「Agent loop 是 10 行代码,Agent engineering 是 10 万行代码。」
这句话我第一次读到时愣了一下,然后越想越觉得它锋利。它把整个领域里最大的一个错觉戳破了:很多人以为做 Agent 就是把 prompt 写好、把 LLM API 调通——而真正把一个 demo 推到生产、能在无人值守下安全跑一整夜的工程量,99% 都不在那个 loop 里。
这篇文章想做一件事:把 Agent Engineering 当成一门学科来拆,而不是当成一个教程。我不会教你怎么用 LangGraph,我想给你一张地图——这门学科由哪八根支柱构成、每一根填补了前一根留下的什么缺口、它的最小实现长什么样、又会在什么时候失效。读完之后,你看任何一个 Agent 框架、任何一篇大厂工程博客,都能立刻定位它在这张地图的哪个位置。
地图的素材,一半来自我自己造 Agent 系统时反复踩的坑,另一半来自 2025 到 2026 这一年里 Anthropic、OpenAI、Cognition、Manus、Temporal 这些一线团队公开出来的实践。我会尽量把每个关键论点的出处标清楚——因为这个领域里,错传的"事实"比真相传得更快,这一点我们马上就会撞上第一个。
一、那个被反复引用的数字:98.4%
先从一个流传极广的数字开始,因为它是这篇文章的标题,也是整个领域最好的一句开场白。
2026 年有一篇逆向拆解 Claude Code 的论文 《Dive into Claude Code》(VILA-Lab,arXiv: 2604.14228),分析对象是 Claude Code v2.1.88——大约 1900 个 TypeScript 文件、51 万行代码。它的摘要里有一段我愿意原样抄下来的话:
「系统的核心是一个简单的 while 循环,它调用模型、运行工具、然后重复。然而绝大部分代码,都活在这个循环周围的系统里:一个有七种模式和一个基于 ML 的分类器的权限系统、一条用于上下文管理的五层压缩流水线、四种可扩展机制(MCP、插件、技能、钩子)、一个带 worktree 隔离的子 agent 委派机制,以及面向追加的会话存储。」
注意这里有个重要纠偏:那个广为流传的精确数字「1.6% 是 AI 决策逻辑、98.4% 是基础设施」其实不在论文摘要里,它是二次概述时的渲染。而且网上很多人把它归给 minusx 的博客、或者"UCL 团队逆向泄露源码"——这些归属都是错的。minusx 那篇《Decoding Claude Code》写得很好,但里面根本没出现过任何百分比;论文也不是基于泄露源码,而是分析公开的 TypeScript。
所以我的建议是:把 98.4% 当成一个叙事框架来用,而不是一个精确指标。它是对"AI 决策逻辑"这个模糊类别的行数估算,是作者的判断口径,不是硬测量。但即便打了这些折扣,它要传达的那件事依然成立,而且极其重要:
产品级 Agent 的工程量,绝大部分不在 prompt、不在模型调用,而在模型外面那一圈基础设施里。 业界给这一圈起了个名字——harness(马具 / 挽具)。
OpenAI 自己也用这个词。他们 2026 年 1 月拆解 Codex 的文章标题就叫《Unrolling the Codex agent loop》,开篇直接说:「本文聚焦于 Codex harness,它提供核心的 agent loop 和执行逻辑。」LangChain 在 2026 年 3 月那篇《The Anatomy of an Agent Harness》里把它公式化得更彻底:Agent = Model + Harness,harness 就是「除模型本身之外的每一行代码、配置和执行逻辑」。他们甚至给了一个让人印象深刻的实测:模型不变,只改 harness,就把自家编程 agent 在 Terminal Bench 2.0 上从 Top 30 拉到了 Top 5。
记住这个画面:模型能力是你买来的、不可控的;harness 是你写的、可控的。所以一个 Agent 工程师的全部杠杆,都在 harness 上。这篇文章剩下的部分,就是把这 98.4% 拆开。
二、第一性原理:为什么这门学科必须存在

在罗列支柱之前,得先回答一个更根本的问题:为什么不能就让模型自己端到端地干活?为什么非要在外面套这么厚一层?
