正片開始~
Kubernetes 是 Google 團隊發起的一個開源項目,它的目標是管理跨多個主機的容器,用於自動部署、擴展和管理容器化的應用程序,主要實現語言為 Go 語言。 Kubernetes 的元件和架構還是相對較複雜的。 要慢慢學習~
我們急需編排一個容器~
為什麼 kubernetes 棄用了 docker
::: tip 很意外 聽到 Kubernetes 從 Kubernetes 版本 1.20 開始棄用對 Docker 作為容器運行時的支持,這似乎有點令人震驚。
Kubernetes 正在刪除對 Docker 作為容器執行時間的支援。 Kubernetes 實際上並不處理在機器上運行容器的過程。 相反,它依賴於另一個稱為容器運行時的軟體。 .
:::
docker 比 kubernetes 發行的早
docker本身不相容於 CRI 介面。 Kubernetes 適用於所有實作稱為容器執行時間介面 (CRI) 標準的容器執行時間。 這本質上是 Kubernetes 和容器運行時之間通訊的標準方式,任何支援此標準的運行時都會自動與 Kubernetes 配合使用。
Docker 不實作容器執行時間介面 (CRI)。 過去,容器運行時沒有那麼多好的選擇,Kubernetes 實作了 Docker shim,這是一個額外的層,用作 Kubernetes 和 Docker 之間的介面。 然而,現在有許多運行時可以實現 CRI,Kubernetes 維護對 Docker 的特殊支援不再有意義。
::: warning 棄用的意義 雖然移除了 docker ,但還是保留了以前的 dockershim,如果你願意,你依舊可以使用 docker 容器化引擎提供容器化支援。
除了docker,還有 containerd、CRI-O
我會告訴你一個秘密:Docker實際上不是一個容器運行時! 它實際上是一個工具集合,位於稱為containerd的容器運行時之上。 .
沒錯! Docker 不會直接運作容器。 它只是在單獨的底層容器運行時之上創建一個更易於訪問且功能更豐富的介面。 當它被用作 Kubernetes 的容器運行時,Docker 只是 Kubernetes 和容器之間的中間人。
但是,Kubernetes可以直接使用containerd作為容器運行時,這意味著在這個中間人角色中不再需要Docker。 Docker仍然有很多東西可以提供,即使在Kubernetes生態系統中也是如此。 只是不需要專門用作容器運作時。
:::
Podman 橫空出世:
podman 的定位也是與 docker 相容,因此在使用上也盡量接近 docker。 在使用方面,可以分為兩個方面,一是系統建構者的角度,二是系統使用者的角度。
kubernetes(k8s)
Kubernetes是Google基於Borg開源的容器編排調度引擎,作為CNCF(Cloud Native Computing Foundation)最重要的元件之一 ,它的目標不只是一個編排系統,而是提供一個規範,可以讓你來描述叢集的架構,定義服務的最終狀態,Kubernetes 可以幫你將系統自動地達到和維持在這個狀態。 Kubernetes 作為雲端原生應用的基石,相當於一個雲端作業系統,其重要性不言而喻。
**一句話介紹:k8s就是為我們提供了可彈性運行分散式系統框架,k8s滿足我的擴充要求、故障轉移、部署模式等等,例如:k8s可以輕鬆管理系統的Canary部署。 **
::: tip sealos 是什麼 sealos 是以 kubernetes 為核心的雲端作業系統發行版
早期單機作業系統也是分層架構,後來才演變成linux windows 這種核心架構,雲端作業系統從容器誕生之日起分層架構被擊穿,未來也會朝著高內聚的"雲端核心"架構 遷移
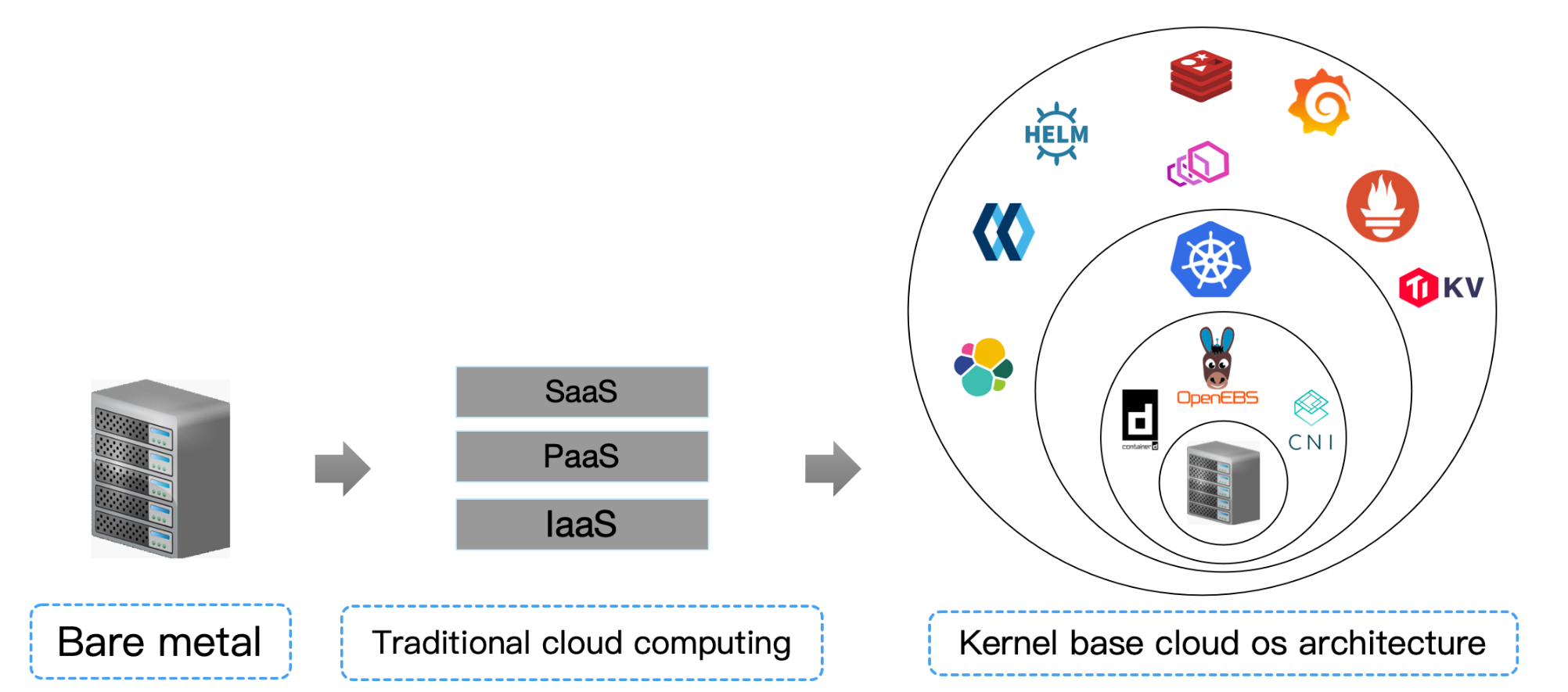
- 從現在開始,把你資料中心所有機器想像成一台"抽象"的超級計算機,sealos 就是用來管理這台超級電腦的作業系統,kubernetes 就是
- .這個作業系統的核心!
