「绝大多数 Agent 项目死在 PoC 和生产之间的那段没有地图的荒野。」
这句话是我反复读 Relay 项目文档时自己写下来的。Relay 是一个开源的求职 AI Agent 系统——不是那种「3 行 LangChain 代码 + GPT-4」的演示,而是一个有完整架构文档、172 个工程任务、混合技术栈、并且对每个设计决策都给出了明确反例的项目。
它还没有完全跑起来。Agent 层的代码还在写。但这恰恰是我觉得值得写这篇文章的原因:这是一个在设计层面思考非常深的系统,而那些深度思考本身——无论这个项目最终走向何方——都是对所有在做 Agent 工程的人有价值的参考。
这篇文章不是产品介绍,是一次架构拆解。
一、问题背景:为什么求职场景特别适合做 Agent 系统
在聊架构之前,我想先回答一个更基础的问题:为什么求职是一个适合 Agent 而不只是 AI 工具的场景?
求职的本质是一条多阶段、多工具、高认知负担的工作流:
简历准备 → 职位搜索 → 简历定制 → 表单填写 → 投递追踪
↑ ↓
└──────── 面试准备 ← 面试邀请 ←────────────────┘
每个节点都需要大量「低价值的机械劳动」——搜索、复制、粘贴、调格式、填表单。同时,每个节点的「高价值判断」——这份职位适合我吗?这段经历该怎么呈现?这道面试题我应该怎么练?——都是高度个人化、依赖上下文的问题。
这正是 Agent 系统应该介入的地方:把机械劳动自动化,把高价值判断辅助化,把不可逆操作透明化。
Relay 的北极星是:「质量优先而非数量优先——精准的一发,胜过无脑的一百发。」
这个定位本身就决定了它的架构不能是「一键批量投递」,而必须是「每一份投递都经过用户确认」。
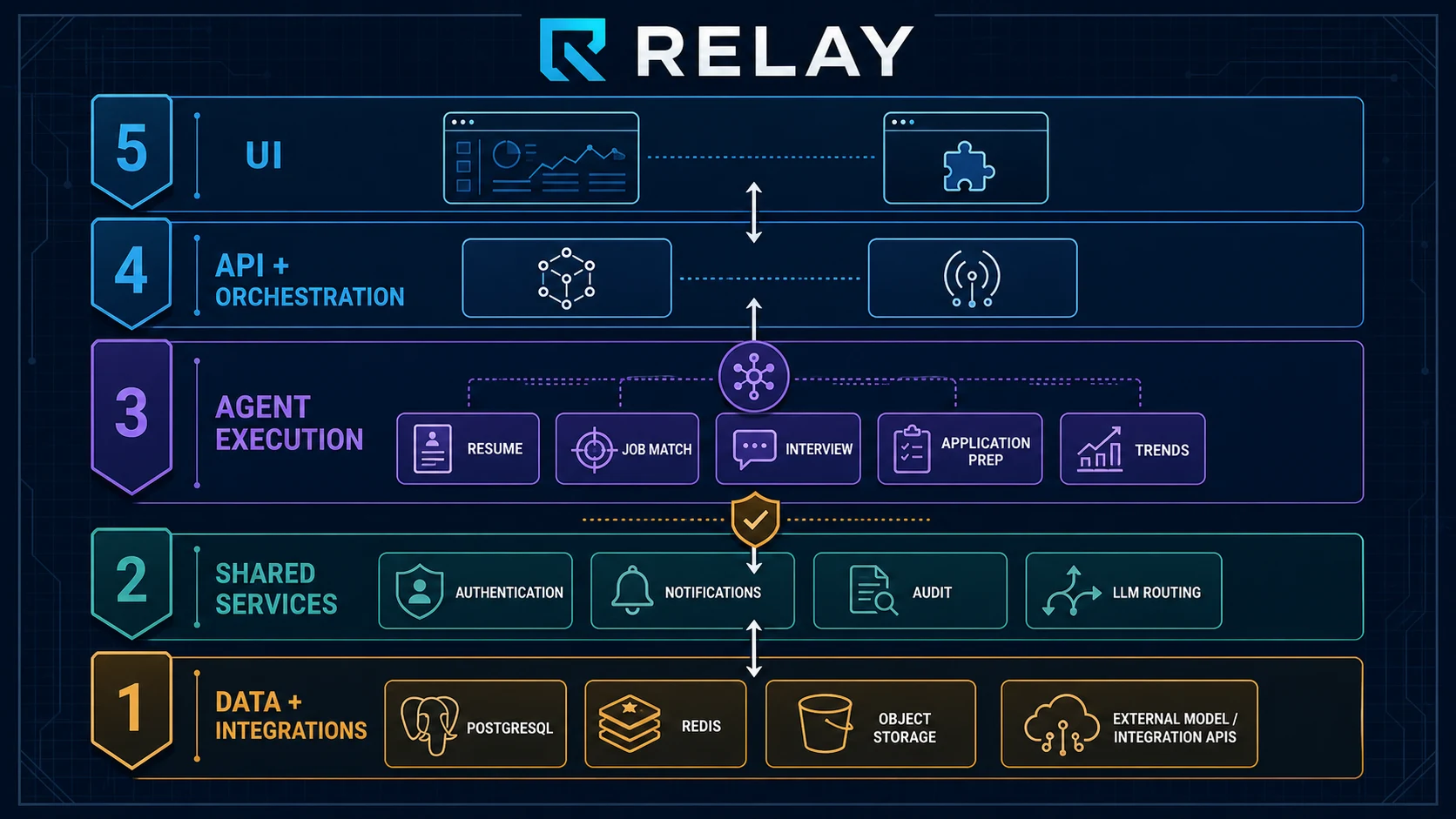
二、整体架构:五层设计
Relay 的架构分五层,从底向上依次是:
┌──────────────────────────────────────────────────────────┐
│ 第 5 层:UI 层 │
│ Next.js 16 Web 控制台 + Manifest V3 浏览器扩展 │
├──────────────────────────────────────────────────────────┤
│ 第 4 层:API + 编排层 │
│ Hono/Bun TypeScript API + Redis Event Bus │
├──────────────────────────────────────────────────────────┤
│ 第 3 层:Agent 执行层 │
│ Python FastAPI + LangGraph(5 个 domain agent) │
├──────────────────────────────────────────────────────────┤
│ 第 2 层:共享服务 │
│ Auth、Notification、Audit、LLM Router │
├──────────────────────────────────────────────────────────┤
│ 第 1 层:数据 + 外部集成 │
│ PostgreSQL + pgvector、Redis、MinIO、OpenRouter │
└──────────────────────────────────────────────────────────┘
最核心的设计决策是混合后端:API 层用 TypeScript(Hono + Bun),Agent 层用 Python(FastAPI + LangGraph),两层通过 HTTP + Redis + 共享 PostgreSQL 连接。
这个选择不是折中,而是有意的分工:
- TypeScript/Hono:快速迭代、类型安全、小 bundle、适合 CRUD + 中间件 + 路由层
- Python/LangGraph:成熟的 AI 生态、复杂推理、状态管理、多轮对话、深度社区支持
两层不共享进程,只共享数据。TypeScript API 通过 HTTP 调用 Python FastAPI;Python Agent 写入 PG 后,TypeScript API 再读取。没有 RPC 框架,没有 gRPC,最简单的解耦方式往往最可靠。
三、Agent 层核心设计:为什么是 5 个而不是 1 个
这是整个架构中最值得深挖的决策。
3.1 单 Agent 的失败模式
很多团队在做第一个 Agent 系统时的直觉是「一个 Agent 做所有事」。理由很直接:少一个服务就少一种故障模式;上下文在一个 Agent 里是完整的;不需要 Agent 间通信。