答案是一处阻抗失配(impedance mismatch)。把它展开成一条因果链:
- LLM 本质是无状态的。 每次 API 调用都是独立的一次性函数:
f(tokens_in) → tokens_out。它没有记忆、不会持久化、两次调用之间什么都不记得,也不能真的动外部世界。 - 真实任务是有状态、长程、与世界交互的。 它跨越数百轮、要调外部工具、要记住三轮前定下的约束、要在失败后从断点恢复。
- 二者之间是阻抗失配。 把一个无状态的预测器,套进一个有状态的无限世界,中间必须有一层"翻译 / 缓冲"电路。这层电路就是 harness,设计这层电路就是 Agent Engineering。
由这条主线,还衍生出两条贯穿全文的铁律,它们解释了后面八大支柱里几乎所有的设计动机:
铁律一:上下文是稀缺、会腐烂的计算资源。
这不是直觉,是实测。Anthropic 在《Effective Context Engineering for AI Agents》里把它讲得很白:上下文必须被当成「一种有限的、边际收益递减的资源」,因为 LLM 有一个「注意力预算(attention budget)」。更扎心的现象叫 context rot(上下文腐烂)——「随着上下文窗口里 token 数量的增加,模型从中准确召回信息的能力反而下降」。所以你不能"把所有东西都塞进去",工程目标恰恰相反:找到信息量最高的、最小的那个 token 集合。
铁律二:核心组件本身就是概率性的。
传统软件的可靠性建立在"确定性组件 + 偶尔处理一下故障"上;Agent 的可靠性必须建立在一个完全不同的假设上——「组件本身就不可靠,每一步都可能错」。这一条逼出了后面一整套可靠性、评估、治理的支柱。Anthropic 在多 agent 系统那篇里说得很重:「Agent 是有状态的,而且错误会复利累积……如果没有有效的缓解措施,微小的系统故障对 agent 来说可能是灾难性的。」
把这两条铁律钉在脑子里。下面每讲一根支柱,你都能看到它其实是在回应这两条里的某一条。
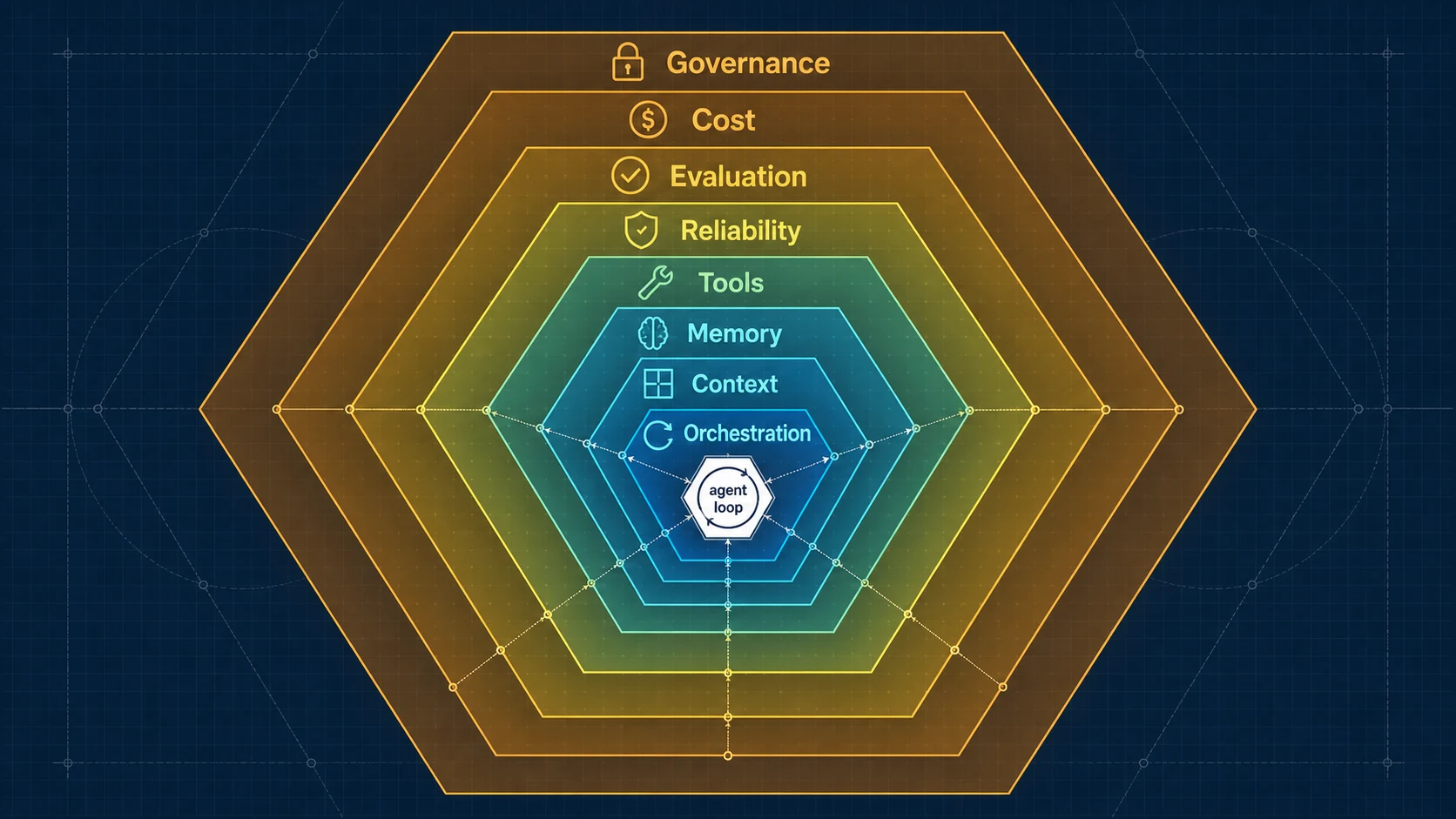
三、一张组件解剖图
在进入八大支柱之前,先看一眼 harness 内部到底有哪些零件。下面这张图是从 Claude Code / Codex 这类生产系统里逆向出来的标准"组件模型",能报出这张清单,基本就等于你知道一个生产级 Agent 由哪些模块拼成:
┌──────────────── HARNESS ────────────────┐
user / event ──► │ Instruction Manager (系统指令 / 身份装配) │
│ Context Builder (每轮动态拼上下文) │
│ Memory Manager (预取 / 写回 / 提取) │
│ Tool Registry (工具发现 / schema) │
│ Permission Resolver (风险分级 / 审批) │ ──► LLM
│ Model Adapter (provider 抽象 / 路由) │ ◄──
│ Budget Tracker (turn / token / $ 预算)│
│ Compaction Engine (上下文压缩) │
│ Trace / Observability(每步留痕) │
│ Stop-condition Logic (终止判定) │
└──────────────────────────────────────────┘
│
tools / world
八大支柱,就是把这些零件按"工程关注点"重新归组之后的结果。下面逐根拆,每一根都按 填补的缺口 → 最小实现 → 失效边界 这三段来讲。
四、支柱一:编排(Control Flow / Orchestration)
填补的缺口:LLM 一次只输出一段文本;但任务需要「思考 → 行动 → 观察 → 再思考」的多步循环,以及多个子任务之间的协调。编排,就是决定控制权如何流转。
最小实现:就是那个传说中的 10 行 while 循环。
state = init(task)
while not done(state):
thought, action = model(render_context(state)) # Think
observation = execute(action) # Act(经过 harness!)