- 雲端運算從此刻起再無 IaaS PaaS SaaS 之分,只有雲端作業系統驅動(CSI CNI CRI 實作) 雲端作業系統核心(kubernetes) 和 分散式應用組成
:::
在這裡,我將會從docker到k8s全部遍歷一遍
Docker的一些常用方法,當然我們的重點會在 Kubernetes 上面- 會用
kubeadm來搭建一套Kubernetes的集群- 理解
Kubernetes叢集的運作原理- 常用的一些控制器使用方法
- 還有
Kubernetes的一些排程策略Kubernetes的維- 套件管理工具
Helm的使用- 最後我們會實作基於 Kubernetes 的 CI/CD
k8s架構
容器編排系統需要滿足的條件:
- 服務註冊,服務發現
- 負載平衡
- 設定、儲存管理
- 健康檢查
- 自動擴縮容
- 零宕機
工作方式
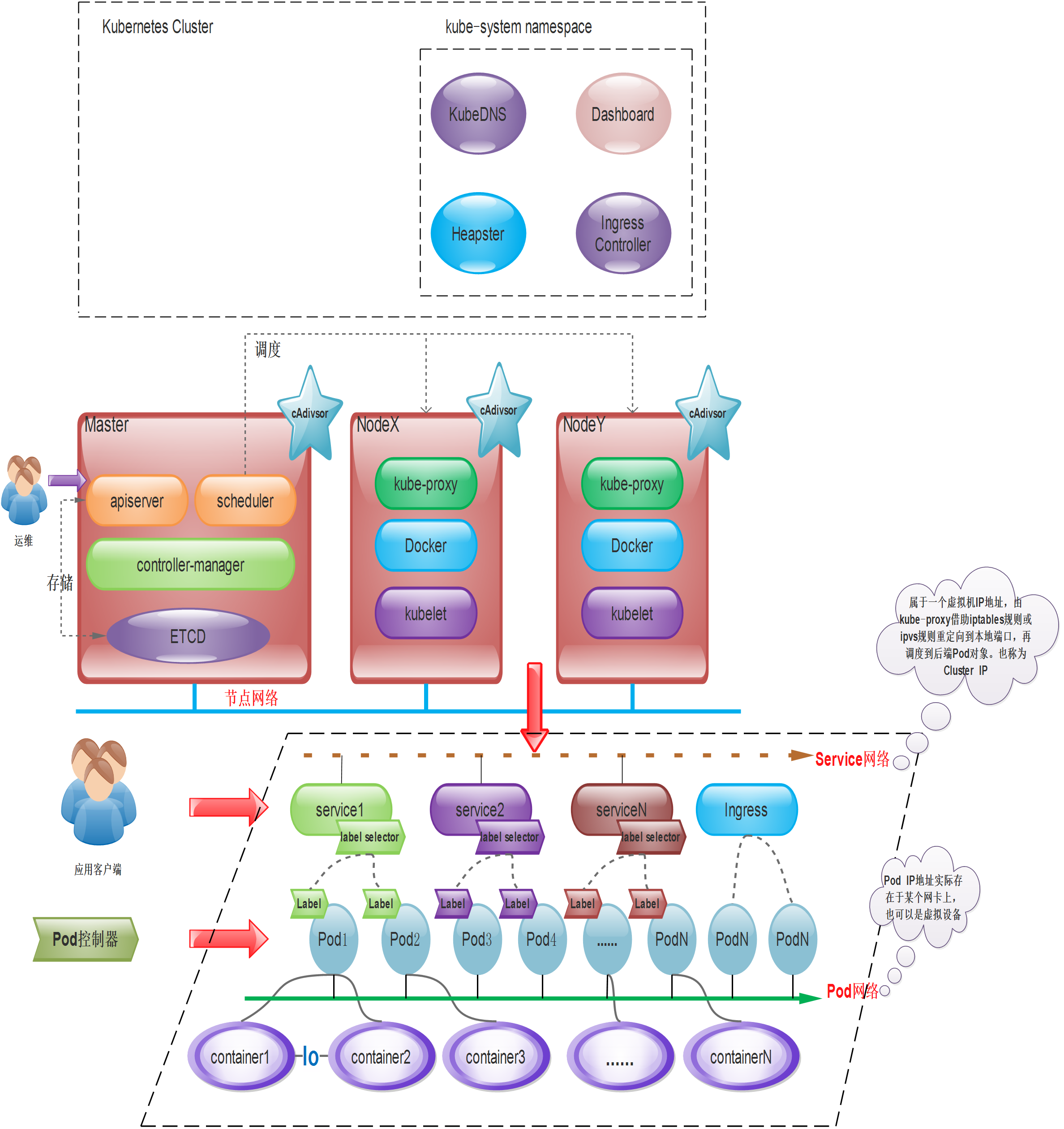
Kubernetes採用主從分散式架構,包括Master(主節點)、Worker(從節點或工作節點),以及客戶端命令列工具kubectl和其它附加項。
組織架構
我覺得尚矽谷的例子可以讓我們很好的理解:
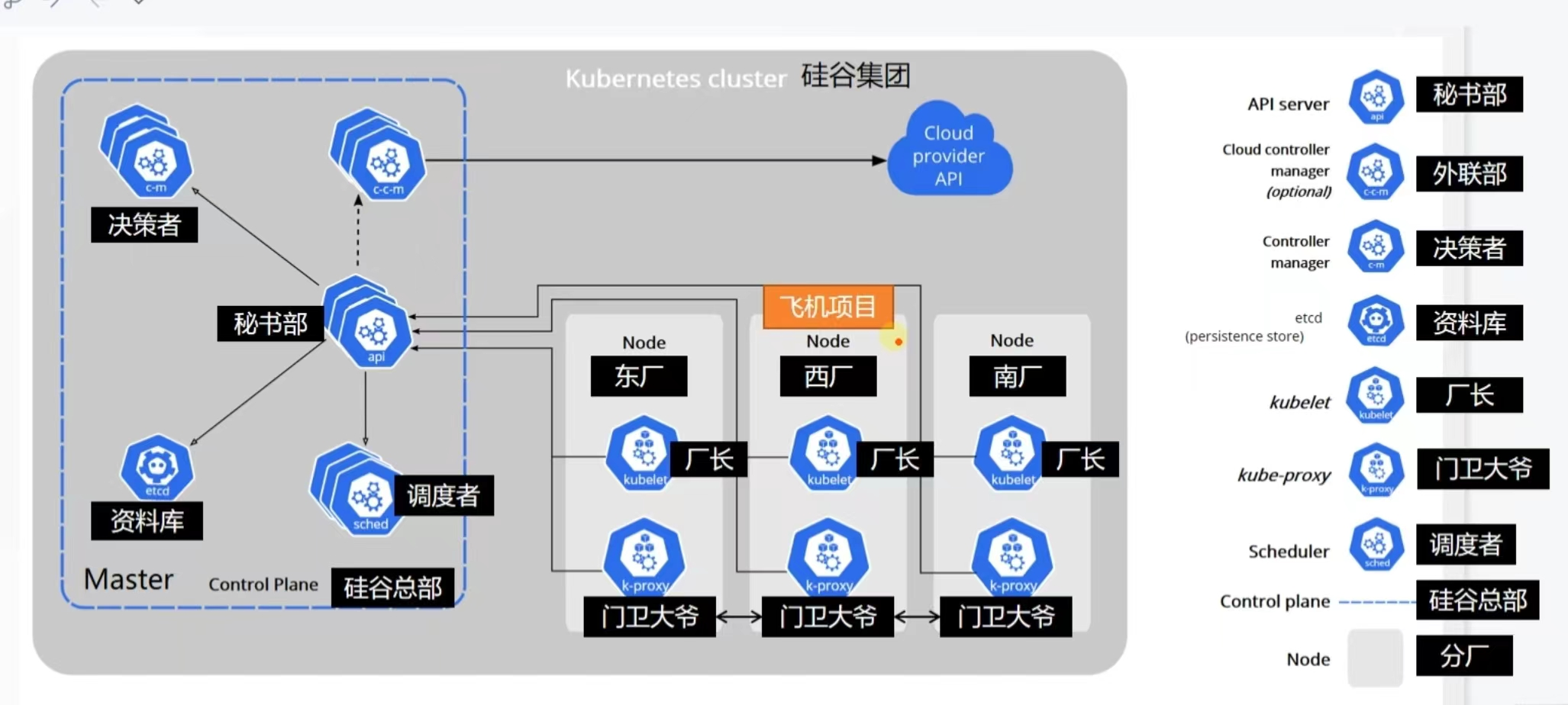
::: warning Kubernetes Control Plane
Kubernetes control Plane 負責維護叢集中任何物件的 Desire State。 它還管理工作節點和 Pod。 它由 Kube-api-server 等五個元件組成,即 Kube-scheduler、Kube-controller-manager 和 cloud-controller-manager。 運行這些組件的節點稱為「主節點」。 這些元件可以在單一節點或多個節點上運行,但建議在生產中在多個節點上運行以提供高可用性和容錯性。 每個控制平面的元件都有自己的職責,但是它們一起對叢集做出全域決策,偵測和回應由使用者或任何整合的第三方應用程式產生的叢集事件。
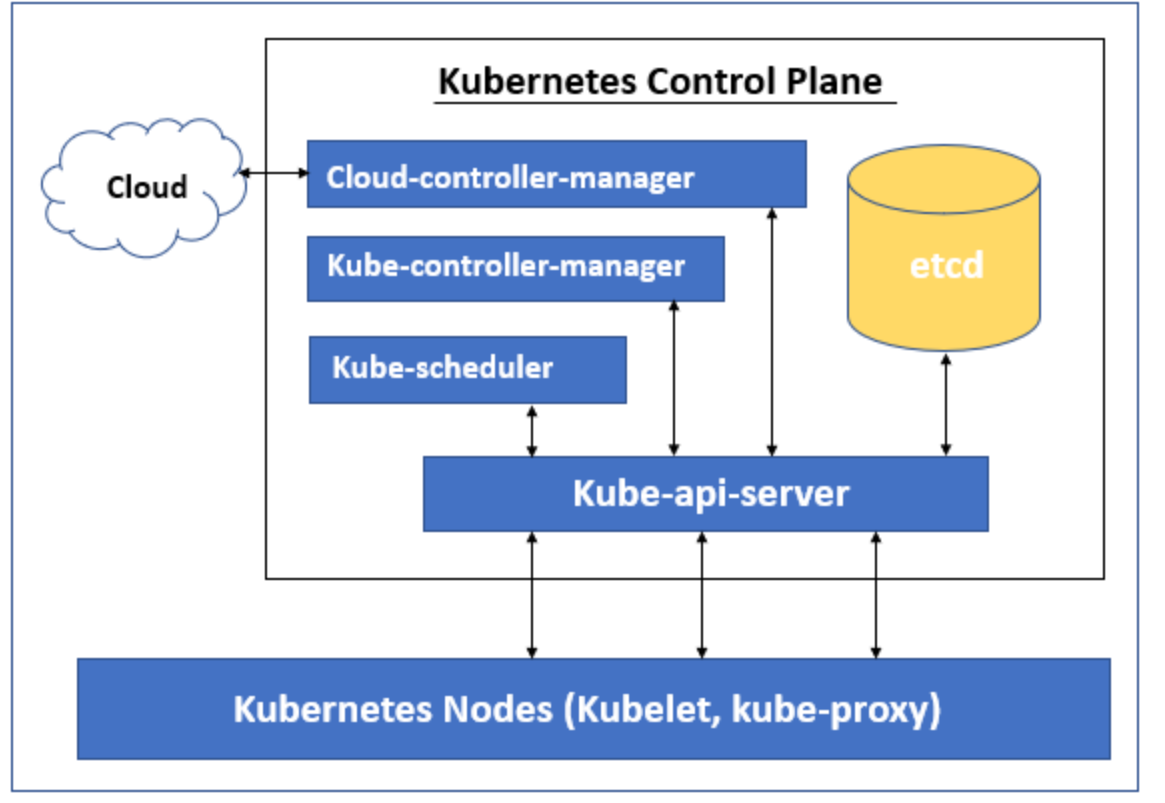
讓我們了解 Kubernetes Control Plane的不同組件。 Kubernetes Control Plane有以下五個元件:
- Kube-api-server
- Kube-scheduler
- Kube-controller-manager
- etcd
- cloud-controller-manager
Kube-API-server:
Kube-api-server 是控制平面的主要元件,因為所有流量都透過api-server,如果控制平面的其他元件必須與’etcd' 資料儲存通信,則它們也連接到api-server,因為只有Kube-api -server可以與「etcd」通訊。 它為 REST 操作提供服務,並為 Kubernetes Control Plane提供前端,該控制平面公開 Kubernetes API,其他元件可以透過該 API 與叢集通訊。 有多個 api-server 可以水平部署以使用負載平衡器來平衡流量。
Kube-scheduler:
Kube-scheduler 負責將新建立的 Pod 調度到最佳可用節點以在叢集中運行。 但是,可以在部署 Pod 或部署 Pod 之前,透過在 YAML 檔案中指定關聯性、反規範或約束,在特定節點、特定區域或根據節點標籤等安排 Pod 或一組 Pod。 部署。 如果沒有滿足指定要求的可用節點,則不會部署 Pod 並保持未調度狀態,直到 Kube-scheduler 找不到可行的節點。 可行節點是滿足 Pod 調度所有要求的節點。