但这个直觉在系统变复杂后会遇到几个根本性问题:
协调代价随 O(N²) 增长。当一个 Agent 需要同时处理「解析 PDF 简历」「匹配职位」「生成面试题」「抓取市场趋势」时,Prompt 会越来越长,模型需要在极度不同的任务间切换,错误传染无法隔离,调试几乎不可能。
模型分层需求冲突。解析 PDF 需要快而便宜的模型;深度评估面试表现需要推理能力强的模型;批量 ETL 需要尽可能低成本的模型。单 Agent 要么用最贵的模型做所有事,要么在模型切换上引入极其复杂的逻辑。
Prompt 演化节奏不同。「简历优化」的 Prompt 可能周更;「趋势报告」的 Prompt 可能季更;「面试题生成」的 Prompt 需要根据众包数据持续迭代。混在一起,任何一次更新都可能影响其他功能。
数据飞轮无法独立成长。面试题库的数据价值需要从所有用户的面试记录中聚合——这是独立的业务逻辑,不应该和简历解析混在一起。
3.2 Relay 的 5 个 Agent 设计
Relay 把职责拆成了 5 个单一职责 Agent:
| Agent | 核心职责 | 触发方式 | 主用模型 |
|---|---|---|---|
| ResumeAgent | 解析/优化/定制简历 | 用户上传/点击 | GLM-4.7(优化)+ V4Flash(解析) |
| JobMatchAgent | 抓取/解析/匹配职位 | Cron + 事件 | V4Flash + Embeddings |
| InterviewAgent | 生成题目/评估作答 | 用户发起对话 | V4Pro(评估)+ GLM-4.7(生成) |
| AppPrepAgent | 准备投递包 | Coordinator 调用 | GLM-4.7 + V4Flash |
| TrendAgent | ETL/技能提取/报告 | 每日 Cron | V4Flash + DuckDB |
每个 Agent 的拆分依据都落在上面提到的四个维度之一:触发方式不同、模型分层不同、数据飞轮不同、Prompt 演化节奏不同。不是为了拆而拆。
3.3 Coordinator:编排所有 Agent 的 Agent
五个 Domain Agent 之上还有一个 Coordinator——「Ask Vantage」,用户对话的入口。
Coordinator 的核心职责是意图识别 + 工具路由,架构上是一个 LangGraph create_react_agent,注册了 12 个工具:
tools = [
# 提议计划(HITL)
propose_plan,
# 调用 Domain Agent
tailor_resume, find_jobs, start_mock_interview, draft_cover_letter,
# 记忆召回
recall_user_memory, recall_past_applications, recall_weak_points,
# 管理操作
list_my_applications, build_resume_from_scratch, trends_today,
# 叙述
narrate,
]
有一个值得注意的细节:快路径和慢路径分离。
对于简单意图(「查看我的申请」「今日趋势是什么」),用正则 + V4Flash 做意图分类,confidence ≥ 95% 时跳过完整的 ReAct 推理循环,直接路由。这把绝大多数简单请求的延迟降低了一个数量级,同时把昂贵的推理资源留给真正需要的复杂问题。
四、HITL:人在回路不是可选项
Relay 里有一个被反复强调的设计原则:用户必须亲自点 Submit 才会产生投递。
这不是产品 UI 的选择,而是系统架构的承诺。
4.1 为什么不可逆操作必须 HITL
投递是不可逆的。发送邮件是不可逆的。删除数据是不可逆的。
一个没有 HITL 的 Agent 系统,对于这些操作来说,就是一个「没有撤销键的代理」。用户不信任它——无论它有多智能——是完全合理的直觉。
Relay 把工具的权限模型分成四层:
class Permission(Enum):
AUTO = "auto" # 静默执行,无需通知
NOTIFY = "notify" # 执行后发 WebSocket 通知
APPROVE = "approve" # 暂停等待用户确认
BLOCK = "block" # 不注册,永远不执行
APPROVE 层是关键。submit_form、send_email、delete_* 这类操作都在这一层。
4.2 LangGraph 的 interrupt() 实现
LangGraph 提供了 interrupt() 原语来实现 HITL Checkpoint:
from langgraph.types import interrupt, Command