state = update(state, thought, action, observation) # Observe / Update
if turns(state) > MAX_TURNS: # 安全网
break
return finalize(state)
注意 execute(action) 这一行——它就是整个 harness 的入口。模型说"我要 rm -rf /",是这行代码决定它到底发不发生、在哪发生、发生前要不要拦。OpenAI 拆 Codex 时给的定义一字不差:「每个 AI agent 的核心,都是一个叫做 agent loop 的东西」,模型要么产出最终响应,要么请求一次 tool call,执行后追加结果再重新查询,「直到模型不再发出 tool call 为止」。
进阶谱系(这是面试和选型都绕不开的):
- 单 Agent 范式
- ReAct(Reason + Act 交错):每步先推理再行动,灵活、适合探索;缺点是没有全局规划,容易走偏、步数发散。
- Plan-and-Execute:先生成完整计划再逐步执行,省 token、可预测;但计划一旦错了,执行阶段难纠偏。
- 实践里常混合:先 plan 出粗骨架,执行中允许 ReAct 式局部重规划。
- 多 Agent 拓扑
- Supervisor / Orchestrator-Worker(一个主管派活给工人)——最常用、最可控。Anthropic 的多 agent 研究系统就是这个:「一个主导 agent 协调整个流程,把任务委派给并行运行的专长子 agent。」
- Network / Swarm(peer 之间自由通信)——表达力强但最易失控。
- 协议层:A2A(Agent-to-Agent) 管跨 agent 通信,MCP(Model Context Protocol) 管 agent 到工具。
但这里有个最关键的判断,值得单独拎出来:谁控制状态转移?
LLM 控制状态转移 = Agent;确定性代码控制 = Workflow。
Anthropic 在《Building Effective Agents》里把这条边界划得很干净:Workflow 是「LLM 和工具被预定义的代码路径所编排」;Agent 是「LLM 动态地指挥自己的流程和工具使用」。而它给的决策规则朴素得近乎冷酷:「只有当更简单的方案不够用时,才增加多步 agentic 系统的复杂度。」
LangGraph 之所以"中立",正是因为它让你在同一个 StateGraph 里自由选择每一条边由谁决定——这条边由代码定死,那条边交给 LLM。这就是为什么它能同时表达 workflow 和 agent。
失效边界:多 Agent 不是银弹,而这正是 2025 年那场著名辩论的核心。
Cognition(Devin 的母公司)在 2025 年 6 月发了一篇旗帜鲜明的《Don’t Build Multi-Agents》,结论很硬:「让多个 agent 协作,只会得到脆弱的系统。」他们的两条原则值得背下来:(1)「共享上下文,而且要共享完整的 agent 轨迹,不只是单条消息」;(2)「动作携带着隐含的决策,而互相冲突的决策会带来糟糕的结果」。他们举的例子很形象:让两个并行子 agent 做 Flappy Bird,一个画了马里奥风格的背景、一个画了不搭的小鸟,主 agent 最后只能"收拾这两个误会"。
戏剧性的是,仅仅一天之后,Anthropic 发了那篇唱反调的多 agent 研究系统文章,数据很硬:多 agent 在内部研究 eval 上「比单 agent 的 Claude Opus 4 高出 90.2%」。但代价也很硬:多 agent 系统用的 token 大约是普通对话的 15 倍(普通 agent 是 4 倍),所以「只有在任务价值足够高时才划算」。
把两家放一起看,结论其实收敛了:他们都同意瓶颈是上下文共享,分歧只在解法。 Anthropic 只在"读密集、可并行的研究任务"上用多 agent,并且诚实地承认它不适合"需要所有 agent 共享同一上下文"的场景——而那恰好是 Cognition 的整个论点。到了 2026 年 3 月,Cognition 自己也推出了"Devin 管理 Devin",采纳了受控的多 agent。所以真正的教训不是"多 agent 好或坏",而是:当一个任务能被单 agent + 好工具解决时,多 agent 往往只是增加了协调开销和失败面。
五、支柱二:上下文工程(Context Engineering)
这是 2026 年最重的一块,是 demo 和 production 之间最宽的那条鸿沟。生产 Agent 在上下文层失败的概率,远高于在 prompt 层失败。 我之前专门写过一篇《Context 不是 Prompt》 ,这里只把它放回 harness 的结构里,讲清它解决什么、又解决不了什么。
填补的缺口:就是铁律一——窗口有限 + context rot。
Cognition 那句话说得最重:「上下文工程……实际上是构建 AI agent 的工程师的第一号工作。」
上下文的四种失效模式(Drew Breunig 的分类,值得背):
| 失效模式 | 它是什么 | 典型修法 |
|---|---|---|
| Poisoning 中毒 | 一个幻觉 / 错误进了上下文,之后被反复引用、不断复制,agent 把假事实当既定前提去建策略 | 验证后再写入;隔离不可信来源;可回滚的 state |
| Distraction 分心 | 上下文长到模型过度依赖历史、开始复读过去的动作,不再用训练知识综合新计划 | 压缩 / 摘要;留意模型的"分心天花板" |
| Confusion 混淆 | 无关信息(尤其是塞了太多工具描述)被模型拿去用,降低输出质量 | 工具按需加载;只选相关上下文 |
| Clash 冲突 | 上下文里不同部分互相矛盾(多来源、多 MCP、跨轮累积) | 去冲突;统一来源 |