Kube-scheduler 使用 2 步驟流程為叢集中的 pod 選擇節點、篩選和評分。 在過濾過程中,Kube-scheduler 透過執行檢查來找到一個可行的節點,例如節點是否有足夠的可用資源來為這個 pod 提及。 過濾掉所有可行節點後,它會根據活動得分規則為每個可行節點分配一個分數,並在得分最高的節點上執行 Pod。 如果多個節點具有相同的分數,則它隨機選擇一個。
Kube-controller-manager:
Kube-controller-manager 負責執行控制器流程。 它實際上由四個進程組成,並作為一個進程運行以降低複雜性。 它確保當前狀態與期望狀態匹配,如果當前狀態與期望狀態不匹配,則對叢集進行適當的變更以達到期望狀態。
它包括節點控制器、複製控制器、端點控制器以及服務帳戶和令牌控制器。
- 節點控制器: – 它管理節點並密切關注叢集中的可用節點,並在任何節點出現故障時做出回應。
- 複製控制器: – 它確保為叢集中的每個複製控制器物件執行正確數量的 Pod。
- Endpoints 控制器: – 它建立 Endpoints 對象,例如,為了向外部公開 pod,我們需要將其加入服務。
- 服務帳戶和令牌控制器: – 負責建立預設帳戶和 API 存取權令牌。 例如,每當我們建立一個新命名空間時,我們需要一個服務帳戶和存取權杖來存取它,因此這些控制器負責為新命名空間建立預設帳戶和 API 存取權杖。
etcd
etcd 是 Kubernetes 的預設資料存儲,用於存儲所有叢集資料。 它是一個一致的、分散式的、高度可用的鍵值儲存。 etcd 只能透過 Kube-api-server 存取。 如果其他控制平面的元件必須存取 etcd,則必須透過 kube-api-server。 etcd 不是 Kubernetes 的一部分。 它是由雲端原生運算基金會支援的完全不同的開源產品。 我們需要為 etcd 設定一個適當的備份計劃,這樣如果叢集出現問題,我們可以還原備份並快速還原業務。
cloud-controller-manager
cloud-controller-manager 讓我們可以將本地 Kubernetes 叢集連接到雲端託管的 Kubernetes 叢集。 它是一個單獨的元件,僅與雲端平台互動。 雲端控制器管理器的控制器取決於我們運行工作負載的雲端提供者。 如果我們有本地 Kubernetes 集群,或者我們為了學習目的在自己的 PC 上安裝了 Kubernetes,則它不可用。 cloud-controller-manager 也在單一行程中包含三個控制器,它們是節點控制器、路由控制器和服務控制器。
- 節點控制器: – 它不斷檢查託管在雲端提供者中的節點的狀態。 例如,如果任何節點沒有回應,則它會檢查該節點是否已在雲端中刪除。
- 路由控制器: – 它在底層雲端基礎架構中控制和設定路由。
- 服務控制器: – 建立、更新和刪除雲端提供者負載平衡器。
:::
叢集架構與元件
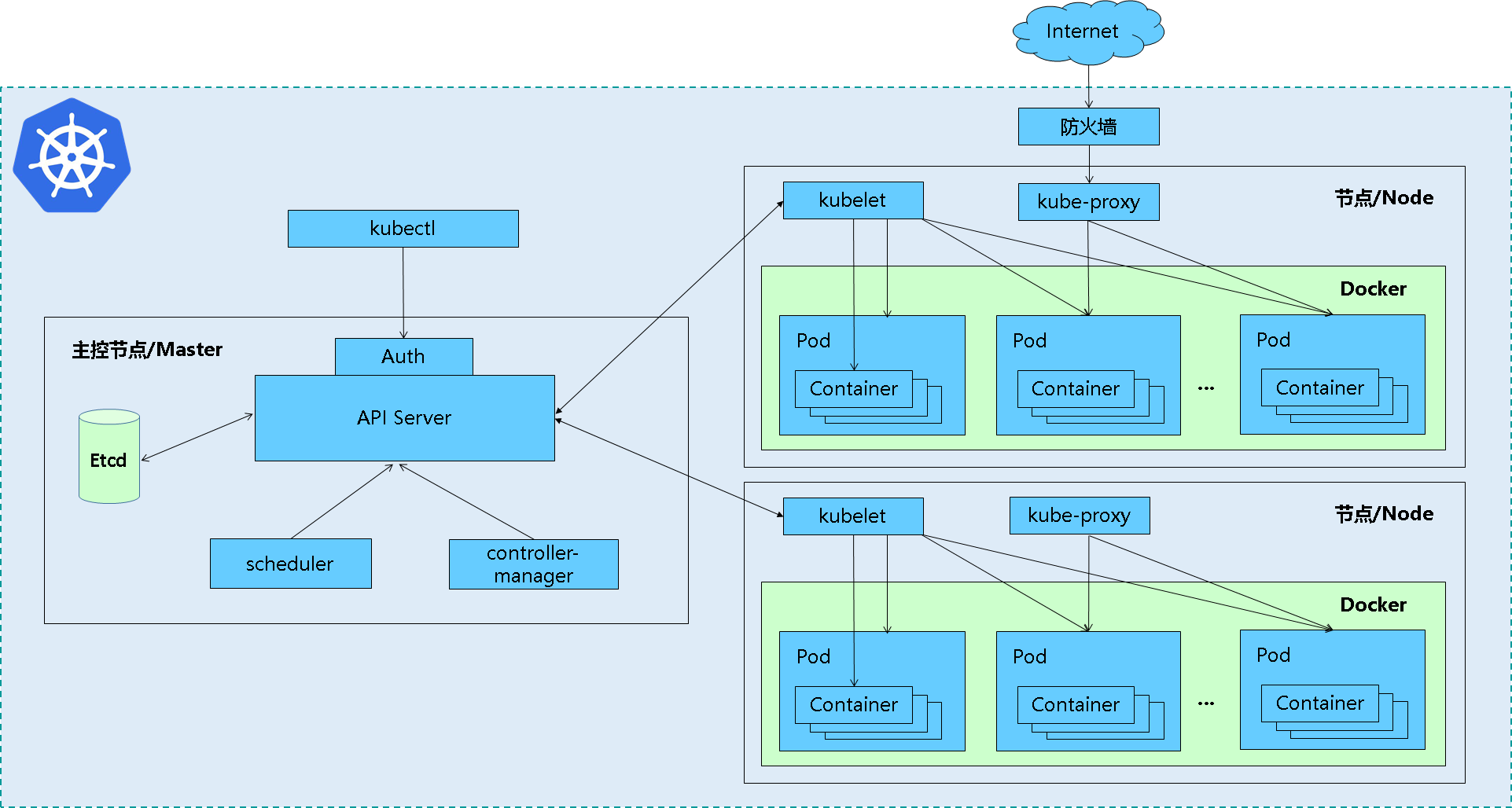
Master節點
Master是叢集的網關和中樞樞紐,主要作用:暴露API接口,追蹤其他伺服器的健康狀態、以最優方式調度負載,以及編排其他元件之間的通訊。 單一的Master節點可以完成所有的功能,但考慮單點故障的痛點,在生產環境中通常會部署多個Master節點,組成Cluster。