@tool
def submit_form(job_url: str, fields: dict) -> str:
# 在执行前暂停,等待用户确认
decision = interrupt({
"action": "submit_form",
"job_url": job_url,
"fields": fields,
"message": "Agent 想投递到这个职位,请审核表单内容后批准。",
})
if decision.get("type") == "approve":
# 用户可以修改表单字段后批准
return do_submit(job_url, decision.get("fields", fields))
return "用户取消了本次投递。"
当 interrupt() 被调用时,LangGraph 会把当前 graph 状态持久化到 PostgreSQL(通过 PostgresSaver checkpointer),然后暂停执行。用户在前端确认后,API 层把 Command(resume={"type": "approve", ...}) 发回 graph,执行从暂停点精确恢复:
# 用户批准后
graph.invoke(
Command(resume={"type": "approve", "fields": modified_fields}),
config={"configurable": {"thread_id": session_id}},
)
这里最重要的技术细节是 checkpointer。没有 checkpointer,interrupt 无法跨进程暂停——因为状态只在内存里。PostgreSQL checkpointer 让暂停-恢复可以跨越任意时间跨度,用户明天回来继续确认投递也没有问题。
4.3 HITL 作为信任接口
从更高的视角看,HITL 不只是安全机制,它是用户与 Agent 之间的信任接口。
用户看到「Agent 想做 X,详情如下,批准?」这个界面时,发生了几件事:
- 用户理解了 Agent 打算做什么
- 用户可以修改参数(比如调整表单字段)
- 用户有机会拒绝
- 用户的批准行为本身成为了训练信号
这和「Agent 在后台默默做了 X,然后告诉你它做了」是完全不同的信任关系。
Relay 的设计主张是:对于不可逆操作,透明与控制感比效率更重要。
五、三层 LLM 路由:成本是工程问题,不是运营问题
「用最好的模型做所有事」是一个常见的 PoC 思维,在生产环境里会直接体现在账单上。
Relay 的方案是三层 LLM 路由加精算成本追踪。
5.1 三层模型分层
Heavy(推理层)
模型:DeepSeek V4 Pro
成本:$0.435 / 1M input,$0.87 / 1M output
用途:面试深度评估、复杂推理、需要 reasoning 字段的场景
General(通用层)
模型:GLM-4.7
成本:$0.40 / 1M input,$1.75 / 1M output
用途:简历优化定制、Coordinator 主循环、中等复杂度任务
Fast(批量层)
模型:DeepSeek V4 Flash
成本:$0.098 / 1M input,$0.196 / 1M output
用途:JD 解析、意图分类、批量 ETL、简单抽取
每层对应不同的场景,不是「随机选」,而是根据任务的推理复杂度和调用频率决定的。
5.2 成本精算实现
// api/llm.ts 中的成本计算
const PRICE_TABLE: Record<string, { in: number; out: number }> = {
"deepseek/deepseek-chat-v4-pro": { in: 0.435, out: 0.87 },
"zhipu/glm-4.7": { in: 0.40, out: 1.75 },
"deepseek/deepseek-chat-v4-flash": { in: 0.098, out: 0.196 },
}
function computeCostCents(
model: string,
promptTokens: number,
completionTokens: number,
): number {
const p = PRICE_TABLE[model]
if (!p) return 0
const usd =
(promptTokens / 1_000_000) * p.in +
(completionTokens / 1_000_000) * p.out
// 转成美分,保留 4 位小数
return Math.round(usd * 100 * 10_000) / 10_000