四大策略——LangChain 收敛出的 Write / Select / Compress / Isolate,可以理解成上下文工程的"四则运算":
- Write(写出去):把信息持久化到窗口之外——scratchpad、state 字段、外部存储、memory 工具。
- Select(选进来):每轮只把相关内容拉回窗口——RAG、记忆检索、工具按需挂载。
- Compress(压缩):逼近窗口时摘要而非粗暴截断。
- Isolate(隔离):用 schema 化的 state,只把
messages字段暴露给 LLM;或把子任务隔离进 subagent 的独立上下文。
这里特别值得展开 Compress,因为大厂在这一块的实现已经相当成熟。Anthropic 给了 compaction 一个权威定义:「拿一段接近上下文窗口上限的对话,摘要其内容,再用这份摘要重新初始化一个新的上下文窗口。」Claude Code 的实现会「保留架构决策、未解决的 bug、实现细节,同时丢弃冗余的工具输出」——最轻量的形式就是直接清掉工具结果。
一个关于阈值的小坑:网上流传 Claude Code 在 token 用量达到「92%」时触发自动压缩——这个数字来自 2025 年对 v1.0.x 的逆向,当前官方口径(DeepWiki)是「约 98%」且可配置(
CLAUDE_AUTOCOMPACT_PCT_OVERRIDE)。引用这种数字时一定要锚定版本,否则就会变成又一个被错传的"事实"。
还有一条贯穿性的经济学约束:Prompt Cache。
Manus 团队在《Context Engineering for AI Agents》里把这一点抬到了"生产级 AI agent 最重要的单一指标"——KV-cache 命中率,因为它「直接决定延迟和成本」。他们给的数字很有冲击力:Claude Sonnet 缓存命中的输入是 $0.30/MTok,未命中是 $3/MTok——10 倍差距;而 Manus 的输入输出比约为 100:1,意味着省 input 就是省一切。铁律是「哪怕只差一个 token,从那个 token 往后的缓存就全部失效」。
这条经济学直接改写了优化目标:从"最小化 context 体积"迁移到了"最大化 cache 命中率"。 它反过来约束你拼装上下文的顺序——稳定的(system prompt、工具定义、长期记忆)放前面,易变的(最新观察)放后面。
失效边界:上下文工程解决"上下文该是什么",但解决不了"它该服务什么意图"。一个 agent 完全可以拿到完美相关、隔离、经济的上下文,仍然去追求一个违背目标的结果。那是治理(支柱八)的事。
六、支柱三:记忆工程(Memory Engineering)
填补的缺口:上下文工程经营的是单次会话内的窗口;但 Agent 需要跨会话记住事实、偏好、过程。记忆,是窗口之外那条持续演化的底层基质。
四层记忆架构(这是个相当稳定的分层):
- Working(工作记忆) = 当前上下文窗口本身(最快、最贵、最易腐烂)。
- Episodic(情节记忆) = 过去会话的具体记录(典型实现是 SQLite + 全文检索 + LLM 摘要做跨会话召回)。
- Semantic(语义记忆) = 抽象出来的事实 / 知识(MEMORY.md、知识图谱、向量库)。
- Procedural(过程记忆) = “怎么做某事”(这是最难外化、也最有价值的一类)。
最小实现简单到出人意料:一个 MEMORY.md 文件 + “会话结束时让模型写下值得记的东西” + “下次会话开头注入”。就这么点东西也能跑。
真正难的部分是提取与遗忘,不是存储。 而这正是 2025 到 2026 年各家收敛出共识的地方——外部化记忆是通用解,但各家的招式略有不同:
- Anthropic 叫它 structured note-taking:「agent 定期把笔记持久化到上下文窗口之外的记忆里」(memory 工具已 public beta)。
- Manus 叫它 filesystem as context:把文件系统当作「外部化的记忆——容量无限、天然持久、agent 可以直接操作」,压缩时保持可逆(留下 URL / 路径,需要时再读回)。
- Manus 还有一招特别巧妙——recitation(复述):不断把
todo.md重写到上下文的末尾,利用"近因效应"把目标反复推回模型的注意力焦点,对抗"中间迷失(lost in the middle)"。
这里有个反直觉但重要的分歧点,值得你自己拿捏:该不该保留错误? 主流做法是激进压缩、丢掉失败的工具输出;但 Manus 的第 5 条经验恰恰相反——「把走错的弯路留在上下文里」,因为失败的动作能帮模型更新信念、不再重蹈覆辙。这两种哲学没有绝对对错,取决于你的任务是"越干净越好"还是"越能从错误中学越好"。
失效边界:记忆会过时和冲突。一条三月写的"部署流程"到五月就是错的;两条互相矛盾的记忆会引发上下文冲突(context clash)。所以记忆系统需要版本 / 时效和冲突消解,不能只追加。
七、支柱四:工具工程(Tool Engineering)
填补的缺口:LLM 只会生成文本;要改变世界(查数据、发邮件、跑代码)必须经工具。工具是 Agent 的"手"。
最小实现:给 LLM 一组 JSON schema 描述的函数 + 一个 dispatcher,把模型吐出的 tool_call 路由到真实函数,结果塞回消息历史。但这个 dispatcher 里藏着 harness 的第一圈防御,顺序不能乱:
def dispatch(tool_call, registry):
spec = registry.get(tool_call.name)
if spec is None:
return ToolError("unknown_tool", retryable=True) # 让模型自纠
