noting that an object can have multiple tags, and a tab page can be attached to multiple objects.
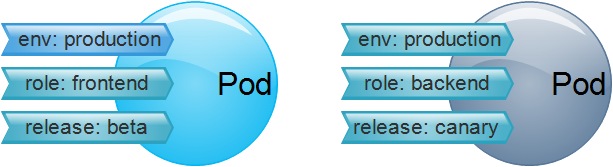
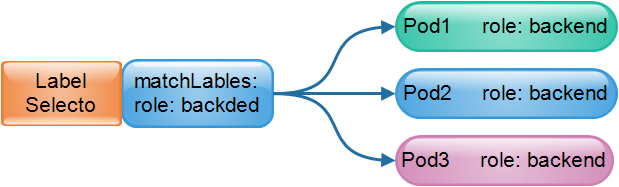
Labe Selector label selector
If there is a label, of course there is a label selector; for example, all Pod objects containing the label role: backend are selected and merged into one group. Usually during use, resource objects are classified by tags and then filtered by tag selectors. The most common application is to create a Service endpoint for a group of Pod resource objects with the same tags.
Pod resource object
Pod is the smallest scheduling unit of kubernetes; it is a collection of containers
Pod can encapsulate one or multiple containers! The network namespace and storage resources are shared in the same Pod, and containers can communicate directly through the local loopback interface: lo, but they are isolated from each other in namespaces such as Mount, User, and Pid.
A Pod is actually a single instance of an application running. It usually consists of one or more application containers that share resources and are closely related.
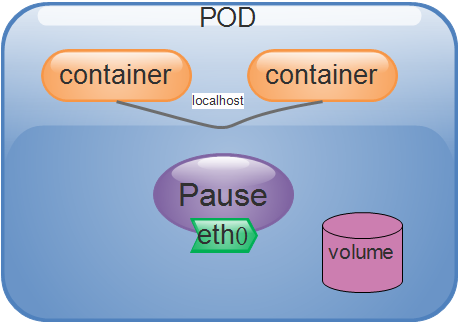
We analogize each Pod object to a physical host. Then multiple processes running in the same Pod object are similar to independent processes on the physical host. The difference is that each process in the Pod object runs on each other. In isolated containers, two key resources are shared between each container;
Network && storage volumes.
- Network: Each Pod object is assigned a Pod IP address, and all containers within the same Pod share the Network and UTS namespace of the Pod object, including host name, IP address, port, etc. Therefore, these containers can communicate through the local loopback interface lo, and communication with other components outside the Pod needs to be completed using the Cluster IP+ port of the Service resource object.
- Storage volumes: Users can configure a set of storage volume resources for the Pod object. These resources can be shared with all containers in the same Pod, thereby completing data sharing among containers.Enjoy. Storage volumes also ensure persistent storage of data even after the container is terminated, restarted, or deleted.
A Pod represents an instance of an application. Now we need to extend this application; this means creating multiple Pod instances, each instance representing a running copy of the application.
The tools for managing these replicated Pod objects are implemented by a group of objects called Controller; such as Deployment controller objects.
When creating a Pod, we can also use the Pod Preset object to inject specific information into the Pod, such as Configmap, Secret, storage volume, volume mounting, environment variables, etc. With the Pod Preset object, Pod template creation does not require providing all the information for each template display.
Based on the predetermined desired state and the resource availability of each Node node; the Master will schedule the Pod object to run on the selected worker node. The worker node downloads the image from the pointed image warehouse and starts it in the local container runtime environment. container. Master will save the status of the entire cluster in etcd and share it with various components and clients of the cluster through API Server.
Pod Controller (Controller)
When introducing Pod, we mentioned that Pod is the smallest scheduling unit of K8S; however, Kubernetes does not directly deploy and manage Pod objects, but relies on another abstract resource - Controller for management.
Common Pod controllers:
| Pod Controller | | | ————————– | ————————– ———————————————– | | Replication Controller | Use the replica controller. Only this Pod controller is supported in early risers; it can complete operations such as Pod increase and decrease, total number control, rolling update, rollback, etc., and has been discontinued | | ReplicaSet Controller | Use the replica set controller after the version is updated, and declare the usage method; it is an upgraded version of Replication Controller | | Deployment | Used for stateless application deployment, such as nginx, etc.; we will mention HPA Controller (Horizontal Pod Autosaler) later: used for horizontal Pod automatic scaling controller to control rs&deployment | | StatefulSet | Used for stateful application deployment, such as mysql, zookeeper, etc. | | DaemonSet | Ensure that all Nodes run the same Pod, such as network file checking flannel, zabbix_agent, etc. | | Job | One-time task | | Cronjob | Scheduled tasks |
Controllers are higher-level objects used to deploy and manage Pods.
