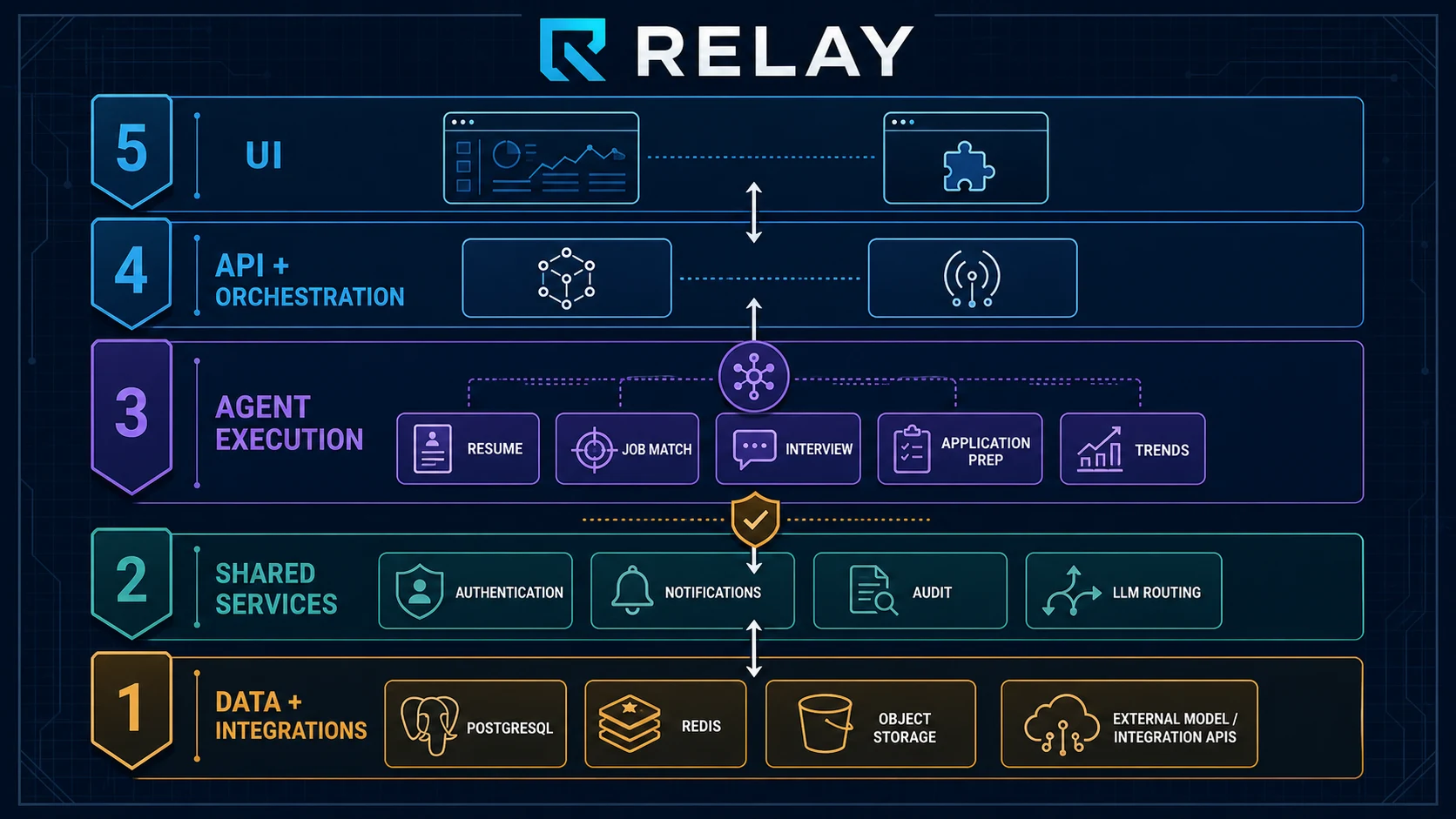
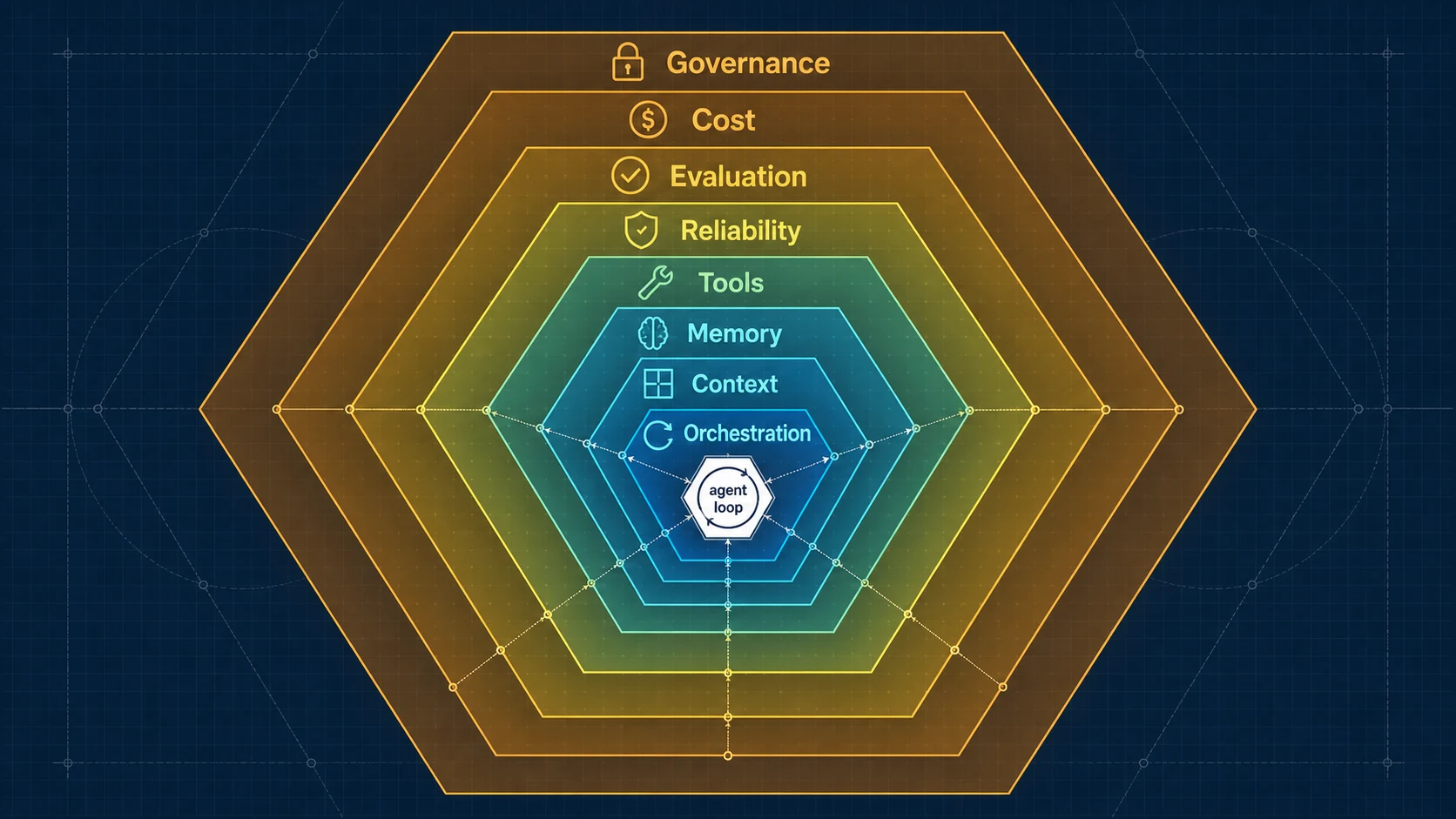
2026年3月思考笔记
2026 年 3 月思考笔记 本月共 468 条笔记 | 记录时间:2026 年 3 月 1 日 — 3 月 31 日 月度主题:吴哥窟 · AI Agent · 自我叙事 核心话题:格物/ai (约 53 条)、格物/柬埔寨 (约 38 条)、格物/吴哥窟 (约 23 条)、格物/印度教 (约 15 条)、观我 (约 14 条)、格物/越南 (约 11 条) 按日期归档 | Daily Notes Archive 2026-03-01 3月1日 周日 (29 条) 东北直给文化:劳动独立如何塑造不内耗的关系模式 2026-03-01 10:35:04 东北的女性地位是略强势的 尤其是辽吉黑,长期都是中国的重工业的基地 女性从很早开始就进入正式劳动体系(工厂、医院、学校、机关) 并且经济独立,有稳定的收入 双职工家庭都是常态 经济上平等,并且权力是在资源 + 组织能力手里 东北的语言文化气质本身就是直给、少内耗,不服就说的文化 所以情绪表达是正面输出的,不绕弯、不长期压抑、不靠冷暴力、冲突直接爆发、快速解决 男性的议价能力偏低,收入不优势,不强调家族光环 #格物/东北 ...