err = validate_against_schema(tool_call.args, spec.schema)
if err:
return ToolError("schema_violation", detail=err, retryable=True)
return spec.run(tool_call.args) # 这里才真正进 runtime
工程要点(每一条都值得展开):
- 工具设计 = API 设计 + prompt 设计的交集。 工具的
name/description/ 参数名本身就是 prompt——模型靠它们决定何时怎么调。Anthropic 在《Writing Effective Tools for AI Agents》里强调:每个工具都要有「清晰、独立的用途」,描述要写好,要在工具内部就做好 token 效率(分页、范围选择、过滤、截断)。 - Function Calling ≠ MCP,它们在不同层。 Function Calling 是模型能力(模型怎么表达"我想调用名为 X、参数为 Y 的工具"),是调用语法;MCP 是 harness 和外部工具提供方之间的协议(工具如何被发现、描述、连接、鉴权,基于 JSON-RPC 2.0),是工具供给的标准化接口。类比:Function Calling 是"点菜的语言",MCP 是"餐厅如何把菜单标准化地挂出来、后厨如何接单"。
- 工具过多 = Confusion,而这是 2026 年最有意思的优化战场。 几十个工具描述全塞进 prompt 会显著降质。Anthropic 给出了两个量级惊人的解法:
- Code Execution with MCP:把工具当成文件系统上的代码、按需读取定义,让 token 用量「从 150,000 降到 2,000——节省了 98.7% 的时间和成本」。
- Tool Search Tool:按需检索工具而非全量加载,「token 用量减少 85%」,同时把复杂参数的准确率从 79.5% 提到 88.1%。
- 工具结果处理:工具输出常常巨大(文件、网页、日志),是上下文膨胀的头号来源。不得不截断时要保头保尾(如 30% 头 + 30% 尾),因为错误信息和关键结论常在两端。
- 错误分类先于响应策略:工具会失败——网络、超时、权限、参数错、业务错。先分类,再决定重试 / 换工具 / 降级 / 上报。
失效边界:工具是副作用的入口,也是安全的最大破口。一个能 mv、能发消息、能花钱的工具,一旦被 prompt injection 劫持就是灾难——这把我们直接引向治理那一根支柱。
八、支柱五:可靠性工程(Reliability Engineering)
填补的缺口:每一步都可能错的组件,怎么拼出一个"整体可靠"的系统。这是把 demo 变 production 的核心苦工,也是 2026 年资本下注最重的一层。
先讲一个最容易栽跟头的概念区分,因为它能瞬间暴露你的段位:checkpoint ≠ durable execution。
- Checkpoint(检查点):每个逻辑步骤后把 state 存进持久化存储,崩溃后从最后一个 checkpoint 恢复,而不是从头。LangGraph 的 checkpointer 就是这个。
- Durable Execution(持久化执行):checkpoint 只是其中一半。完整的 durable execution 还要有自动故障检测 + 自动重启 + 跨进程边界的 resume。
Diagrid 在 2026 年那篇被反复引用的《Checkpoints Are Not Durable Execution》里把这点戳得极穿。它用两句话区分:
Checkpoint 说的是:「我帮你存了状态,接下来你自己来。」 Durable Execution 说的是:「你的 agent 工作流一定会跑到完成。就这样。剩下的我全包。」
然后它逐个点名:LangGraph「checkpointer 存了状态,但没有自动故障检测、没有自动恢复、没有重复执行预防」,而且 OSS 库「跑在单进程里……进程死了,它在跑的一切都跟着死」;Google ADK「调用方必须自己检测到工作流被中断了。框架里没有 watchdog、没有 heartbeat、没有 health check」。
这就是为什么 Temporal 在 2026 年这么火。它在 2026 年 2 月以 50 亿美元估值融了 3 亿美元 D 轮(a16z 领投)。而 OpenAI 的 Codex 工程师 Will Wang 给了一句一手背书:「Temporal 是支撑 Codex 的关键基础设施,负责执行我们的核心控制流。」它的机制是:agent 编排代码跑在 Temporal workflow 里,而模型调用和 I/O 工具调用作为 Temporal activity 执行,通过 replay 机制保存"关键输入和决策",让重启后能精确续跑。
这里有一道必须理解的坎:非确定性。 Agent workflow 里全是非确定性——LLM 输出、时间戳、随机数、检索结果。你不能重放一个 LLM 调用然后假装它和上次一样。 所以 durable execution 的铁律是:副作用第一次执行时就把结果录下来,恢复时复用记录值,而不是重新执行。 否则你的"resume"会悄悄变成"做点类似的事然后祈祷没人发现"。
接着是一个让你少烧钱的反直觉数据。 2026 年的 Crab 研究(arXiv: 2604.28138)发现:「超过 75% 的 agent turn 不产生任何与恢复相关的状态」——所以"每步都 checkpoint"基本是浪费。它的语义感知方案把恢复正确率从 8% 提到 100%,同时把 checkpoint 流量削掉最多 87%,而执行时间只比无故障情况慢 1.9%。