| master | 概述 | | ———————- | ————————– ———————————- | | APIServer | Kubernetes API,叢集的統一入口,各元件協調者,以RESTful API提供介面服務,所有物件資源的增刪改查和監聽作業都交給APIServer處理後再提交給Etcd儲存。 | | Scheduler | 根據調度演算法為新建立的Pod選擇一個Node節點,可以任意部署,可以部署在同一個節點上,也可以部署在不同的節點上。 | | Controller-Manager | 處理叢集中常規後台任務,一個資源對應一個控制器,而ControllerManager就是負責管理這些控制器的。 |
Work Node節點
是Kubernetes的工作節點,負責接收來自Master的工作指令,並依照指令相應地建立和銷毀Pod對象,以及調整網路規則進行合理路由和流量轉送。 生產環境中,Node節點可以有N個。
| Node | 概述 | | ————————— | ——————— ————————————— | | kubelet | kubelet是Master在Node節點上的Agent,管理本機運行容器的生命週期,例如建立容器、Pod掛載資料磁碟區、下載secret、取得容器和節點狀態等工作。 kubelet將每個Pod轉換成一組容器。 | | Pod(Docker or rocket) | 容器引擎,運行容器。 | | kube-proxy | 在Node節點上實作Pod網路代理,維護網路規則與四層負載平衡工作。 |
etcd資料存儲
分散式鍵值儲存系統。 用於保存叢集狀態數據,例如Pod、Service、網路等物件資訊。
核心附件
K8S叢集還依賴一組附件元件,通常是由第三方提供的特定應用程式
| 核心插件 | 概述 | | —————— | —————————— —————————— | | KubeDNS | 在K8S叢集中調度並運行提供DNS服務的Pod,同一叢集內的其他Pod可以使用此DNS服務來解決主機名稱。 K8S自1.11版本開始預設使用CoreDNS專案來為叢集提供服務註冊和服務發現的動態名稱解析服務。 | | Dashboard | K8S叢集的全部功能都要基於Web的UI,來管理叢集中的應用和叢集本身。 | | Heapster | 容器和節點的效能監控與分析系統,它收集並解析多種指標數據,如資源利用率、生命週期時間,在最新的版本當中,其主要功能逐漸由Prometheus結合其他的組件進行代替。 從 v1.8 開始,資源使用情況的監控可以透過 Metrics API的形式獲取,具體的組件為Metrics Server,用來替換先前的heapster,該組件1.11開始逐漸被廢棄。 | | Metric-Server | Metrics-Server是叢集核心監控資料的聚合器,從Kubernetes1.8 開始,它作為一個Deployment物件預設部署在由kube-up.sh腳本建立的叢集中,如果是其他部署方式需要單獨 安裝。 | | Ingress Controller | Ingress是在應用層實現的HTTP(S)的負載平衡。 不過,Ingress資源本身並不能進行流量的穿透,它只是一組路由規則的集合,這些規則需要透過Ingress控制器(Ingress Controller)發揮作用。 目前該功能項目大概有:Nginx-ingress、Traefik、Envoy和HAproxy等。 |
