2024年1月6日大语言模型分享会
模型的局限:
- 深度学习
- 预训练模型
- 大语言模型
大语言模型的涌现能力:
Link:
大语言模型进化之谜:涌现现象的挑战与争议_AI_张俊林_InfoQ精选文章
大语言模型的特点趋势的转变:
大语言比人更懂人类的习惯。
- 使用 RLHF 训练
- 使用人类习惯的方式交互
大语言模型的发展脉络:
- 开源模型越来越多,比例越来越大。
- 预训练模型依旧是非常多的,但是微调的比例越来越高
如何学习大语言模型
- 模型结构的配置
- 大语言模型的微调
- 使用技巧
自己训练模型
不一定要只是单一的数据,也可以是数据的混合(包括自己提供的业务文档或者代码)
训练的数据来源:
当处理和准备用于机器学习模型训练的数据时,确保数据的质量、安全性、和去重非常重要。这里有一些关键步骤和方法,可以帮助你实现这一目标:
- 质量过滤(Quality Filtering):
- 确保数据准确无误:移除或修正任何错误的、不完整的或者是不准确的数据。
- 保证数据的一致性:确保所有的数据遵循同样的格式和标准。
- 数据去重(Data Deduplication):
- 识别和移除重复数据:使用算法或者工具来识别完全相同或高度相似的数据项,并将其合并或删除。
- 对于文本数据,可以使用哈希算法或者基于内容的去重方法。
- 隐私去除(Privacy Removal):
- 确保数据中不含有任何个人可识别信息(PII),如姓名、地址、电话号码等。
- 在某些情况下,可以使用数据脱敏技术,如匿名化或伪匿名化,来保护用户隐私。
- 分词(Tokenization):
- 对于文本数据,分词是将连续文本分割成更小单元(如单词、短语或字符)的过程。
- 分词的方法依赖于特定语言的语法和词汇结构。对于中文,可能需要特定的分词工具,因为中文是一个无空格分隔的语言。
解码器结构
“causal decoder"和"prefix decoder"是两种不同的解码器结构,它们在处理序列数据,尤其是在文本生成任务中扮演着重要角色。下面是这两种解码器的对比:
Causal Decoder (因果解码器)
- 定义和应用:
- 因果解码器,如在GPT系列模型中所使用的,是一种单向解码器。
- 它在生成文本时,仅考虑已经生成的或给定的前文(即,它只看到左侧的上下文)。
- 工作原理:
- 在处理每个新词时,因果解码器仅使用前面的词作为上下文。
- 这种模式模拟了人类自然语言的生成方式,即基于已知信息顺序地产生新信息。
- 用途:
- 适用于文本生成任务,如故事叙述、自动写作、聊天机器人等。
- 特点:
- 保证了生成的文本是连贯的,并且在逻辑上遵循了之前的上下文。
- 不能回看或考虑未来的词汇或句子结构。
Prefix Decoder (前缀解码器)
- 定义和应用:
- 前缀解码器是一种可以同时考虑前文和后文的解码器,类似于BERT中的masked language model(MLM)。
- 它在处理数据时,可以同时考虑序列中的前缀和后缀信息。
- 工作原理:
- 在处理每个词时,前缀解码器使用前面的词和后面的一些占位符或掩码作为上下文。
- 这种方式使得解码器在生成某个词时,可以考虑到整个序列的结构。
- 用途:
- 常用于需要双向上下文理解的任务,如文本填空、句子完善、语言模型训练等。
- 特点:
- 能够在生成文本时考虑到更全面的上下文信息。
- 更适合于理解整个句子或段落的结构和含义。
模型结构的优化
模型结构优化一直以来都是比较fancy的工作,优秀的模型结构设计,可以大大提高模型参数的效率,甚至小模型效果可以超过大模型。本文我们以XLNet、ALBERT、ELECTRA为例进行分析。虽然他们也可以认为是预训练任务优化和模型轻量化方面的工作,但鉴于模型结构创新力度很大,我们还是在模型结构优化这个版块来分析他们。
XLNet
- Github source code: ‣
微调
微调考虑的因素:
- 效果:定制化 — 本地知识库检索,特定领域问答等
- 成本:训练成本— 显卡等成本(美国现在限制了中国的显卡)
微调需要保留哪些数据?