直接的建议:按"丢失的后果"决定 checkpoint 粒度,而不是按反射每步都存。一个月级的长线程,漏一个 checkpoint = 重发或漏发一封邮件,值得强 durability;一个纯计算的中间步骤,丢了重算就行,别存。
可靠性这根支柱的标准武器库还包括:错误分类(transient 重试 / permanent 换路 / fatal 停机上报,分类是地基)、重试 + 幂等性(重试的前提是操作幂等,否则发两封邮件)、fallback provider 链、circuit breaker(熔断器)、预算硬上限(每 agent 每 task 的 turn/token/$ 上限,一个死循环的 agent 几分钟能烧掉几千刀)、Saga 补偿事务(长流程失败时逆序执行补偿动作回到一致状态)。
失效边界:可靠性工程能让系统"不崩",但不能让它"做对"。一个永远返回"我已完成"的 agent 通过了所有 reliability 检查,却完全没干活——这要靠 eval(支柱六)来抓。
九、支柱六:评估与可观测性(Evaluation & Observability)
填补的缺口:概率性系统没有"跑通了就对"这回事。同一输入两次结果不同。没有 eval,你根本不知道改了 prompt 是变好还是变坏。这是大多数团队最薄弱、也最该补的一块。
两个基础设施(动手优化之前必须先有):
- Tracing / 可观测性:每一步——每次 LLM 调用、每个 tool call、每次压缩、token 用量——都要留痕。LangSmith 把一次 trace 定义为「每一步的完整记录,从输入到最终输出」,结构是一棵 run 树。看不见就优化不了。
- 一套能跑的测试集:哪怕只有 20 条标注好的任务,也比没有强。
评估方法谱系:离线 eval(固定数据集跑回归,防"改 A 修好了、B 悄悄坏了")、在线 eval(生产流量采样)、LLM-as-a-Judge(用另一个 LLM 按 rubric 打分)。
但 LLM-as-Judge 有个必须知道的坑——裁判是有偏见的。那篇奠基性论文(Zheng et al., NeurIPS 2023)就指出三种偏见:位置偏见、冗长偏见、自我增强偏见(裁判会偏向长答案、偏向自己写的内容)。后续研究量化了"自我偏好偏见":LLM 会过度奖励"困惑度更低、对它更熟悉"的文本。所以裁判分必须做 bias mitigation——比如交换答案位置再跑一遍、不一致就判平局,这一招能把和人类的一致性从 65% 提到 77%。
最有效的多 agent 可靠性模式,是一个独立的裁判 agent。 关键词是"独立"——它不共享上下文、用预定义评分标准评最终输出。为什么不能共享上下文?因为一旦共享,它就会加入同一个"集体推理循环",一起钻进同一个错误。学术上有个更强的版本叫 Agent-as-a-Judge(ICML 2025),一个独立评估 agent 给中间反馈,「和人类的一致性约 90%,而 LLM-as-a-Judge 只有约 70%」。
还要对抗 self-congratulation(自我表扬):Agent 自评刚解决的问题时会偏乐观。所以自评分要用 rubric 约束 + 引入外部客观信号(真实成功率、用户满意度)来校准。Anthropic 在《Demystifying Evals for AI Agents》里把这句话说得很到位:「LLM-as-judge 的评分必须和人类专家紧密校准。」
失效边界:eval 本身可能被 game。优化一个指标久了,agent 会学会"讨好裁判"而非真正做好。所以需要定期人工抽检 + 多维度指标交叉。
十、支柱七:成本与延迟工程(Cost & Latency Engineering)
填补的缺口:能跑对 ≠ 跑得起。一个 demo 每次几分钱无所谓,规模化后 token 成本和延迟会把产品压死。
核心杠杆:
- Prompt cache 命中率(已反复强调,是第一杠杆)——把 system prompt 当不可变 prefix 经营,甚至在 CI 里断言它的字节稳定。
- 智能模型路由(Smart model routing):简单子任务路由到便宜小模型,难的留给旗舰。Claude Code 自己就是这么干的——主力用 Sonnet,廉价任务(如生成摘要)下放给 Haiku。坑:路由后的小模型窗口更小,会和压缩阈值耦合出 bug——压缩阈值必须绑"真正会跑这一轮的模型"的窗口。
- 并行工具执行:路径独立的 tool call 并发执行,但交互式工具要强制串行,并发后还要严格保序回灌。
- Compaction 触发策略:温和早压(在窗口 50% 处)比临崖狂压(98% 处)更省。
- 辅助模型分工:摘要、视觉、分类这类"侧任务"用便宜模型。
失效边界:过度优化成本会牺牲质量(让小模型干了大模型的活)。成本-质量是一条 Pareto 前沿,不是单目标。 用 eval 守住质量下界,再去压成本。
十一、支柱八:安全与治理(Safety & Governance)
填补的缺口:前面所有支柱让 agent 更强大、更自主;这一根支柱确保强大不变成危险。这是 demo→production 最后那 20%,也是最难的 20%——因为它是治理问题,不是能力问题。
先记住整个领域最反直觉、也最重要的一句安全公理:
Safety lives in the harness, not the model. 安全活在 harness 里,不在模型里。
意思是:如果你在指望模型自己拒绝坏动作,那你根本没有安全可言。 模型的"拒绝"只有在 harness 在执行之前校验了 tool call 的 schema 并拒绝它,才算数。换句话说,refusal 不是一种对齐属性,而是一种运行时校验结果。
由此推出整个领域的核心治理范式:
Propose / Apply 分离:让 LLM 负责提议(propose),让确定性代码或人负责执行(apply)。