Taking Deployment as an example, it is responsible for ensuring that the number of copies of the defined Pod object meets the expected settings, so that users only need to declare the desired state of the application, and the controller will automatically manage it.
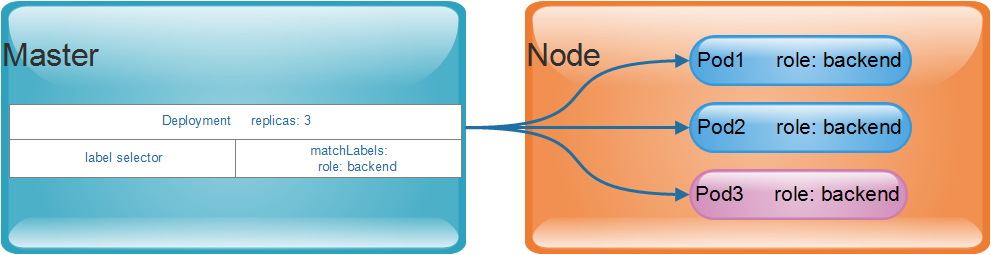
Pod objects created by users manually or directly through the Controller will be scheduled by the Scheduler to run on a working node in the cluster. They will be terminated normally after the container application process is finished running, and then deleted.
When a node’s resources are exhausted or malfunctions, it will also cause the recycling of Pod objects.
In the K8S cluster design, Pod is an object with a life cycle. Then a controller is used to manage one-time Pod objects.
For example, it is necessary to ensure that the number of Pod copies of the deployed application reaches the number expected by the user, and to reconstruct the Pod object based on the Pod template, so as to realize the expansion, contraction, rolling update and self-healing capabilities of the Pod object.
For example, if a node fails, the relevant controller will reschedule the Pod objects running on the node to other nodes for reconstruction.
The controller itself is also a resource type, and they are collectively called Pod controllers. Deployment, as shown below, is a representative implementation of this type of controller and is the Pod controller currently used to manage stateless applications.
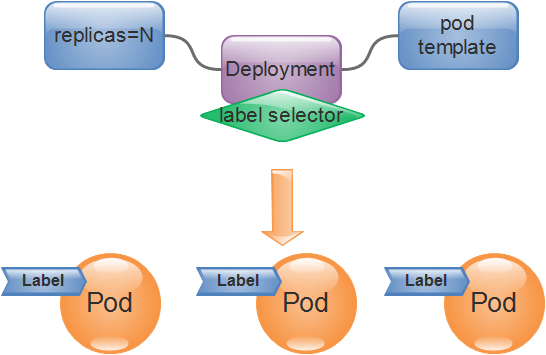
The definition of a Pod Controller usually consists of the desired number of replicas, a Pod template, and a label selector. The Pod Controller will match and filter the labels of the Pod objects based on the Labe Selector. All Pods that meet the selection conditions will be managed by the current Controller and included in the total number of replicas to ensure that the number reaches the expected number of status replicas.
In actual application scenarios, when the received request traffic load is lower than or close to the carrying capacity of the current existing Pod replicas, we need to manually modify the expected number of replicas in the Pod controller to achieve expansion and contraction of the application scale. . When resource monitoring components such as HeapSet or Prometheus are deployed in the cluster, users can also use HPA (HorizontalPod Autoscaler) to calculate the appropriate number of Pod copies and automatically modify the expected number of copies in the Pod controller to achieve Dynamic scaling of application scale improves cluster resource utilization.
Each node in the K8S cluster runs cAdvisor, which is used to collect live data on the utilization of CPU, memory and disk resources of containers and nodes. These statistical data can be accessed through the API server after being aggregated by Metrics. The HorizontalPodAutoscaler monitors the health of the container and makes scaling decisions based on these statistics.
Service service resources
| Main role or function | | | ———————————- | —————— ———————————————— | | Prevent Pod from losing contact | Service is a resource object built on a group of Pod objects. As mentioned earlier, it selects a group of Pod objects through the Labe Selector and defines a unified fixed access entrance for this group of Pod objects ( Usually an IP address), if K8S has a DNS attachment (such as coredns), it will automatically configure a DNS name for the service when it is created for the client to discover the service. | | Define a set of Pod access policies, proxy Pod | Usually we directly request the Service IP, and the request will be load balanced to the back-end endpoint, that is, each Pod object, that is, the load balancer; therefore, the Service is essentially a 4-layer Proxy service, in addition, Service can also introduce traffic from outside the cluster to the cluster, which requires nodes to map the Service port. |
The Pod object has a Pod IP address, but this address changes after the object is restarted or rebuilt. The randomness of the Pod IP address creates a lot of trouble for application system dependency maintenance.