(base) root@openim-System-Product-Name:/home/openim# nvidia-smi
Sat Jan 6 14:39:30 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 0% 33C P8 17W / 450W | 33MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 2960548 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 2960714 G /usr/bin/gnome-shell 10MiB |
+---------------------------------------------------------------------------------------+
ChatGpt 解析
(base) root@openim-System-Product-Name:/home/openim# nvidia-smi Sat Jan 6 14:39:30 2024 +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDA Version: 12.2 | | (NVIDIA系统管理界面版本) (显卡驱动版本) (CUDA版本) | +------------------------------------+----------------------+--------------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | (GPU编号和名称) (持久性模式状态) | (总线ID) (是否显示活动) | (未修正的易失性错误校验) | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | (风扇速度) (温度) (性能状态) (功率使用/上限) | (显存使用情况) | (GPU利用率) (计算模式) | | | | MIG M. | | | | (MIG模式状态) | +-----------------------------------------+----------------------+----------------------+ | 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off | | (GPU编号) (GPU型号) (持久性模式) | (总线ID) (显示活动) | (易失性错误校验) | | 0% 33C P8 17W / 450W | 33MiB / 24564MiB | 0% Default | | (风扇速度) (当前温度) (性能状态) (当前/最大功率) | (当前/总显存) | (GPU利用率) (计算模式) | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | (进程列表) | | GPU GI CI PID Type Process name GPU Memory | | (GPU编号) (GI) (CI) (进程ID) (类型) (进程名称) (GPU内存使用) | |=======================================================================================| | 0 N/A N/A 2960548 G /usr/lib/xorg/Xorg 9MiB | | (GPU编号) (N/A) (N/A) (进程ID) (图形进程) (进程名称) (显存使用) | | 0 N/A N/A 2960714 G /usr/bin/gnome-shell 10MiB | | (GPU编号) (N/A) (N/A) (进程ID) (图形进程) (进程名称) (显存使用) | +---------------------------------------------------------------------------------------+
微调-Adapter:
预训练模型每一层添加 Adapter 模块,微调时只更新 Adapter 的参数,Adapter 为 2 个线性层,现降维,后升维。对不同的任务微调。
Finetuning LLMs Efficiently with Adapters
微调-lora:
Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation)
微调-qlora:
相比较 lora:
LoRA and QLoRA- Effective methods to Fine-tune your LLMs in detail.
github:
GitHub - artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs
blog:
QLoRA: Efficient Finetuning of Quantized LLMs
LangChain-AI
https://github.com/langchain-ai/langchain
架构设计:

LangChain-Core 是最核心的功能
LangChain Hub:
langsmith 的 invite code 需要问其他人获取到,github issue 或者 mail
LangChain Chat:
AI Agent
尽管从比尔盖茨到OpenAI,大家都在谈AI Agent,但是它还没有一个确切的定义。目前,在行业内关于AI Agent达成的共识,主要来自OpenAI的一篇博文。它将AI Agent定义为:大语言模型作为大脑,Agent具备感知、记忆、规划和使用工具的能力,能够自动化实现用户复杂的目标,这其实也奠定了AI Agent的基本框架。
.png)
**面壁智能(ModelBest)**联合清华大学 NLP 实验室共同开发的大模型全流程自动化软件开发框架 OpenBME/ChatDev
https://github.com/OpenBMB/ChatDev
安装插件使用:
.png)
AI Agent 的经典项目:
https://github.com/Significant-Gravitas/AutoGPT
大模型构建问答系统
传统搜索系统基于关键字匹配,在面向:游戏攻略、技术图谱、知识库等业务场景时,缺少对用户问题理解和答案二次处理能力。
大语言模型(Large Language Model, LLM),通过其对自然语言理解和生成的能力,揣摩用户意图,并对原始知识点进行汇总、整合,生成更贴切的答案。关于基本思路,验证效果和扩展方向
大模型构建问答模型:
- 使用微调的方式(MedGPT, 医疗大模型,ChatMed)
- 使用微调结合外挂知识库的方式(法律大模型,ChatLaw)
- 借助通用大模型的能力,使用外挂知识库的方式。
优秀的开源项目:
https://github.com/chatchat-space/Langchain-Chatchat
https://github.com/MetaGLM/FinGLM
https://github.com/lm-sys/FastChat
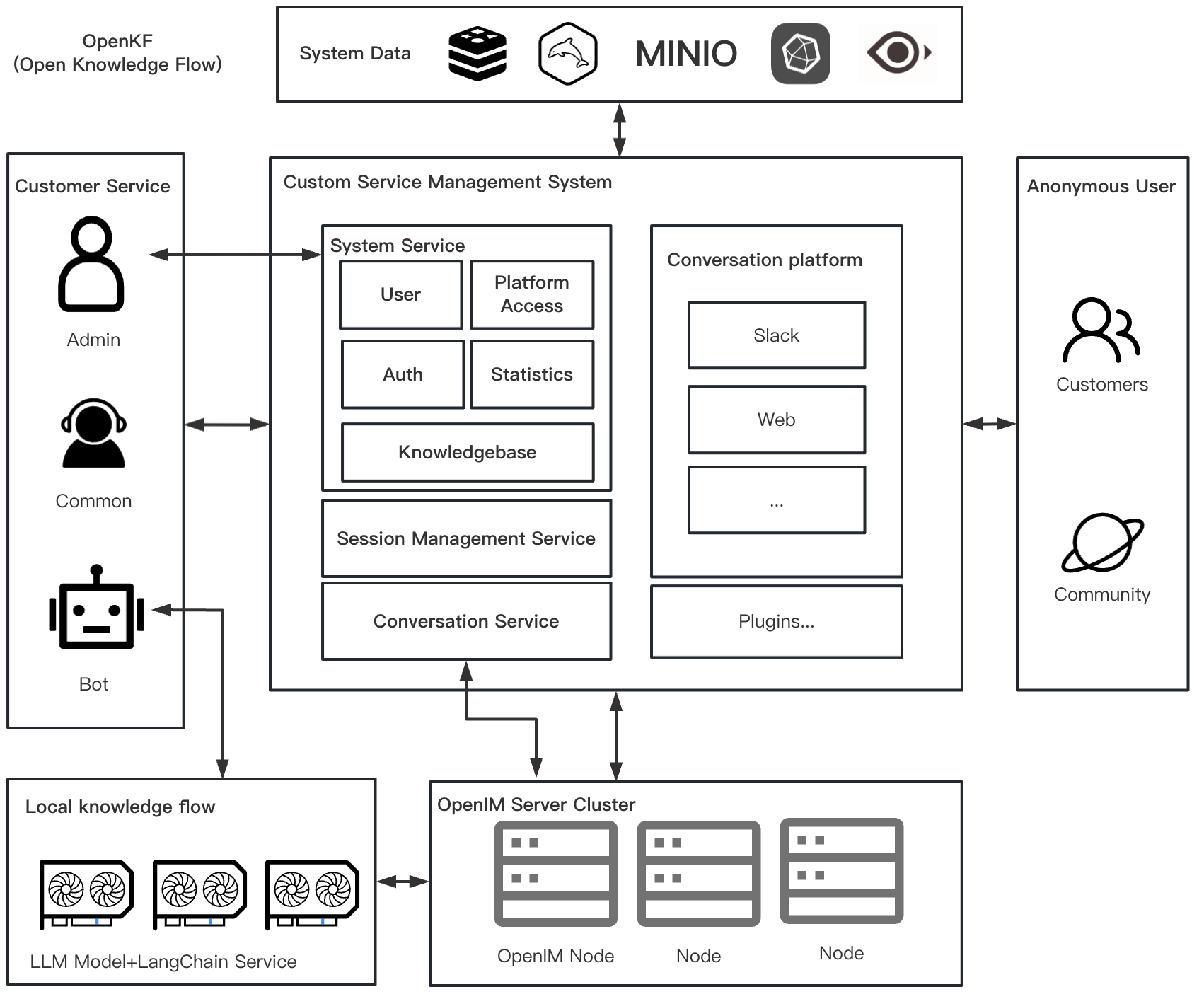
需求: 针对同类型的问答系统,类似于 OpenKF 项目 http://github.com/OpenIMSDK/openkf 实现的本地的一个知识库(底层的知识库 LLM 模型可以替换,甚至接入 API ):

打造 特定领域知识(Domain-specific Knowledge) 问答 系统,具体需求有:
- 通过自然语言问答的形式,和用户交互,同时支持中文和英文。
- 理解用户不同形式的问题,找到与之匹配的答案。可以对答案进行二次处理,比如将关联的多个知识点进行去重、汇总等。
- 支持上下文。有些问题可能比较复杂,或者原始知识不能覆盖,需要从历史会话中提取信息。
- 准确。不要出现似是而非或无意义的回答。(对于金融行业尤其重要)
有些问题也不一定要通过大模型来回答。针对部分的问题,比如说计算机相关的问题,带有推理的问题时,模型的输出容易存在问题,采用直接构建模版的方式进行回答,或者是 FAQ 问答系统
FAQ 问答系统项目: https://github.com/wzzzd/FAQ_system
{kind=link}
资源:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主,包括底座模型,垂直领域微调及应用,数据集与教程等。
https://github.com/HqWu-HITCS/Awesome-Chinese-LLM
FAQ
- 大语言模型下核心竞争力
- 大语言模型的训练数据(包括 code OR issue )
- 知识库的建设格式对精度的影响: 对数据解析没有规范的范式,定义的是问题的集合,然后从数据的构造上入手(切片和文档块)
- 召回率的问题: 记录问题以及召回答案一一对应;
- 大模型幻觉现象:对于不熟悉不确定问题不回答,从提示词上进行处理,返回召回
- 企业的多个知识库: 大模型如何选择指定的知识库来回答,采用大模型做微调和分类任务
- PDF 的特殊数据(图片)处理,以及冗余信息的处理