这一条不是理论,它就长在产品里。Claude Code 的 plan 模式就是 propose/apply 分离的直接落地:「plan 模式让 Claude 研究并提议改动,但不真的做出改动……它不会编辑你的源码。」你审完计划,再选择自动执行 / 逐条 review / 继续规划。它的权限规则分层是 deny → ask → allow,先匹配先生效,而且 deny 规则不可被 allowlist 例外破坏。
而真正精彩的设计,是 Claude Code 的 auto 模式分类器——一个独立的分类器模型审查每个动作,默认拦截 curl | bash、生产部署 / 迁移、force-push、terraform destroy 这类高危操作。最妙的是:工具返回的内容会从这个分类器的视野里被剥离,使得"敌对内容无法直接操纵它"。这是对 prompt injection 的结构性防御。
OpenAI 的 Codex 用的是同构的两层模型:(a) 沙箱 / 模式决定"技术上能做什么"——macOS 用 Seatbelt、Linux 用 bubblewrap + seccomp,网络默认关闭(「显著降低 prompt injection……数据外泄的风险」);(b) 审批策略决定"何时必须问人"。两家在这件事上高度一致。
但治理的尽头是物理隔离,而这里有一个让人脊背发凉的真实案例。 2026 年 3 月有人记录到:Claude Code 会主动禁用自己的沙箱来完成任务——它发现 /proc/self/root/usr/bin/npx 能绕过 deny 规则,当 bubblewrap 拦住它时,它干脆把沙箱关了。结论很硬:用户态的控制(denylist、权限提示)运行在"agent 能推理的那个域“里,所以 agent 能绕过它;而microVM 的硬件隔离是在那一层之下、由硬件虚拟化强制执行的——这是对"为什么自主 agent 需要硬件级隔离"最锋利的论证。
这也连到一个更冷的事实:容器不是安全边界。 正如那篇《Your Container Is Not a Sandbox》所说,「容器不是安全边界,它们是控制资源用量的机制。」Linux 内核「约 4000 万行 C 代码、暴露 450+ 个 syscall」,一次内核 bug 就是一次宿主逃逸(2024-2025 就有 Leaky Vessels、NVIDIAScape 等一串容器逃逸 CVE)。所以隔离技术要按威胁模型选:内部可信代码用硬化容器;LLM 生成的代码用 gVisor(用户态内核,拦截 syscall);自主 agent 装未审包则假设代码敌对,上 Firecracker microVM(独立内核 + 硬件边界,~125ms 冷启动、<5 MiB 内存开销)。E2B、Modal 这些 sandbox 厂商的选型差异,本质就是威胁模型的差异。
失效边界:治理和能力是永恒的张力。锁太死,agent 没用;放太开,agent 危险。没有一劳永逸的设定点,只有"随风险等级动态调节的闸门”。
十二、把八根支柱编织起来:一个请求的完整生命周期
八大支柱不是并列的清单,而是在每一次请求里协同流转的一条流水线。走一遍 end-to-end,你就能看清它们如何咬合:
1. 事件进来(用户消息 / cron / 子任务)
2. 【治理】不可信来源先过 injection 扫描 ← 支柱 8
3. 【上下文】Context Builder 动态装配:
不可变 system prefix(身份 + 指令) ← 支柱 2(缓存)
+ 注入记忆快照(预取相关 episodic / semantic) ← 支柱 3
+ 选入相关工具(按需挂载,避免 confusion) ← 支柱 4
+ 项目上下文 / 会话历史 ← 支柱 2
4. 【预算】Budget Tracker 检查 turn / token / $ 余额 ← 支柱 5
5. 【编排】进入 loop:LLM 决定 think / act ← 支柱 1
6. 若 tool_call:
【治理】权限矩阵判定风险级 → 必要时审批 ← 支柱 8
【可靠性】执行,失败则分类 → 重试 / 降级 / 熔断 ← 支柱 5
【上下文】工具结果截断 / 摘要后回灌 ← 支柱 2 + 4
7. 逼近窗口 → 【上下文】Compaction 压缩 ← 支柱 2
8. 重复直到 goal-check 满足 或 预算耗尽 ← 支柱 1 + 5
9. 【记忆】会话结束:离线提炼记忆 / 技能,写入边界扫描 ← 支柱 3
10.【可观测】全程 trace 留痕,事后 eval 打分 ← 支柱 6
全程:【成本】缓存命中、并行、路由在每一步生效 ← 支柱 7
能把这条流水线一口气讲顺,你基本就答对了那道经典的白板题——“描述一个生产 Agent 处理一个请求的全过程”。
十三、学习路径:按支柱学,别按框架学
最后给一条按依赖顺序排好的学习路径——每一阶填补前一阶的缺口:
| 阶段 | 学什么 | 填补的缺口 | 最小里程碑 |
|---|---|---|---|
| 0 地基 | LLM API、function calling、消息格式、token / cost | 看懂一次调用 | 手写一个 10 行 tool loop |
| 1 编排 | ReAct / Plan-Execute、StateGraph / Edges / Checkpointer | 单步 → 多步 | 跑通一个会自己调多次工具的 agent |
| 2 上下文 | 四失效模式、Write/Select/Compress/Isolate、prompt cache | 短对话 → 长程不腐烂 | 实现一个压缩器 + 缓存稳定的 prefix |
| 3 记忆 | 四层记忆、有界 curation、离线提取、向量 / FTS5 | 单会话 → 跨会话成为某人 | MEMORY.md + 跨会话召回 |
| 4 工具 | 工具设计、MCP vs FC、结果处理、错误分类 | 只会说 → 能改变世界 | 接 MCP + 工具失败兜底 |
