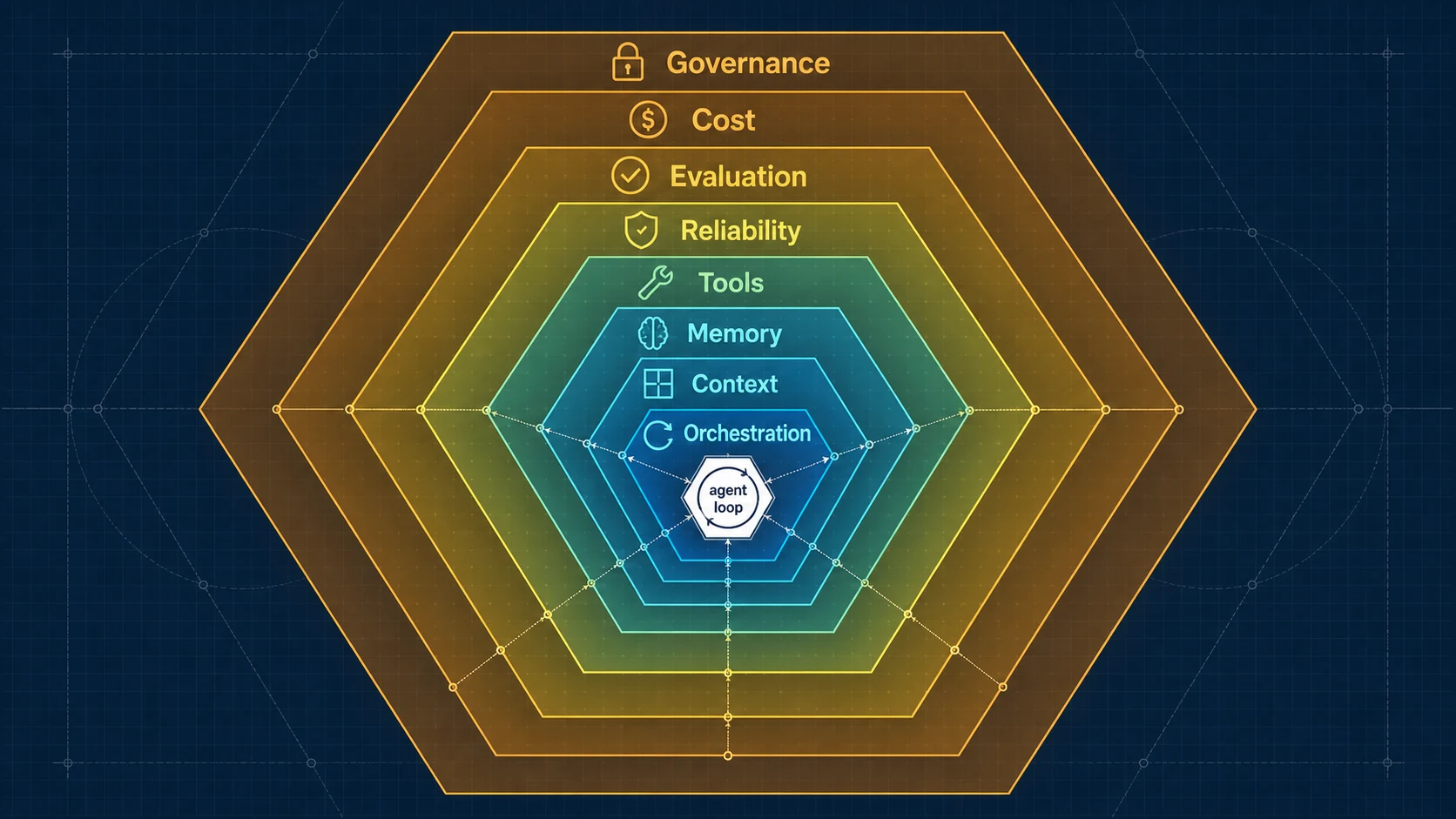
从零设计一个生产级 AI Agent 系统:Relay 求职 Agent 的架构全解
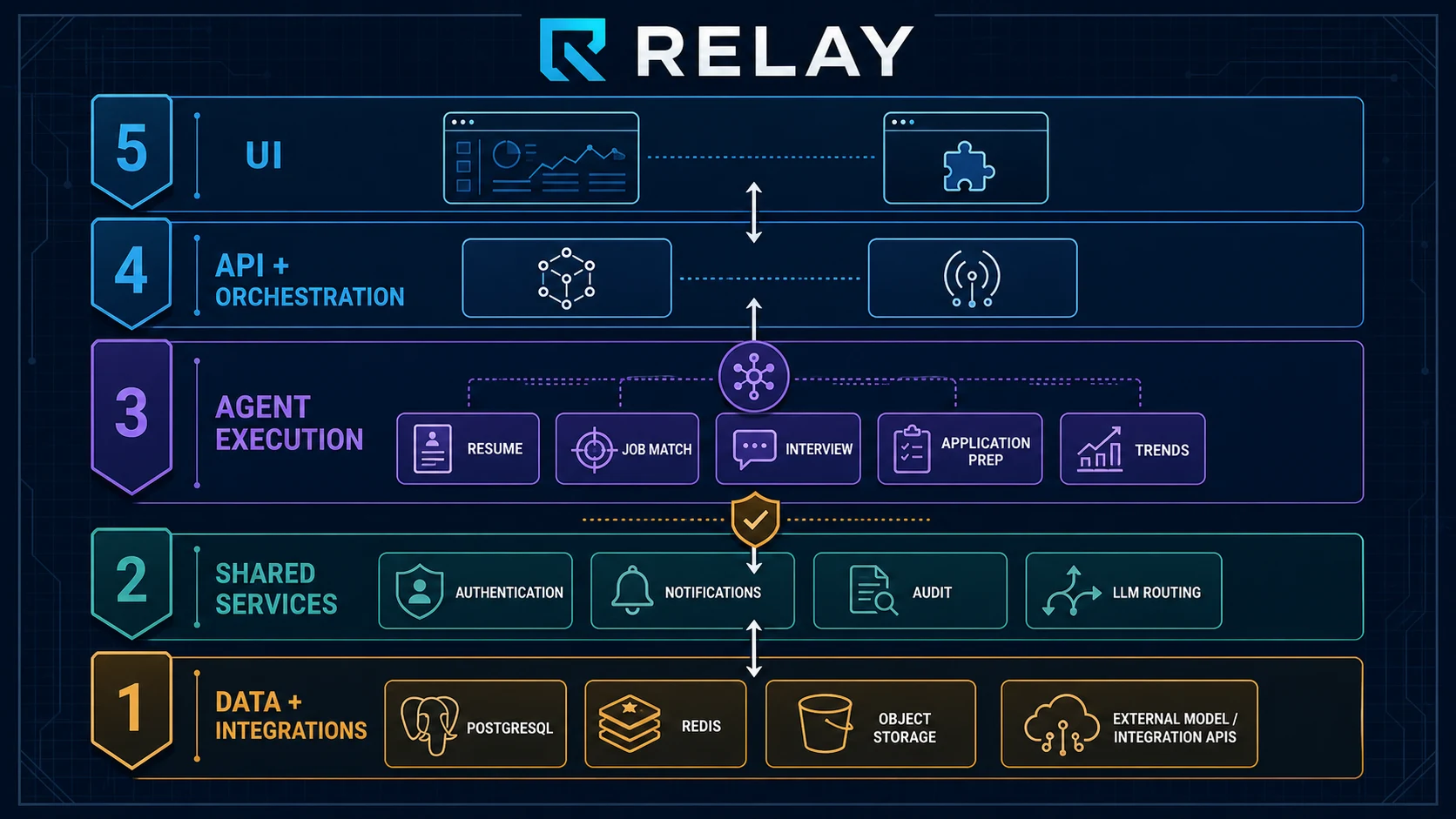
「绝大多数 Agent 项目死在 PoC 和生产之间的那段没有地图的荒野。」 这句话是我反复读 Relay 项目文档时自己写下来的。Relay 是一个开源的求职 AI Agent 系统——不是那种「3 行 LangChain 代码 + GPT-4」的演示,而是一个有完整架构文档、172 个工程任务、混合技术栈、并且对每个设计决策都给出了明确反例的项目。 它还没有完全跑起来。Agent 层的代码还在写。但这恰恰是我觉得值得写这篇文章的原因:这是一个在设计层面思考非常深的系统,而那些深度思考本身——无论这个项目最终走向何方——都是对所有在做 Agent 工程的人有价值的参考。 这篇文章不是产品介绍,是一次架构拆解。 一、问题背景:为什么求职场景特别适合做 Agent 系统 在聊架构之前,我想先回答一个更基础的问题:为什么求职是一个适合 Agent 而不只是 AI 工具的场景? 求职的本质是一条多阶段、多工具、高认知负担的工作流: 简历准备 → 职位搜索 → 简历定制 → 表单填写 → 投递追踪 ↑ ↓ └──────── 面试准备 ← 面试邀请 ←────────────────┘ 每个节点都需要大量「低价值的机械劳动」——搜索、复制、粘贴、调格式、填表单。同时,每个节点的「高价值判断」——这份职位适合我吗?这段经历该怎么呈现?这道面试题我应该怎么练?——都是高度个人化、依赖上下文的问题。 这正是 Agent 系统应该介入的地方:把机械劳动自动化,把高价值判断辅助化,把不可逆操作透明化。 Relay 的北极星是:「质量优先而非数量优先——精准的一发,胜过无脑的一百发。」 这个定位本身就决定了它的架构不能是「一键批量投递」,而必须是「每一份投递都经过用户确认」。 二、整体架构:五层设计 Relay 的架构分五层,从底向上依次是: ┌──────────────────────────────────────────────────────────┐ │ 第 5 层:UI 层 │ │ Next.js 16 Web 控制台 + Manifest V3 浏览器扩展 │ ├──────────────────────────────────────────────────────────┤ │ 第 4 层:API + 编排层 │ │ Hono/Bun TypeScript API + Redis Event Bus │ ├──────────────────────────────────────────────────────────┤ │ 第 3 层:Agent 执行层 │ │ Python FastAPI + LangGraph(5 个 domain agent) │ ├──────────────────────────────────────────────────────────┤ │ 第 2 层:共享服务 │ │ Auth、Notification、Audit、LLM Router │ ├──────────────────────────────────────────────────────────┤ │ 第 1 层:数据 + 外部集成 │ │ PostgreSQL + pgvector、Redis、MinIO、OpenRouter │ └──────────────────────────────────────────────────────────┘ 最核心的设计决策是混合后端:API 层用 TypeScript(Hono + Bun),Agent 层用 Python(FastAPI + LangGraph),两层通过 HTTP + Redis + 共享 PostgreSQL 连接。 ...