網路插件
| 網路查件 | 概述 |
|————————————————- ———– | ————————————- |
| Container Network Interface (CNI) | 容器網路介面 |
| flunnal | 實現網路配置,overlay network疊加網路 |
| calico | 網路配置,網路策略;BGp協議,隧道協定 |
| canal(calico + flunnal) | 供網路策略,配合flannel使用。 |
|  | |
| |
Kubernetes基本概念
| 基本概念 | | | ————————— | ——————— ————————————— | | Label資源標籤 | 標籤(key/value),附加到某個資源上,用於關聯物件、查詢和篩選; | | Labe Selector標籤選擇器 | 根據Label進行過濾符合條件的資源物件的一種機制 | | Pod資源物件 | Pod資源物件是一種集合了一個或多個應用容器、儲存資源、專用ip、以及支撐運作的其他選項的邏輯元件 | | Pod控制器(Controller) | 管理Pod生命週期的資源抽象,並且它是一類對象,並非單一的資源對象,其中常見的包括:ReplicaSet、Deployment、StatefulSet、DaemonSet、Job&Cronjob等等 | | Service服務資源 | Service是建立在一組Pod對象之上的資源對象,通常用作防止Pod失聯、定義一組Pod的存取策略,代理Pod | | Ingress | 如果需要將某些Pod物件提供給外部用戶訪問,則需要給這些Pod物件打開一個端口進行引入外部流量,除了Service以外,Ingress也是實現提供外部訪問的一種方式。 | | Volume儲存磁碟區 | 保證資料的持久化儲存 | | Name&&Namespace | Name是K8S叢集中資源物件的標識符,通常作用於Namespace(名稱空間),因此名稱空間是名稱的額外的限定機制。 在同一個名稱空間中,同一類型資源物件的名稱必須具有唯一性。 | | Annotation註解 | 另一種附加在物件上的一種鍵值類型的資料;方便工具或使用者閱讀及尋找。 |
Label 資源標籤
資源標籤具體化的就是一個鍵值型(key/values)資料;使用標籤是為了對指定物件進行辨識,例如Pod物件。 標籤可以在物件建立時進行附加,也可以建立後進行新增或修改。 值得注意的是一個物件可以有多個標籤,一個標籤頁可以附加到多個物件。
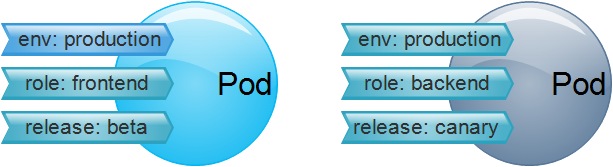
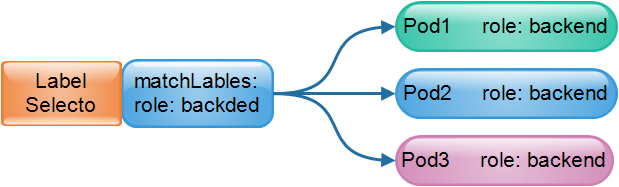
Labe Selector標籤選擇器
有標籤,當然就有標籤選擇器;例如將含有標籤role: backend的所有Pod物件挑選出來歸併為一組。 通常在使用過程中,會透過標籤對資源物件進行分類,然後再透過標籤選擇器進行篩選,最常見的應用就是為一組相同標籤的Pod資源物件建立某個Service的端點。
Pod資源對象
Pod是kubernetes的最小調度單元;是一組容器的集合
Pod可以封裝一個活多個容器! 同一個Pod共享網路名稱空間和儲存資源,而容器之間可以透過本地回環介面:lo 直接通信,但是彼此之間又在Mount、User和Pid等名稱空間上保持了隔離。