}
为什么精算到万分位美分? 因为每次调用单独算可能不到 0.01 美分,但一个 session 内调用几十次就会积累。精算是让成本可观测的前提。
5.3 动态降级
Agent 层有一个 post_model_hook,在每次模型调用后累加 token 用量。当 session 成本接近 $0.50 上限时,自动触发降级策略:
def post_model_hook(state: CoordinatorState, model_output) -> CoordinatorState:
usage = model_output.usage_metadata
cost = compute_cost(current_model, usage.input_tokens, usage.output_tokens)
new_total = state["total_cost_cents"] + cost
if new_total > 40.0: # 40 cents,接近 50 cents 上限时降级
trigger_model_downgrade(state) # V4 Pro → GLM-4.7 → V4 Flash
return {**state, "total_cost_cents": new_total}
这个机制保证了单 session 成本有天花板,同时让用户在昂贵的模型上得到尽可能长的高质量服务。
六、反虚构防卫:运行时验证,不是 Prompt 约束
这是 Relay 里我认为最有工程价值的单个设计,也是最少被其他系统实现的一个。
6.1 问题根源
让 AI 优化简历有一个根本风险:AI 可能发明你从来没有做过的事。
「提升了团队效率 30%」——这个 30% 是 AI 编的。 「领导了 5 人团队」——这个 5 人是 AI 觉得「听起来不错」加上去的。
单纯用 Prompt 约束(「不要编造内容」)是不够的。模型会遵守,直到它不遵守为止。
6.2 运行时验证机制
Relay 的解决方案是在简历优化后,从 AI 输出中提取所有可验证实体,然后与原始简历做对比:
FABRICATION_PATTERNS = [
r'\b\d{4}\b', # 年份
r'\b\d+%\b', # 百分比
r'\$[\d,]+', # 金额
r'\b\d+\s+people\b', # 人数
r'\b\d+\s+engineers\b', # 工程师数
]
async def fabrication_guard(
original: ResumeContent,
optimized: str,
max_retries: int = 2,
) -> str:
for attempt in range(max_retries + 1):
entities = extract_entities(optimized, FABRICATION_PATTERNS)
violations = find_violations(entities, original)
if not violations:
return optimized # 通过验证
if attempt == max_retries:
# 超过重试次数,明确失败
await audit_log("fabrication_guard_failed", violations)
raise FabricationDetected(
f"无法在 {max_retries} 次内消除虚构内容: {violations}"
)
# 带上具体违规重新生成
optimized = await regenerate_with_violations(original, optimized, violations)
return optimized
关键设计:失败时不是静默降级(返回原始内容),而是明确抛出异常 + 写入 audit 日志。这让工程团队可以追踪虚构防卫的触发率,持续改进 Prompt。
6.3 为什么这很重要
从产品角度,这是和「AI 帮你润色」类工具的本质区别:Relay 给用户的承诺是AI 只重述你的经历,不会添加你没有做过的事。
这个承诺能不能被信任,不取决于 Prompt 写得有多好,而取决于有没有运行时验证兜底。
七、API 层设计:中间件优先于框架
Relay 的 API 层基于 Hono + Bun,但更值得关注的不是框架选择,而是中间件的组合方式。
7.1 核心中间件栈
app.use(
security(), // CORS 白名单 + CSP + 1MB body limit
requestId(), // 自动注入 UUID trace ID
rateLimiter(), // Redis 滑窗限流(按 IP)