For example: the front-end Pod application
Nginxcannot load the back-end Pod applicationTomcatbased on a fixed IP address.
Service resources are to add an intermediate layer with a fixed IP address to the accessed Pod object. After the client initiates an access request to this address, the relevant Service resources will schedule it and proxy it to the back-end Pod object.
Service is not a specific component, but a logical collection of multiple Pod objects defined through rules, and comes with a strategy for accessing this set of Pod objects. Service objects select and associate Pod objects in the same way as Pod controllers, which are defined through label selectors.
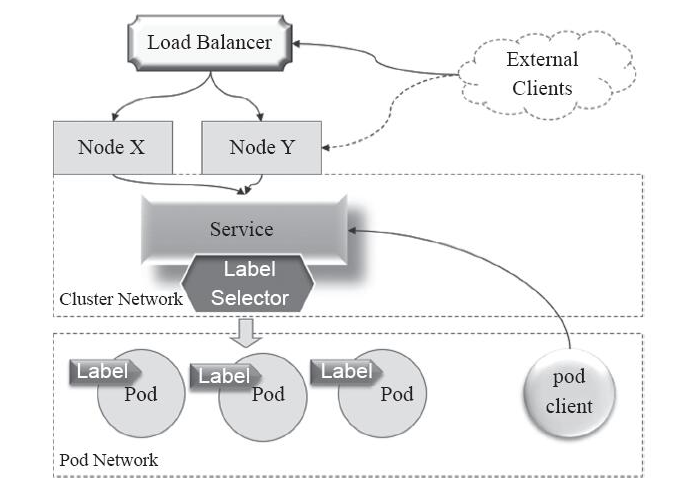
Service IP is a virtual IP, also known as Cluster IP, dedicated to intra-cluster communication.
Usually a dedicated address segment is used, such as the 10.96.0.0/12 network, and the IP address of each Service object is dynamically allocated by the system within this range.
Pod objects in the cluster can directly request this type of Cluster IP. For example, the access request from the Pod client in the figure above can be accessed through the Cluster IP of the Service as the target address, but it is a private network in the cluster network. Address, can only be accessed within the cluster.
Usually what we need is external access; the common method to introduce it into the cluster is through the node network. The implementation method is as follows:
- Access request through the IP address + port (Node Port) of the working node.
- Proxy the request to the service port of the Cluster IP of the corresponding Service object. In layman’s terms: the port on the working node maps the Service port.
- The Service object forwards the request to the Pod IP of the backend Pod object and the listening port of the application.
Therefore, similar to the cluster external client from External Client in the above figure, it cannot directly request the Cluster IP of the Service. Instead, it needs to pass the IP address of a certain working node Node. In this case, the request needs to be forwarded twice to reach the target Pod. object. The disadvantage of this type of access is that there is a certain delay in communication efficiency.
Ingress
K8S isolates the Pod object from the external network environment. Communication between objects such as Pod and Service needs to be carried out through internal dedicated addresses.
For example, if you need to provide certain Pod objects for external user access, you need to open a port for these Pod objects to introduce external traffic. In addition to Service, Ingress is also a way to provide external access.
Volume storage volume
A storage volume (Volume) is a storage space independent of the container file system. It is often used to expand the storage space of the container and provide it with persistent storage capabilities.
Storage volumes are classified in K8S as:
- Temporary volume
- Local volume
- Network volume
Both temporary volumes and local volumes are located locally on the Node. Once the Pod is scheduled to other Node nodes, this type of storage volume will not be accessible because temporary volumes and local volumes are usually used for data caching, and persistent data is usually placed in persistent volumes. (persistent volume).
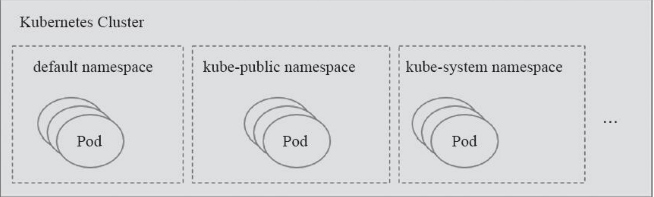
Name and Namespace
Namespaces are often used to isolate resources for a tenant or project to form logical groupings. For this concept, you can refer to the concept in the Docker documentation https://www.jb51.net/article/136411.htm
As shown in the figure: The created resource objects such as Pod and Service belong to the namespace level. If not specified, they all belong to the default namespace default
Annotation
Annotation is another type of key-value data attached to objects. It is often used to attach various non-identifying metadata (metadata) to objects, but it cannot be used to identify and select objects. Its function is to facilitate tools or users to read and search.