Pod其實就是一個應用程式運作的單一實例,它通常由共享資源且關係緊密的一個或2多個應用程式容器所組成。
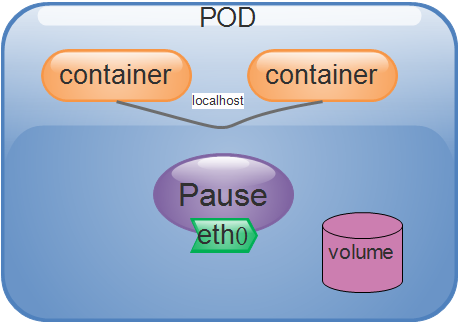
我們將每一個Pod物件類比為一個實體主機,那麼運行在同一個Pod物件中的多個進程,也就類似於實體主機上的獨立進程,而不同的是Pod物件中的各個進程都運行在彼此 隔離的容器當中,而各個容器之間共享兩種關鍵性資源;
網路&&儲存卷。
- 網路:每個Pod物件都會被分配到一個Pod IP位址,同一個Pod內部的所有容器共享Pod物件的Network和UTS名稱空間,其中包括主機名稱、IP位址和連接埠等。 因此,這些容器可以透過本地的回環介面lo進行通信,而在Pod以外的其他元件的通信,則需要使用Service資源物件的Cluster IP+連接埠完成。
- 儲存卷:使用者可以給Pod物件配置一組儲存卷資源,這些資源可以共用給同一個Pod中的所有容器使用,從而完成容器間的資料共享受。 儲存卷還可以確保在容器終止後被重啟,或是被刪除後也能確保資料的持久化儲存。
一個Pod代表一個應用程式的實例,現在我們需要去擴充這個應用程式;那麼就意味著需要建立多個Pod實例,每個實例都代表著應用程式的一個運行副本。
而管理這些副本化的Pod物件的工具,都是由一組稱為Controller的物件實作;例如Deployment控制器物件。
當創作Pod時,我們也可以使用Pod Preset物件為Pod注入特定的訊息,例如Configmap、Secret、儲存磁碟區、磁碟區掛載、環境變數等。 有了Pod Preset對象,Pod模板的建立就不需要為每個模板顯示提供所有資訊。
基於預定的期望狀態和每個Node節點的資源可用性;Master會把Pod物件調度到選定的工作節點上運行,工作節點從指向的鏡像倉庫進行下載鏡像,並在本地的容器運行時環境中啟動 容器。 Master會將整個叢集的狀態保存在etcd中,並透過API Server共用給叢集的各個元件和用戶端
Pod控制器(Controller)
在介紹Pod時我們提到,Pod是K8S的最小調度單位;但是Kubernetes並不會直接部署和管理Pod對象,而是要藉助於另一個抽象資源-Controller來管理。
常見的Pod控制器:
| Pod Controller | | | ————————– | ———————- ————————————– | | Replication Controller | 使用副本控制器,早起僅支援此Pod控制器;完成Pod增減、總數控制、滾動更新、回滾等操作,已停止使用 | | ReplicaSet Controller | 版本更新後使用副本集控制器,並對使用方法進行聲明;是Replication Controller的升級版 | | Deployment | 用於無狀態應用部署,例如nginx等;後續我們會提到HPA Controller(Horizontal Pod Autosaler):用於水平Pod自動伸縮控制器,對rs&deployment進行控制 | | StatefulSet | 用於有狀態應用部署,例如mysql,zookeeper等 | | DaemonSet | 確保所有Node執行同一個Pod,例如網路查件flannel,zabbix_agent等 | | Job | 一次性任務 | | Cronjob | 定時任務 |