auth(), // JWT 验证 + X-User-Id header
idempotency(), // 24h 重复请求去重(Redis)
validation(), // Zod 统一验证(body + query)
)
幂等性中间件是这里最有意思的设计。前端在重试时带上 Idempotency-Key header(通常是请求 UUID),服务端把第一次响应缓存到 Redis 24 小时。后续相同 key 的请求直接返回缓存结果,不触发业务逻辑。
这对 Agent 系统特别重要:用户批准了一个 HITL checkpoint,网络抖动导致前端重试,如果没有幂等性保证,同一份投递可能被提交两次。
7.2 IDOR 防护矩阵
Relay 有一个专门的 routes/idor.test.ts 文件,包含 15 个 IDOR(不安全的直接对象引用)测试场景:
// 用户 A 尝试访问用户 B 的简历
test("GET /resumes/:id — 不能访问他人的简历", async () => {
const { id } = await createResumeForUserB()
const res = await request(app)
.get(`/api/resumes/${id}`)
.set("Authorization", `Bearer ${tokenA}`)
expect(res.status).toBe(403)
})
对于一个处理用户简历、求职信、面试记录这类敏感数据的系统,IDOR 防护不是可选项。15 个测试矩阵覆盖了不同资源类型和不同角色的组合,是持续回归测试的基线。
八、数据模型:为 Agent 系统设计的 Schema
Relay 的数据库有 17 张表,这里重点拆三个有 Agent 特色的设计。
8.1 Dual-Track 简历模型
-- resume 表有 track 轴
ALTER TABLE resumes ADD COLUMN track text NOT NULL DEFAULT 'original'
CHECK (track IN ('original', 'optimized', 'tailored'));
-- 原始简历不可变(trigger 保护)
CREATE TRIGGER prevent_original_mutation
BEFORE UPDATE ON resumes
FOR EACH ROW
WHEN (OLD.track = 'original')
EXECUTE FUNCTION raise_mutation_error();
三轨模型的逻辑:
original:用户上传的,永远不可更改(信任合约)optimized:AI 对 original 的通用优化版本tailored:针对特定 JD 定制的版本(per-job)
每一条 bullet point 有一个稳定的 bullet_index,支持逐句对比编辑。这是「AI 帮你改简历」和「你知道 AI 改了哪里」之间的差距。
8.2 Agent Task 审计表
CREATE TABLE agent_tasks (
id uuid DEFAULT gen_random_uuid() PRIMARY KEY,
user_id uuid NOT NULL REFERENCES users(id),
agent_name text NOT NULL,
action text NOT NULL,
payload jsonb,
-- HITL 字段
hitl_action text,
hitl_payload jsonb,
hitl_decision text, -- 'approve' | 'reject' | 'modify'
decided_at timestamptz,
-- 成本追踪
cost_cents numeric(10,4),
tokens_in int,
tokens_out int,
-- 状态
status text DEFAULT 'pending',
error text,
started_at timestamptz DEFAULT now(),
ended_at timestamptz
);
这张表做了两件事:
- 审计日志:每个 Agent 操作都有记录,可追溯
- HITL 状态:
hitl_decision+decided_at记录用户对每个操作的审批结果
这让「为什么 Agent 做了这个操作」这个问题有了可靠的回答来源。
8.3 pgvector 语义匹配
-- jobs 表有 embedding 列
ALTER TABLE jobs ADD COLUMN embedding vector(1536);