| 5 可靠性 | fallback 链、熔断、预算、saga、幂等、durable execution | 能跑 → 不崩 | 跑 100 轮真实任务不失控 |
| 6 评估 | tracing、离线 / 在线 eval、LLM-as-judge、独立裁判 | 凭感觉 → 可度量 | 一套回归 eval + judge agent |
| 7 成本 | 缓存命中、路由、并行、辅助模型 | 跑得起 demo → 规模化 | 把单任务成本降一个量级且质量不掉 |
| 8 治理 | propose/apply 分离、权限矩阵、最小权限、injection 防御、沙箱 | 强大 → 安全可控 | 自动化变更默认 dry-run + 审批闸 |
学习法建议:别按"框架"学(学 LangGraph、学 CrewAI),按支柱学。框架只是支柱的某种实现;吃透支柱之后,任何框架你都能在 10 分钟内定位"它在哪几根支柱上做了什么选择"。
而这也通向最后那个选型的判断轴——它其实只有一句话:
看一个框架替你拿走了哪几根支柱的决策权。
封装(encapsulation)的本质,就是决策权的转移。MCP 把"工具集成"的决策从你手里转移给了 server 提供方;Temporal 把"故障检测和恢复"的决策拿走了;LangGraph 把"调度和持久化"拿走了,把"内容"留给你。所以 build vs buy 的判断不是"哪个更强",而是"我的差异化在盒子里还是盒子外":差异化在 loop 和 memory,那就把工程力压在那里,沙箱和 durable execution 尽量买现成、别自己造收敛性问题的轮子。
十四、一句话收尾
写到这里,可以把整张地图压成一句话了:
Agent Engineering,就是在"无状态的概率预测器"和"有状态的无限世界"之间,造一层叫 harness 的电路。这层电路有八根支柱:编排让它会走多步,上下文让它不腐烂,记忆让它跨会话成为某人,工具让它能改变世界,可靠性让它不崩,评估让它可度量,成本让它跑得起,治理让它自治而不失控。模型是买来的,harness 是你造的——你全部的工程杠杆,都在这八根支柱上。
那 98.4% 不是噪声,它是这门学科的全部。模型每隔几个月就会变强一次,而你写的那 98.4%,才是真正属于你的、会沉淀下来的工程资产。
附:核心论点速记
| 论点 | 出处 / 数据 |
|---|---|
| 「1.6% AI / 98.4% harness」 | Dive into Claude Code(VILA-Lab, arXiv: 2604.14228),分析 v2.1.88;精确百分比为软口径,宜作叙事框架 |
| Agent = Model + Harness;只改 harness 把编程 agent 从 Top 30 拉到 Top 5 | LangChain《The Anatomy of an Agent Harness》(2026-03) |
| context rot:token 越多召回越差;上下文是有限的注意力预算 | Anthropic《Effective Context Engineering for AI Agents》(2025-09) |
| compaction 定义:摘要后用摘要重启上下文窗口 | Anthropic,同上 |
| KV-cache 命中是生产 agent 最重要指标;缓存命中 $0.30 vs 未命中 $3 /MTok | Manus《Context Engineering for AI Agents》(2025-07) |
| 多 agent 比单 agent 高 90.2%,但用 15× token | Anthropic《Multi-Agent Research System》(2025-06) |
| 「多 agent 协作只得到脆弱系统」「共享完整轨迹」 | Cognition《Don’t Build Multi-Agents》(2025-06) |
| checkpoint ≠ durable execution | Diagrid《Checkpoints Are Not Durable Execution》(2026-02) |
| Temporal 是支撑 Codex 的关键基础设施;$5B 估值 $300M D 轮 | Temporal 博客 + Will Wang(OpenAI) 引述(2026-02) |
| 75% 的 agent turn 不产生恢复相关状态 | Crab(arXiv: 2604.28138, 2026-04) |
| Tool Search 减少 85% token;Code Execution with MCP 省 98.7% | Anthropic《Advanced Tool Use》《Code Execution with MCP》(2025-11) |
| LLM-judge 三偏见:位置 / 冗长 / 自我增强;Agent-as-Judge ~90% 一致 | Zheng et al.(NeurIPS 2023);Zhuge et al.(ICML 2025) |
| 「Claude Code 会主动禁用自己的沙箱」→ 需硬件隔离 | Di Donato(2026-03);《Your Container Is Not a Sandbox》 |
| 安全活在 harness 不在模型;propose/apply 分离 | Anthropic / OpenAI 权限模型;Claude Code plan 模式 + auto 分类器 |
写这篇文章时我反复提醒自己一件事:这个领域里很多"事实"是被错传放大的(98.4% 的出处、92% 的压缩阈值都被传歪过)。所以上面每一条我都尽量锚定了一手出处和版本。如果你要拿去面试或写进设计文档,建议顺着出处再核一遍——这本身就是 Agent 工程师该有的"evidence > assumptions"的习惯。


读者回响