控制器是更高階層次對象,用於部署和管理Pod。
以Deployment為例,它負責確保定義的Pod物件的副本數量符合預期的設置,這樣使用者只需要聲明應用程式的期望狀態,控制器就會自動地對其進行管理。
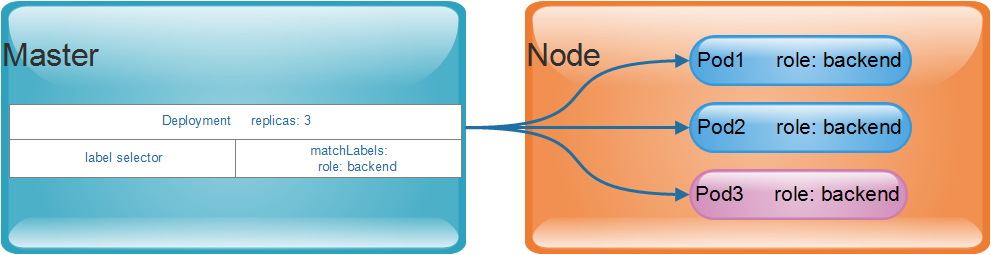
使用者透過手動建立或透過Controller直接建立的Pod物件會被調度器(Scheduler)調度到叢集中的某個工作節點上運行,等到容器應用程式運行結束後正常終止,隨後就會被刪除。
當節點的資源耗盡或故障,也會導致Pod物件的回收。
在K8S的叢集設計中,Pod是一個有生命週期的物件。 那麼就使用了控制器實作對一次性的Pod物件進行管理操作。
例如,要確保部署的應用程式的Pod副本數達到使用者預期的數目,以及基於Pod模板來重建Pod物件等,從而實現Pod物件的擴容、縮容、滾動更新和自癒能力。
例如,在某個節點故障,相關的控制器會將執行在該節點上的Pod物件重新調度到其他節點進行重建。
控制器本身也是一種資源類型,它們都統稱為Pod控制器。 如下圖的Deployment就是這類控制器的代表實現,是目前用來管理無狀態應用的Pod控制器。
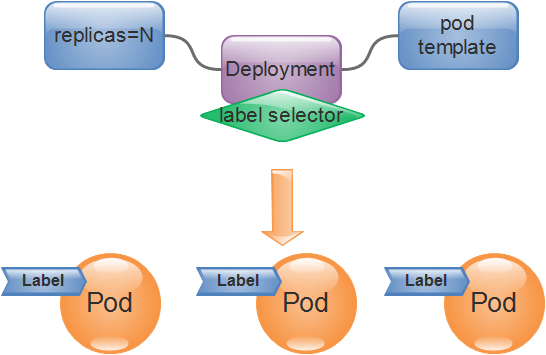
Pod Controller的定義通常由期望的副本數量、Pod模板、標籤選擇器組成。 Pod Controller會根據Labe Selector來對Pod物件的標籤進行匹配篩選,所有符合選擇條件的Pod都會被當前Controller進行管理併計入副本總數,確保數目能夠達到預期的狀態副本數。
在實際的應用場景中,在接收到的請求流量負載低於或接近當前已有Pod副本的承載能力時,需要我們手動修改Pod控制器中的期望副本數量以實現應用規模的擴容和縮容 。 而在叢集中部署了HeapSet或Prometheus的這一類資源監控組件時,使用者還可以透過HPA(HorizontalPodAutoscaler)來計算出合適的Pod副本數量,並自動地修改Pod控制器中期望的副本數,從而實現 應用規模的動態伸縮,提高叢集資源的使用率。
K8S叢集中的每個節點上都運行著cAdvisor,用於收集容器和節點的CPU、記憶體以及磁碟資源的利用率直播數據,這些統計數據由Metrics聚合之後可以透過API server存取。 而HorizontalPodAutoscaler基於這些統計數據監控容器的健康狀態並作出擴展決策。
Service服務資源
| 主要作用or功能 | | | —————————— | —————— —————————————— | | 防止Pod失聯| Service是建立在一組Pod對象之上的資源對象,在前面提過,它是透過Labe Selector選擇一組Pod對象,並為這組Pod對象定義一個統一的固定存取入口( 通常是IP位址),如果K8S存在DNS附件(如coredns)它就會在Service建立時為它自動配置一個DNS名稱,用於客戶端進行服務發現。 | | 定義一組Pod的存取策略,代理Pod | 通常我們直接要求Service IP,該請求就會被負載均衡到後端的端點,即各個Pod對象,即負載平衡器;因此Service本質上是一個4層的 代理服務,另外Service還可以將叢集外部流量引入至集群,這就需要節點對Service的連接埠進行映射了。 |
Pod物件有Pod IP位址,但是該位址在物件重新啟動或重建之後隨之改變,Pod IP位址的隨機性給應用系統依賴關係維護創造了不小的麻煩。