CREATE INDEX jobs_embedding_idx ON jobs USING ivfflat (embedding vector_cosine_ops);
-- 匹配查询
SELECT j.*, 1 - (j.embedding <=> $1) as score
FROM jobs j
WHERE 1 - (j.embedding <=> $1) > 0.7
ORDER BY score DESC
LIMIT 20;
JobMatchAgent 在抓取新职位后生成 embedding,用余弦相似度做语义匹配。43 维匹配模型权重:技能(45%)+ 级别(25%)+ 地点(20%)+ 薪资(10%)。
纯向量搜索 + 加权评分的组合,比关键词匹配的召回率和精确率都高得多。
九、Harness 层:包在 LangGraph 之外的工程层
Relay 在 LangGraph 之外包了一层叫「Harness」的工程层,这是整个 Python Agent 端最体现生产思维的设计。
┌─────────────────────────────────────────────────┐
│ Relay Harness(业务逻辑层) │
│ • 成本追踪 + token 预算 │
│ • Loop Guards(防失控) │
│ • Context Window 管理(超限自动压缩) │
│ • 审计日志(async insert agent_tasks) │
│ • 权限系统(AUTO/NOTIFY/APPROVE/BLOCK) │
├─────────────────────────────────────────────────┤
│ LangGraph(底层引擎) │
│ • create_react_agent ReAct 循环 │
│ • StateGraph + interrupt HITL │
│ • PostgresSaver checkpointer │
└─────────────────────────────────────────────────┘
9.1 Loop Guards
Agent 系统最大的工程风险之一是「失控循环」——Agent 陷入死循环调用工具,直到 token 耗尽或账单爆炸。
Relay 的 Loop Guards:
GUARDS = {
"max_iterations": 20, # 超过 20 轮 → 强制总结后停止
"token_budget": 80_000, # 超过 80k token → 压缩历史
"cost_limit_cents": 50.0, # 超过 $0.50 → 暂停通知用户
"timeout_seconds": 300, # 超过 5 分钟 → 中止
"consecutive_errors": 3, # 连续 3 次错误 → 中止
}
max_iterations 通过 LangGraph 的 recursion_limit=40 实现(留出一倍余量),触发 GraphRecursionError 后由 Harness catch,生成摘要后优雅退出。
9.2 Context Window 压缩
当 session 的 token 用量超过 60k 时,自动压缩旧的对话历史:
async def compress_if_needed(state: CoordinatorState) -> CoordinatorState:
total_tokens = sum(count_tokens(m) for m in state["messages"])
if total_tokens < 60_000:
return state
messages = state["messages"]
recent = messages[-10:] # 保留最近 5 轮(每轮 user + assistant)
old = messages[:-10]
summary = await summarize(old) # V4Flash 压缩旧历史
return {
**state,
"messages": [SystemMessage(summary)] + recent,
}
这个设计让 Coordinator 可以维持非常长的会话(帮你找工作可能聊几周),而不会因为上下文窗口溢出而崩溃。
9.3 审计装饰器
@asynccontextmanager
async def audit(user_id: UUID, agent: str, action: str):
task_id = uuid4()
try:
yield
# 异步写入,不阻塞主流程
asyncio.create_task(
insert_agent_task(task_id, user_id, agent, action, "success")
)
except Exception as e:
asyncio.create_task(
insert_agent_task(task_id, user_id, agent, action, "error", error=str(e))
)
raise
# 用法
async with audit(user_id, "resume_agent", "parse"):
result = await parse_resume(raw_text)
asyncio.create_task() 是关键:写审计日志不阻塞主流程,但保证最终一致性写入。
十、客户端投递:核心差异化的架构设计
Relay 有一个被称为「核心差异化」的设计:投递发生在用户自己的浏览器里,不是在 Relay 的服务器上。
10.1 为什么不做服务器端自动投递
服务端自动投递(代为操作用户账号)有三个系统性风险:
- 封号:陌生 IP + 陌生设备指纹,ATS 很容易检测到
- 凭证安全:需要存储用户的 ATS 账号密码,这是安全噩梦
- CAPTCHA 军备竞赛:维护无限循环,永无止境
客户端执行从根本上绕过了这三个问题:用户自己的浏览器、自己的 IP、自己的已登录状态,平台无法区分「人工投递」和「AI 辅助投递」。
10.2 三层投递架构
第一层(约 70% 的字段):本地规则引擎
常见字段(name/email/phone/company/title)→ 直接映射,$0 成本
第二层(约 25% 的字段):云端 LLM 字段映射
POST /api/map-fields
in: { unknown_field: "current_compensation_type", user_profile }
out: { field → value }
成本约 $0.001 / job
第三层(约 5% 的字段):云端 LLM 开放题
POST /api/answer-q
in: { question, jd, resume }
out: personalized_answer
成本约 $0.002 / job
整体每次投递的 LLM 成本约 $0.003,$15/月订阅的毛利理论上接近 98%。
10.3 方案 B+:Playwright MCP Chrome Extension
更长远的设计是让服务端 Agent 通过 MCP 协议直接操作用户已登录的浏览器:
服务端 Agent (LangGraph) ←── MCP ──→ Playwright MCP Chrome Extension
├── 连接用户已登录的 ATS tab
├── accessibility snapshot(结构化 DOM)
├── 填充字段(用户可见)
└── 用户亲自点 Submit
Playwright 的 accessibility snapshot 把任意页面结构化为 Agent 可理解的树形表示,让 Agent 处理「从来没见过」的 ATS 表单。这是目前已知最优雅的「AI 填表」架构:浏览器端不需要写 DOM 操作代码,Agent 端不需要维护各个 ATS 的特定 Adapter。
十一、数据飞轮:越用越好的核心机制
Relay 的产品护城河不在单次体验,而在数据飞轮——系统随用户增长而变得更好的机制。
11.1 InterviewAgent 众包题库
用户 A 做了 Google L5 后端面试 → 记录题目 + 作答 + AI 评估
用户 B 也做了 Google L5 后端面试 → 系统推送「相关真题」
用户 C opt-in 众包 → 聚合洞察「Google L5 后端最常考的 10 题」
每增加一个用户,面试题库就变得更丰富。这是经典的网络效应——不是用于社交,而是用于知识积累。
11.2 事件驱动的跨 Agent 联动
简历更新 → 'resume:updated' 事件
↓
JobMatchAgent 订阅 → 重新计算所有未完成的职位匹配
↓
'job:matched' 事件 → 前端实时通知
职位抓取 → 'job:created' 事件
↓
JobMatchAgent → 找到匹配用户
↓
Notification Service → 推送消息
这种事件驱动的架构让 Agent 之间解耦——没有直接调用,只有事件订阅。每个 Agent 独立成长,也独立订阅自己关心的事件。
11.3 TrendAgent 个性化缺口
每天凌晨 2 点,TrendAgent 从职位数据中提取技能要求,和用户简历对比,生成个性化缺口报告:
「本周后端职位需求前 5:
Rust +34%(你当前简历:无)
Ray/分布式训练 +28%(你当前简历:有相关经验)
Graph RAG +22%(你当前简历:无)
...