例如:前端Pod應用
Nginx無法基於固定的IP位址負載後端的Pod應用Tomcat。
Service資源就是在被存取的Pod物件中加入一個有著固定IP位址的中間層,客戶端向該位址發起存取請求後,由相關的Service資源進行排程並代理到後端的Pod物件。
Service並不是特定的元件,而是透過規則定義出由多個Pod物件組成而成的邏輯集合,並附帶存取這組Pod物件的策略。 Service物件挑選和關聯Pod物件的方式和Pod控制器是一樣的,都是透過標籤選擇器來定義。
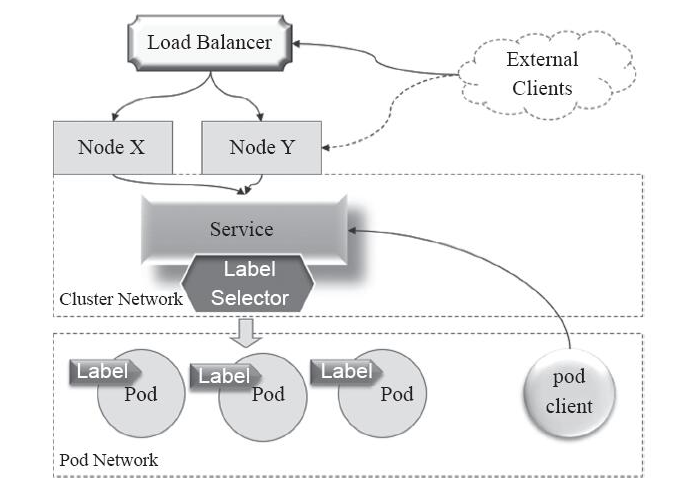
Service IP是一種虛擬IP,也稱為Cluster IP,專用於叢集內通訊
通常使用專有的位址段,如:10.96.0.0/12網絡,各Service物件的IP位址在該範圍內由系統動態分配。
叢集內的Pod物件可直接要求這類Cluster IP,例如上圖中來自Pod client的存取請求,可以透過Service的Cluster IP作為目標位址進行訪問,但是在叢集網路中是屬於私有的網絡 位址,只能在叢集內部存取。
通常我們需要的是外部的存取;將引入叢集內部的常用方法是透過節點網路進行,其實現方法如下:
- 透過工作節點的IP位址+連接埠(Node Port)存取請求。
- 將該請求代理到對應的Service物件的Cluster IP的服務連接埠上,通俗地說:就是工作節點上的連接埠對應了Service的連接埠。
- 由Service物件將該請求轉送至後端的Pod物件的Pod IP和 應用程式的監聽連接埠。
因此,類似上圖來自External Client的叢集外部客戶端,是無法直接請求該Service的Cluster IP,而是需要實作經過某一工作節點Node的IP位址,此時請求需要2次轉送才能到目標Pod 對象。 這一類存取的缺點就是在通訊效率上有一定的延遲。
Ingress
K8S將Pod物件和外部的網路環境進行了隔離,Pod和Service等物件之間的通訊需要透過內部的專用位址進行
例如如果需要將某些Pod物件提供給外部使用者訪問,則需要給這些Pod物件開啟一個連接埠進行引入外部流量,除了Service以外,Ingress也是實現提供外部存取的一種方式。
Volume儲存卷
儲存磁碟區(Volume)是獨立於容器檔案系統之外的儲存空間,常用於擴充容器的儲存空間並為其提供持久儲存能力。
儲存卷在K8S中的分類為:
- 暫時卷
- 本地捲
- 網路卷
臨時捲和本地捲都位於Node本地,一旦Pod被調度至其他Node節點,此類型的存儲卷將無法被訪問,因為臨時捲和本地捲通常用於數據緩存,持久化的數據通常放置於持久卷 (persistent volume)之中。
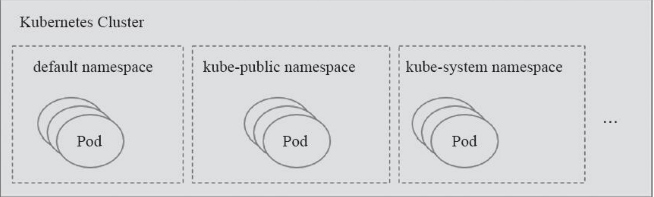
Name和Namespace
名稱空間通常用於實現租戶或專案的資源隔離,從而形成邏輯分組。 關於此概念可以參考Docker文件中的概念https://www.jb51.net/article/136411.htm
如圖:創建的Pod和Service等資源物件都屬於名稱空間級別,未指定時,都屬於預設的名稱空間default
Annotation註解
Annotation是另一種附加在物件上的一種鍵值類型的數據,常用於將各種非識別型元資料(metadata)附加到物件上,但它並不能用於識別和選擇物件。 其作用是方便工具或使用者閱讀、尋找。