建议:加一个 Rust 副项目的 bullet,可能让你多匹配 23 个岗位。」
这把趋势数据变成了可操作的个人建议,而不只是市场报告。
十二、给 Agent 工程师的设计清单
从 Relay 的架构中,我整理了几个可以直接用在自己项目里的设计决策点:
12.1 拆 Agent 的四个维度
在决定拆多少个 Agent 之前,先问这四个问题:
- 触发方式不同吗?(用户交互 vs cron vs 事件订阅)
- 模型分层需求冲突吗?(推理 vs 通用 vs 批量)
- 有独立成长的数据飞轮吗?
- Prompt 演化节奏不同吗?
任意一个是「是」,拆分就有合理依据。
12.2 HITL 的三个必要条件
HITL 不是加一个「确认按钮」那么简单,需要:
- 持久化 checkpointer:暂停状态必须能跨进程、跨时间恢复
- 展示足够的上下文:用户看到的不只是「批准/拒绝」,而是「Agent 想做什么、参数是什么」
- 支持修改:用户应该能在批准前修改参数
12.3 成本工程的三层
- 精算:追踪到 session 级别、每次 API 调用级别
- 分层:不同复杂度的任务用不同档位的模型
- 上限:给每个 session 设置成本天花板 + 动态降级
12.4 运行时验证优于 Prompt 约束
对于任何「AI 不应该做 X」的要求,先问:「有没有运行时验证来兜底?」
Prompt 约束是概率性的,运行时验证是确定性的。两者都用,但运行时验证才是最后一道防线。
12.5 审计日志是 Agent 系统的基础设施
不是调试功能,不是可选项:
- 每个 Agent 操作:记录什么时候做了什么、用了多少 token、花了多少钱
- 每个 HITL 决策:记录用户批准了什么、拒绝了什么、修改了什么
- 每个错误:记录触发了哪个 Guard、原因是什么
没有审计日志,Agent 系统就是一个黑盒,出了问题无法追溯。
十三、Relay 项目现状与开源价值
Relay 目前的完成度:
- 基础设施(数据库、Redis、MinIO):已完成
- TypeScript API 层:约 30%(端点存根 + 中间件完整)
- Next.js Web 层:约 35%(核心页面原型 + 设计系统完整)
- Python Agent 层:0%(架构设计完整,代码未启动)
- 浏览器扩展:0%
Agent 层的代码还没有动工——但设计文档极度完整。对于想深入理解多 Agent 系统架构的人,这反而是一个难得的机会:设计意图清晰,没有被历史实现细节污染。
项目地址:github.com/cubxxw/apply-agent
文档目录 docs/architecture/ 里有五个系统性架构文档,包括系统总览、Agent 架构、Harness 设计、客户端投递方案、数据模型。如果你在设计类似的 Agent 系统,这些文档值得认真读。
结语
Agent 工程目前最稀缺的不是智能,而是生产工程的积累:如何防失控、如何控成本、如何在 AI 犯错时有兜底、如何让用户对系统保持信任。
Relay 的架构选择——无论是 HITL 的 interrupt 设计、反虚构防卫的运行时验证、三层 LLM 路由、还是 Dual-Track 简历模型——每一个都是在回答一个具体的生产问题,而不是在追逐框架的新 feature。
这种「以生产问题驱动架构设计」的思维方式,是我认为这个项目最值得学习的地方。
这篇文章基于 Relay 项目的公开代码和架构文档写成。如果你在搭建 Agent 系统,欢迎来项目 repo 看看,也欢迎参与贡献。架构设计是开放的,代码是等着被写的。

读者回响